
Die innere Stimme des Rechners
Wir haben nun im letzten Kapitel gesehen, dass man mit technischen Mitteln eine Maschine dazu befähigen kann, mit
Zahlen zu rechnen. Was uns nun noch fehlt ist, wie wir eine Maschine dazu bekommen, Befehle auszuführen. Auch hier
sehen wir uns ein sehr vereinfachtes, aber gebräuchliches Konzept an. Gehen wir mal von einer sehr einfachen
Vorstellung eines Computers aus. Dieser hat erstmal zwei wichtige Komponenten – den Speicher, in den er alle
Daten ablegen kann und die CPU (Central Processing Unit), welche die Daten verarbeiten muss. Beginnen wir mit
dem Speicher. Dieser ist in einzelne „Zellen“ aufgeteilt, von denen jede Zelle eindeutig adressierbar ist. Dies
bedeutet, dass diese Zellen Adressen im Speicher haben, unter der wir Informationen ablegen und exakt dort
wiederfinden können. Diese Zelle als „kleinste adressierbare Einheit“ wird als „Byte“ bezeichnet. In den
allermeisten Systemen ist eine Zelle 8 Bit groß, wodurch ein Byte somit auch 8 Bit beträgt. Es gibt zwar
Möglichkeiten, diese Mechanik durch clustern von Bytes effizienter zu gestalten – für unser Verständnis genügt
aber die Vorstellung der 1:1 Adressierbarkeit von einem Byte. In diesem Byte können wir nun Zahlen ablegen.
Das ist jetzt nicht besonders spektakulär, zumal wir bei 8 Bit ja nur 28 Zustände,
also im einfachsten Fall die Dezimalwerte 0 bis 255 ablegen können – aber das ist durch das gemeinsame Nutzen von
Bytes problemlos zu umgehen. Bleiben wir aber vorerst beim Zahlenbereich von 0 bis 255. Gehen wir nun davon aus,
dass wir eine „32 Bit“ CPU haben (den Einfluss des Betriebssystems lassen wir erstmal außen vor). Somit kann
unsere CPU theoretisch 232 = 4.294.967.296 Bytes direkt adressieren, was wir verkürzt
mit 4 GByte(1) angeben würden.
(1) Eigentlich 4 GiByte entsprechend der Binärpräfixe (siehe https://de.wikipedia.org/wiki/Byte#Vergleichstabelle)

Maschinencode
Nun können wir die einzelnen Werte in den Speicherzellen als Zahlen interpretieren. Wollen wir beispielsweise einen
Zähler programmieren, dann brauchen wir eine Speicherzelle, in welcher wir uns den Zählerwert „merken“. Wir können
mit den Werten in den Speicherzellen aber auch was anderes machen. Wenn wir jeder Computeroperation, welche auf dem
Prozessor fest eingebaut ist, einen Wert zuweisen, dann können wir auch Programme im Speicher ablegen. „Erfinden“
wir doch einfach mal einen Prozessor mit eigenen Befehlen und sehen, wie es auf eine sehr vereinfachte Weise machbar
ist diesen zu programmieren. Als erstes benötigen wir einen zentralen Ort, in dem wir die einzelnen Anweisungen wie
multiplizieren, addieren etc. durchführen. Dieser zentrale Ort ist das sogenannte „Arbeitsregister“, manchmal auch
„Akkumulator“ genannt. Immer, wenn wir Daten verarbeiten wollen, müssen sie in dieses Register geladen werden. Der
Grund liegt darin, dass wir am Ende die Operationen ja irgendwie als Schaltung im Prozessor hinterlegen müssen. Die
Ein- und Ausgänge der Operationen müssen auch irgendwo „angeschlossen“ werden und das ist das zentrale Arbeitsregister.
Neben diesem Register würden wir noch weitere benötigen bspw. Adressregister, Programmzähler etc., aber für unser
Verständnis reicht erst mal das Arbeitsregister. Sehen wir uns nun mal ein paar mögliche Programmierbefehle für
unseren "selbst erfundenen" Prozessor an:
| Befehl: | Beschreibung | Code:(2) |
|---|---|---|
| Lade ADR | Der Inhalt der angegebenen Speicheradresse wird in das Arbeitsregister geladen. | 0x01 |
| Schreibe ADR | Der Inhalt des Arbeitsregisters wird in die angegebene Speicheradresse geschrieben. | 0x02 |
| Addiere ADR | Der Inhalt der angegebenen Speicheradresse wird zum Inhalt des Arbeitsregisters hinzuaddiert und in das Arbeitsregister geschrieben. | 0x03 |
| Subtrahiere ADR | Der Inhalt der angegebenen Speicheradresse wird vom Inhalt des Arbeitsregisters abgezogen und in das Arbeitsregister geschrieben. | 0x04 |
| Multipliziere ADR | Der Inhalt der angegebenen Speicheradresse wird mit Inhalt des Arbeitsregisters multipliziert und in das Arbeitsregister geschrieben. | 0x05 |
| Dividiere ADR | Der Inhalt der angegebenen Speicheradresse wird durch den Inhalt des Arbeitsregisters dividiert und in das Arbeitsregister geschrieben. | 0x06 |
| Springe auf ADR | Setze den Programmzähler auf die angegebene Speicheradresse. | 0x07 |
| Prüfe ADR | Prüfe den Wert in der angegebenen Speicheradresse auf 0. Wenn dort die 0 steht, dann überspringe den nächsten Befehl. | 0x08 |
| ENDE | Ende des Programms. | 0x09 |
Tabelle 1: Fiktiver Befehlssatz des "erfundenen" Prozessors
(2) Diese Codes wurden willkürlich von mir gewählt. In realen Prozessoren finden wir hier abweichende Codes
Reale Prozessoren haben zwar sehr viel mehr Befehle, aber es geht uns ja nur um das Prinzip. Nun wollen wir auf
unserem fiktiven Prozessor ein Programm erstellen. Da wir uns nur um die Grundidee und nicht um die etwas
komplizierteren Ein/Ausgabefunktionen kümmern wollen, erstellen wir erstmal nur ein Programm, welches eigentlich
keinen wirklichen Nutzen für den Enduser bringt. Sagen wir, es soll der Wert in einer Speicheradresse von 5 auf 0
runtergezählt werden – also ein Rückwärtszähler soll entstehen. Zähler benötigen im Wesentlichen folgende Informationen:
- Was ist der aktuelle Zäherstand?
- Mit welchem Wert fängt der Zähler an?
- Mit welcher Schrittweite soll der Zähler zählen?
- Mit welchem Wert hört der Zähler auf?
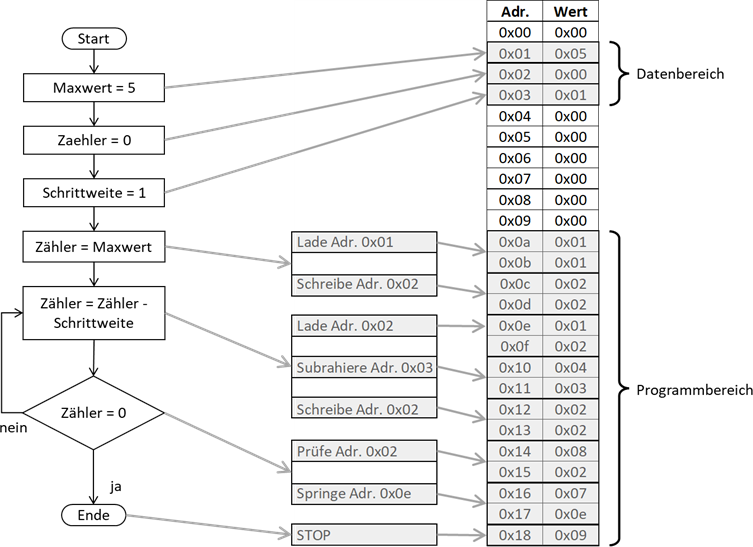
Abb.: 1: Algorithmus als PAP und als Computerprogramm
Neben dem PAP habe ich nun die Befehle als „Klartext“ – man spricht hier von mnemonischen Befehlen (ja, das schreibt
man wirklich so!) – geschrieben. Bis auf die Belegung der Variablen und Konstanten finden wir hier den Algorithmus
wieder (die Variablen und Konstanten liegen bereits in den Speicheradressen 0x01 bis 0x03). Wie wir sehen, wirkt
das Ganze recht umständlich – aber wir dürfen nicht vergessen, dass wir hier auf Maschinenebene agieren. Sehen wir
uns einfach mal den Punkt „Zähler = Maxwert“ an. Hierfür brauchen wir zwei Befehle. Wir laden den Datenwert aus der
Adresse von der Maxwert Konstante (das wäre bei uns die Speicheradresse 0x01) mit dem Befehl „Lade Adr. 0x01“ in
das Arbeitsregister. Dann schreiben wir den Inhalt des Arbeitsregisters in die Adresse der Zählvariablen, also dort
wo wir den Zählerwert ablegen wollen (Schreibe Adr. 0x02). Die Subtraktion sieht da nicht wirklich übersichtlicher
aus. Wir laden den Zähler, ziehen die Schrittweite (aus Adr. 0x03) ab und schreiben das Ergebnis in die Zählvariable
zurück. Danach prüfen wir, ob in der Zählvariablen der Wert 0 existiert und wenn nein, springen wir wieder zur
Subtraktion zurück.
Neben dem mnemonischen Befehlen habe ich noch ein modellhaftes Speicherabbild eingefügt. Es soll lediglich eine
Idee darüber vermitteln, was im Speicher passiert. Über Speicherverwaltung sprechen wir später nochmal etwas genauer.
In unserem Modellspeicher fallen uns erstmal zwei Dinge auf. Erstens befinden sich die Daten und die Programme im
gleichen Speicher – zwar in verschiedenen Adressbereichen, aber im gleichen Speicher(3).
Weiterhin belegen viele Befehle gleich zwei Speicherzellen, da wir neben dem Befehl auch die zugehörige Adresse
speichern müssen. Der Einfachheit halber habe ich unseren Prozessor „nur“ mit einer Adressbreite von 8 Bit
(also einem Byte) ausgestattet. Bei 64 Bit Architekturen würde ein Befehl entsprechend mehr Platz benötigen, da
der Teil der Adressierung dann 8 Bytes benötigen würde. Hier gibt es auch noch zwei verschiedene Arten, wie die
Bytes aneinandergereiht werden. Bei der sogenannten „Big Endian“ Codierung werden die Bytes von der höher- in Richtung
niederwertigeren Bytes sortiert – so wie wir es aus unserem gewohnten Zahlenbereich auch erwarten würden. Die
Hexzahl 0x1234 würde also auf der ersten Speicherzelle 0x12 und auf der nächsthöheren 0x34 belegen. Die „Little
Endian“ Codierung macht das genau umgekehrt – es würde also zuerst die 0x34 und dann die 0x12 stehen. Dieses Wissen
ist vor allem dann wichtig, wenn man programmatisch auf Byteströme zugreift und wissen muss, welche der beiden
Codierungen verwendet wird.
(3) Solche Prozessorarchitekturen nennt man auch „von Neumann Architektur“ und dies sind auch die gebräuchlichsten.
Hochsprache
Was heißt das jetzt für uns? Erst einmal, dass aufgrund der „Beschränktheit“ von Computern auf Zahlen der Code, den
die Maschinen ausführen (der sogenannte „Maschinencode“), alles andere als übersichtlich ist. Wir können diesen
Code mit mnemonischen Befehlen etwas griffiger gestalten, wodurch wir Maschinencode selbst schreiben können. Diese
sogenannten „Assemblerprogramme“ können aber nur von Spezialisten erstellt werden. Also nichts für uns
Programmieranfänger. Wie schaffen wir es also nun, Programme in einer für uns verständlichen Programmiersprache zu
erstellen, welche aber trotzdem von einer CPU abgearbeitet werden kann? Nehmen wir beispielsweise die Programmiersprache
C und programmieren den Algorithmus nach:
Listing 1: Zähler in C
Zugegebenermaßen ist das Programm ziemlich sinnlos, da wir ja keinerlei Ausgaben haben. Es geht uns hier aber erst
einmal nur darum, den (genauso sinnlosen) Maschinencode als „normales“ Programm zu erzeugen. Wenn wir nun den
C-Code mit dem Assemblercode vergleichen, sehen wir nur noch wenige strukturelle Gemeinsamkeiten. Trotzdem können
wir in beiden Codes den Algorithmus irgendwie wiedererkennen. Wir können in Maschinensprache die Anweisungen Schritt
für Schritt nachvollziehen und somit verstehen, was da eigentlich passiert. Im C-Code fällt uns dies sehr viel
leichter. Wir erkennen die Speicherplätze, welche mit Konstanten Werten belegt wurden und haben darüber hinaus diesen
Speicherplätzen noch sinnvolle Namen gegeben:
Listing 2: Konstantendefinition in C
Dann erzeugen wir eine Variable, welche den Zähler aufnehmen soll:
Listing 3: Variablendeklartion und Initialisierung in C
Der eigentliche Algorithmus ist in einem eigenen Codebereich hinterlegt, in der wir die Zuweisung des Maximalwertes
auf unseren Zähler wiedererkennen und eine Struktur, welche die Wiederholung des Zählvorganges darstellt, solange
(also „while“) der Zähler ungleich 0 ist. Auch die Reduktion des Zählers um die Schrittweite können wir ausmachen:
Listing 4: Zählprogramm in C
Wir haben also sowohl im Maschinencode, als auch im C-Code die gleiche Funktionalität in zwei unterschiedlichen
„Sprachen“ formuliert. Beides in einer sehr formalen Struktur. Was uns jetzt eigentlich nur noch fehlt ist ein
Übersetzer, der uns das Programm aus der C-Sprache in die Maschinensprache übersetzt. Da der C-Code formalen
Sprachregeln – den sogenannten „Syntaxregeln“ – folgt, kann man Programme realisieren, welche genau diese Übersetzung
vornehmen. Diese Programme nennt man „Compiler“. Ein Compiler ist also ein Programm, welches Programmcode einer
sogenannten „Hochsprache“ in Code übersetzt, der von einem Prozessor ausgeführt werden kann - dem Maschinencode.
Die Hochsprache wäre der sogenannte „Quellcode“ und die Maschinensprache dann der „Zielcode“. Bei Prozessoren,
welche kein Betriebssystem benötigen – beispielsweise den Microcontrollern wie Arduino, kompilieren wir in der Tat
1:1 für diese Hardware, wodurch wir den Compiler immer auf das Zielsystem einstellen müssen. Unterschiedliche
Prozessoren haben auch unterschiedliche Befehlssätze oder auch unterschiedliche Zahlencodes für die einzelnen
Maschinenbefehle. Dies muss der Compiler wissen.
Bei Systemen, welche ein Betriebssystem benötigen – wie
beispielsweise unserem PC oder auch dem Raspberry Pi – reicht es nicht, dass der Compiler den Code „nur“ für
den Prozessor übersetzt. Er muss auch noch den Anforderungen des Betriebssystems genügen, da das Betriebssystem
zwischen dem Prozessor und dem Programm liegt und bspw. die Ressourcen wie Speicherplatz und Prozessornutzung
kontrolliert. Dadurch sind diese Systeme bspw. auch in der Lage, mehrere Programme parallel abzuarbeiten.
Die Prozessoren für unsere PCs sind zudem erfreulicherweise „normiert“, sodass wir bei der Compilerauswahl
meist nur wissen müssen, für welches Betriebssystem das Programm kompiliert werden muss. In allen Fällen bezeichnen
wir Code, der auf ein bestimmtes System kompiliert wurde als „nativ kompiliert“ und das Kompilierergebnis bezeichnet
man oft als „Binärcode“. Die bekanntesten Vertreter von solchen Programmiersprachen sind C oder C++.
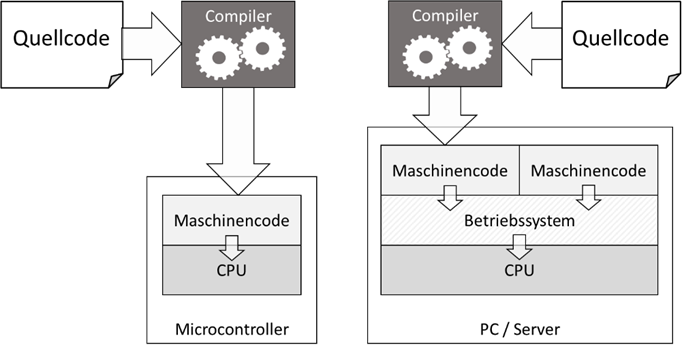
Abb.: 2: Maschinencode für Systeme mit / ohne Betriebssystem
Die allermeisten Compiler versuchen zusätzlich noch, den Code so weit zu optimieren, dass er möglichst effizient auf
den Zielsystemen ausgeführt werden kann. Dies hat mitunter zur Folge, dass erwartete zeitliche Verhaltensweisen
unseres Codes am Ende auf dem ausführenden System nicht eintreten, da der Compiler einen „schlaueren“ Weg gefunden
hat, den Algorithmus zu lösen.
Somit haben wir nun schon zwei Klassen von Programmiersprachen kennen gelernt:
- Maschinensprache
- Nativ kompilierte Programmiersprachen
Listing 5: Zählprogramm in C mit Ausgabe
Im Wesentlichen habe ich lediglich dem Compiler mitgeteilt, wo er die Funktionalität für die Ausgabe findet (in
stdio.h) und dass er den Zählerstand auf je einer neuen Zeile auf der Konsole
ausgeben soll (printf("\n%d", zaehler);).
Wenn wir nun diesen Inhalt in ein File – sagen wir mal
MeinZaehler.c – eingeben, dann haben wir „nur“ den Quellcode erstellt. Wir müssen jetzt dem Compiler mitteilen, dass
er dies kompilieren muss. Dies kann mit verschiedenen Compilern erledigt werden, ich nutze auf meinem Windows Rechner
den kostenfreien GNU Compiler(4). Hierfür lautet der Kompilebefehl:
(4) Die Installation wird im Kapitel XX. : VSCode - C/C++ beschrieben.
Diesen müssen wir natürlich in dem Ordner ausführen, wo unser
MeinZaehler.c File liegt. Wenn wir alles richtig gemacht haben, sehen wir in diesem Ordner ein neues File, nämlich
„MeinZaehler.exe“ – die ausführbare Datei. Starten wir dies nun in einer Konsole, so sehen wir die folgende Ausgabe:
Da wir aber VSCode als IDE (Integrated Development Environment) nutzen wollen, gibt es – die richtige Vorbereitung
vorausgesetzt – die Möglichkeit, einfach nur den „Startbutton“ oben rechts zu drücken und die IDE kümmert sich um den Rest:
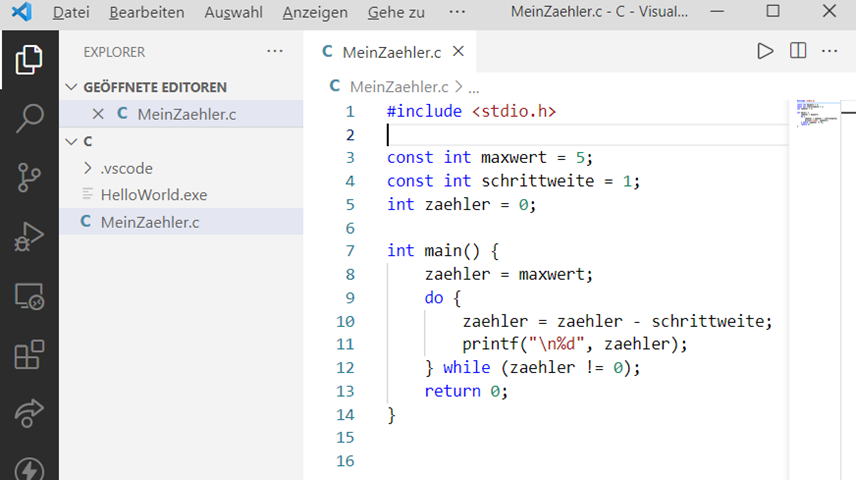
Abb.: 3: VSCode zur Erstellung und Kompilierung von C Code
Interpretierte Sprachen
Der ein- oder andere wird sich jetzt aber fragen: „Warum haben wir für unser Testprogramm aus dem
Kapitel XX eigentlich keinen Compiler gebraucht?“. Wir haben
ja ein offensichtlich lauffähiges Programm in JavaScript geschrieben und nichts übersetzen müssen! Der Grund ist,
dass es noch mehr Klassen von Programmiersprachen gibt. Unser JavaScript Programm zählt nämlich zu den sogenannten
„interpretierten“ Programmiersprachen.
Interpretierte Programmiersprachen, auch „Skriptsprachen“ genannt, benötigen keinen Compiler, um lauffähig zu werden.
Sie können 1:1 so laufen, wie sie geschrieben wurden. Was sie aber trotzdem benötigen ist einen Interpreter. Das ist
ein Programm, welches in der Lage ist, unseren Skriptcode zu lesen und zu interpretieren. Die einzelnen Anweisungen
werden dann vom Interpreter an das System weitergegeben und entsprechend ausgeführt:
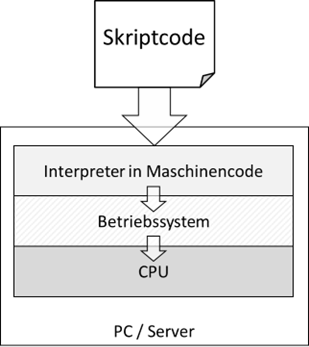
Abb.: 4: Ausführung von Skriptcode
In unserem Beispiel aus
Kapitel XX
war der Interpreter im Browser eingebaut. Dieser hat unseren Code gelesen und ausgeführt. Da fast alle von uns
genutzten Computer einen Browser bereits installiert haben, mussten wir uns um die Installation des Interpreters
keine Gedanken machen, sofern wir JavaScript im Rahmen von HMTL nutzen. Skriptsprachen gibt es wie Sand am Meer.
Sie werden in allen möglichen Programmen direkt interpretiert – bspw. Visual Basic in den Microsoft© Office Produkten
oder Python in vielen kostenlosen Anwendungen wie GIMP oder Blender. Jedes Betriebssystem liefert Möglichkeiten,
Systembefehle in Skripten sequenziell zu verarbeiten – bspw. die Bash Skripte in Linux oder Skripte innerhalb der
PowerShell von Windows. Ein großer Vorteil von Skriptsprachen ist, dass wir uns beim Programmieren über das
Betriebssystem (und streng genommen auch über den Prozessortyp) keinerlei Gedanken machen müssen. Solange wir
einen Interpreter finden, der auf dem gewählten System installierbar ist, kann unser Programm dort laufen.
Jetzt stellt sich die Frage, warum man überhaupt noch den umständlichen Weg über den Compiler geht. Die Antwort ist
denkbar einfach. Je mehr Systeme und Programme an der Ausführung des Codes beteiligt sind, umso höher ist der Overhead,
also die Aktionen, welche nichts mit dem eigentlichen Programm zu tun haben, sondern für administrative Zwecke benötigt
werden. Dadurch wird die Ausführung langsamer. Das mag bei vielen Anwendungsfällen keine große Rolle spielen, zumal die
Computer immer schneller werden. Bei zeitkritischen Programmen oder kleineren, schlanken Systemen sieht das schon wieder
anders aus. In gewissen Grenzen mag diese Argumentation jetzt verwundern. Ein erheblicher Teil der Serverapplikationen
für den Betrieb von Internetseiten wird serverseitig mit PHP (PHP: Hypertext Preprocessor(5) ) realisiert
und das ist wiederum eine Skriptsprache. Server jedoch gehören zu den Systemen, bei denen Performance (neben Sicherheit
und Zuverlässigkeit) an oberster Stelle steht. Also wie passt das zusammen? Zum einen spricht die Flexibilität bei der
Wartung des Codes eine Rolle. Einzelne Skriptfiles können relativ schnell ausgetauscht werden. Bei kompilierten Strukturen
ist das schon mit einem höheren Aufwand verbunden, da der Compileroutput meist in größeren Blöcken zusammengefasst wird,
wodurch der Prozess des „Deployments“, also des Verteilens der Software auf die entsprechenden Maschinen, verkompliziert
wird. Firmen mit großen IT-Abteilungen, welche diesen Prozess perfektioniert haben, neigen oft dazu serverseitig Lösungen
ohne Skriptsprachen zu verwenden. Kleinere und mittlere Firmen bevorzugen die einfacheren Lösungen, was die große
Verbreitung von PHP erklärt.
(5) Früher „Personal Home Page“, was aber die aktuelle Realität nicht richtig reflektiert, deshalb die Umbenennung
Neben PHP gibt es noch ein weitere Serverlösung, welche skriptbasiert ist – node.js. Wie die Extension „js“ schon
vermuten lässt, handelt es sich hier um einen JavaScript Interpreter, bzw. eigentlich JavaScript „Runtime Engine(6)“,
welche basierend auf dem Interpreter von Google Chrome erstellt wurde. Eine Besonderheit ist hier der „just in time
Compiler“, kurz JIT Compiler genannt (welcher inzwischen auch in PHP eingebaut wurde). Dieser kompiliert zur Laufzeit
Fragmente des Codes in Maschinencode und führt ihn dann aus. Dadurch erreicht man Verarbeitungszeiten, welche durchaus
mit nativ kompiliertem Code vergleichbar sind:
(6) „Runtime Engine“ ist das Gesamtkonstrukt – sprich das „Rahmen-“ Programm mitsamt Interpreter
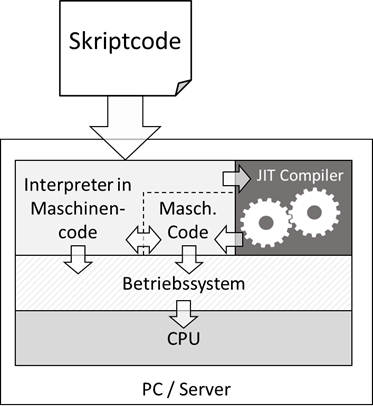
Abb.: 5: Skriptausführung mit JIT Compiler
Die Frage ist, ob wir nun alle Konzepte, Code auf einem Computer auszuführen abgehakt haben – und die Antwort ist
„nein“! Es gibt noch eine sehr wichtige Kategorie von Programmiersprachen, und zwar solche die kompiliert werden und
das Compilerergebnis trotzdem von einem Interpreter ausgeführt wird. Diese Kategorie liegt also technologisch zwischen
nativ kompilierten Sprachen und den Skriptsprachen. Die bedeutendsten Vertreter dieses Konzepts sind Java und die
Programmiersprachen des .NET Frameworks. Die Idee ist, dass man den Code nicht direkt interpretiert, sondern mit Hilfe
eines Compilers so optimiert, dass er von einer „virtuellen Maschine“ kurz VM ausgeführt werden kann. Unter einer
virtuellen Maschine versteht man in erster Linie eine Software, welche einen Computer bzw. einen Prozessor emuliert –
sie verhält sich also wie ein Computer oder ein Prozessor. Einem auszuführenden Programm ist es erstmal egal, ob es
auf einer Hardware läuft, oder auf einer Software, die nur so tut als wäre sie eine Hardware. Aus Sicht unseres
Programms gibt es keine Hardware oder Software, sondern nur Schnittstellen nach außen. Wer diese Schnittstellen
bedient ist nicht wichtig. Die so kompilierten Programme liegen also in einer Art „Zwischensprache“ vor, es ist kein
Quellcode aber auch kein Binärcode, weshalb man ihn mitunter als „Bytecode“ bezeichnet. Dieser ähnelt aber strukturell
eher Assembler als einem Skriptcode. Ein Blick auf Architekturkonzept zeigt, dass das Konzept trotzdem sehr ähnlich
dem Skriptansatz ist.
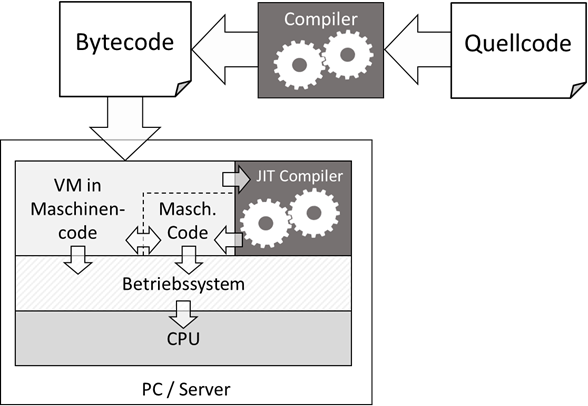
Abb.: 6: Abarbeitung von Bytecode durch virtuelle Maschinen
Nicht alle Konzepte haben neben der Virtuellen Maschine noch einen JIT Compiler, die wichtigsten wie Java und .Net
jedoch schon. Bei beiden Technologien kommt es sehr stark auf Performance an, weshalb ein partiell nativ laufender
Code unumgänglich ist. Die Vorteile dieses Gesamtkonzepts liegen auf der Hand:
- Weitgehende Unabhängigkeit des Codes vom darunterliegenden System, ähnlich wie bei Skriptsprachen.
- Sehr gute Skalierbarkeit, da virtuelle Maschinen unabhängig von der Hardware den auszuführenden Code verteilen können.
- Vergleichsweise hohe Performance.
- Zumindest im .NET Bereich kann der Bytecode (Microsoft nennt das Compilerergebnis auch „Common Intermediate Language(7)“) aus verschiedenen Programmiersprachen kompiliert werden. Die wichtigste Programmiersprache ist zwar C#, es ist aber auch möglich eine Microsoft spezifische Java Version zu nutzen oder auch Visual Basic.
(7) Offener Standard, Microsoft hat aber die Common Intermediate Language maßgeblich mitgestaltet

CC Lizenz (BY NC SA)