
Zusammengesetzte Wahrheiten
Spätestens beim
„char“ Datentyp, der ja „nur“ ein Zeichen speichern kann, sollte jedem klar geworden sein, dass wir mit den primitiven Datentypen
auf Dauer nicht auskommen werden. Wir brauchen erweiterte Strukturen, um beispielsweise Text abspeichern zu können. Auch größere
Zahlenkolonnen müssen wir in einer Art Listen ablegen können, damit eine einfache Verarbeitung ermöglicht wird. Man muss also in der
Lage sein, mehrere primitive Informationsträger zu einer neuen Einheit zusammenzufassen. Gehen wir mal davon aus, dass wir die
Arbeitsstunden einer Woche in einem Computer ablegen wollen. Eine – wenn auch keine sehr elegante – Möglichkeit wäre, einfach die
Stunden pro Tag in einer eigenen Variablen abzulegen:
Listing 1: Einzelbelegung von mehreren Zahlenwerten
Das funktioniert zwar, allerdings würde nun die Aufsummierung dieser Zahlen recht umständlich sein:
Listing 2: Aufsummierung von Einzelwerten
Wenn wir das Beispiel nun von Wochentagen auf Monatstage erweitern würden, wäre die Summierung äußerst unangenehm zu realisieren.
Dieses Vorgehen können wir uns so vorstellen, dass wir fünf einzelne Zettel hätten, auf denen jeweils die Arbeitszeit dieses Tages
stehen würde. Niemand mit Ordnungssinn würde auf die Idee kommen, seine Stunden auf solchen einzelnen Zetteln zu notieren, sondern
stattdessen einen Zettel nehmen und dort eine Art Tabelle aufmalen:
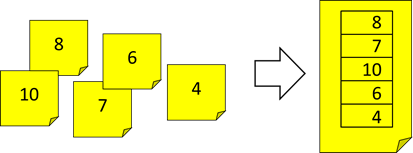
Abb.: 1: Unstrukturierte vs. strukturierte Datensammlung

Arrays in C
Für Programme gilt das gleiche. Wir wollen viele zusammengehörige gleichartige Informationen auch in einem einzelnen Konstrukt abspeichern.
Dadurch können wir sie auch einheitlich (beispielsweise mit Wiederholungsschleifen) verarbeiten. Hierfür nutzen wir sogenannte „Arrays“.
Einem Array müssen wir nun zwei Dinge mitgeben. Erstens, welche Art von gleichartigen Daten wollen wir ablegen und zweitens, wie viele davon.
Genau wie bei den primitiven Datentypen auch, müssen wir Arrays in einer Variablen ablegen. Sehen wir uns das Ganze mal im Code an. Da wir
jetzt in speziellere Sphären der Computersprachen abtauchen, müssen wir auch etwas genauer die Unterschiede zwischen den Programmiersprachen
beachten. Doch zuerst noch ein kleiner Hinweis – wir bewegen uns für die nächsten Erklärungen im Bereich der kompilierten, statisch typisierten(1)
Programmiersprachen. Hierbei konzentriere ich mich jetzt auf die Programmiersprachen C (C++(2)), C# und Java.
Skriptsprachen, welche meist dynamisch typisieren, zeigen bei genauerer Betrachtung ein anderes Verhalten bezüglich Variablen – doch davon
später. Beginnen wir zuerst mit der reinen Deklaration eines int Arrays mit 5 möglichen Einträgen in der Sprache C:
(1) „Statisch typisiert“ bedeutet, dass beim Schreiben des Codes der Datentyp festgelegt wird.
(2) Da C++ „lediglich“ eine objektorientierte Erweiterung von C ist, verhält sich C++ bezüglich Arrays wie C.
(2) Da C++ „lediglich“ eine objektorientierte Erweiterung von C ist, verhält sich C++ bezüglich Arrays wie C.
Listing 3: Deklaration eines int Arrays in C
Die Variable
zahlenArray beinhaltet jetzt das Array, welches wieder irgendwelche Zufallsdaten aus dem Speicher enthält. Wichtig ist bei den kompilierten
Programmiersprachen, dass wenn die Größe (in unserem Fall 5) des Arrays einmal festgelegt wurde, diese nicht mehr verändert werden kann – man
kann es nicht „dynamisch“ vergrößern oder verkleinern. Wir müssen also vor Erzeugung des Arrays wissen, was wir alles damit anstellen möchten.
Das liegt daran, dass der Platz, den das Array belegt, reserviert – sprich freigehalten – werden muss. Wir werden gleich noch andere Konstrukte
kennenlernen, welche dieses Manko umgehen – bspw. „Listen“. Sehen wir uns jetzt aber erstmal mal an, wie wir uns die Ablage eines Arrays im
Speicher vorstellen können. Wie immer ist die Realität etwas komplizierter, aber wir wollen ja nur die wesentlichen Aspekte verstehen, die wir
für unsere Programmiertätigkeiten benötigen. Bei einem Array von fünf int Werten wissen wir, wie viel Speicherplatz benötigt wird, nämlich
5 x 4 Byte. Im Speicher können wir es uns nun wie folgt vorstellen:
![Speicherbedarf eines int[5] Arrays](img/book/struct/StructRamIntArray5.png)
Abb.: 2: Speicherbedarf eines int[5] Arrays
Ich habe in dem Bild den Speicher zweidimensional dargestellt, so dass die erste Hex-Stelle der Adresse als Zeile und die zweite als Spalte
auftritt (siehe beispielhaft die Adresse 0x13). In den Zellen stehen die (zufälligen) Werte der Speicherzellen. Wenn nun ein Array 5
int Werte a 4 Byte benötigt, so liegt das Array in einem zusammenhängenden Speicherbereich. Weiterhin können wir auch die Adresse des Arrays
festhalten. Das ist die erste Zelle des vom Array belegten Bereichs – in unserem Fall die 0x74. Das ist nun insofern praktisch, als dass sich
der Rechner eigentlich nur drei Dinge merken muss: Wo ist die Startadresse, welcher Datentyp ist in einem Feld und wie viele Felder gibt es?
In unserem Fall wäre dies Startadresse 0x74, Datentyp
int und 5 Felder. Wie bei den „normalen“ Variablen auch, finden wir in den einzelnen Feldern des Arrays wieder die Werte, welche zufällig
im Speicher vorhanden waren. Sehen wir uns mal an, wie wir auf Daten schreibend und lesend in einem Array zugreifen können:
Listing 4: Arraynutzung in C
Kurze Erklärung der Codezeilen: Bei der Initialisierung kann man in C dem gesamten Array auch gleich feste Werte zuordnen, damit wir keine
Zufallswerte mehr vorfinden. Diese stehen immer in geschweiften Klammern. Der Zugriff auf ein einzelnes Element in Arrays erfolgt in eckigen
Klammern – sowohl lesend als auch schreibend.
i[3] = -4000; bedeutet, dass im Array auf Position 3 der Wert -4000 geschrieben wird. In den beiden
printf Aufrufen greifen wir lesend auf das Array zu, um den Wert auf der Konsole auszugeben.
i[0] ist dabei der erste Wert eines Arrays, wodurch
i[4] der letzte ist – nicht wie viele anfangs fälschlicherweise meinen
i[5]!
Die Konsolenausgabe dieses Codes lautet somit:
Soweit zu den Arraymerkmalen, wie sie nicht nur in C, sondern auch in vielen anderen Programmiersprachen vorzufinden sind. Wenn wir noch
tiefer in C einsteigen erkennen wir aber, warum diese Programmiersprache für den Einstieg oftmals nicht die erste Wahl ist. Im Vergleich
zu „moderneren“ im Sinne von „jüngeren“ Programmiersprachen, hat C bei der Umsetzung von Arrays ein paar Besonderheiten. C nennt man
gerne „hardwarenah“, was bedeutet, wir haben einen relativ transparenten Zugriff auf die Ressourcen des Computers. Dies kann man sich zunutze
machen, um den inneren Aufbau von Arrays in C näher zu untersuchen. Hierfür müssen wir aber noch einen kleinen „Schlenker“ über das Konzept
der Zeiger (englisch „pointer“) machen. In C wird dieses Konzept sehr intensiv genutzt. In den neueren Programmiersprachen haben sie jedoch
an Bedeutung verloren. Ich werde später noch etwas genauer auf Pointer und dem Gedanken von Adressen eingehen, hier genügt erstmal eine grobe
Erklärung. Wenn wir uns die Abbildung 2 nochmal ansehen, dann erkennen wir für jede Speicherzelle
erstmal zwei Informationen. Der Wert der Speicherzelle und die Adresse. Mit den Werten haben wir ja bereits Bekanntschaft gemacht – die
Adresse blieb bis jetzt für uns verborgen. Mit einem einfachen Code in C können wir aber die Adresse einer Variablen herausfinden:
Listing 5: Zugriff auf Variablenadresse in C
Kurze Erklärung der Codezeilen: Wir deklarieren und initialisieren eine Variable
zahlVariable. Anschließend erzeugen wir eine neue Variable, welche mit Hilfe des
„*“ als „pointer“ deklariert wird. Dadurch sind wir in der Lage, „Adressarithmetik“ zu betreiben – sprich mit Hilfe von Rechenoperationen
den Adresswert auf andere Adressen zeigen lassen, was wir im nächsten Codebeispiel
(Listing 6)ausprobieren werden. Im Code oben schreiben in diese Pointervariable nun die Adresse der
zahlVariable, was mit Hilfe des
„&“ Operators erfolgt. Nun greifen wir auf die einzelnen Variablen zu. In der ersten Ausgabe schreiben wir einfach nur den Wert der
zahlVariable auf die Konsole. In der zweiten Ausgabe schreiben wir die Adresse der Variablen, die wir ja in der Pointervarialben
zahlAdresse gespeichert haben. Und in der letzten Ausgabe geben wir den Inhalt der Speicherzelle aus, auf die die Adresse von
zahlAdresse zeigt.
Die Ausgabe sieht dann wie folgt aus:
Die Adresse der Variablen ist also 6.422.292, wobei dies bei mehrmaligem Ausführen der Software unterschiedlich sein kann – je nachdem
welchen Speicherbereich der Computer für diese Variable „aussucht“. Wenn wir nun den Inhalt der Speicherzelle mit der Adresse
6.422.292 ausgeben, dann erhalten wir natürlich wieder den Wert 10. Dies ist übrigens auch einer der Gründe, warum wir bei der
Erzeugung der Pointervariablen angeben müssen, auf was für einen Datentyp der Pointer zeigt, damit der Computer die Ausgabe richtig
interpretieren kann – doch davon später mehr.
Nun wenden wir dieses Wissen auf unser Array an:
Listing 6: Zugriff auf Variablenadresse in C mit Adressänderung
Wenn wir den Code ausführen, gibt es zwar eine Warnung, die ignorieren wir aber einfach.
Kurze Erklärung der Codezeilen: Wir deklarieren und initialisieren wieder ein Array. Danach schreiben wir die Adresse des Arrays in den
Pointer
adr. Hier wird die Warnung erzeugt, da der Pointer für
int ausgelegt ist und nicht für
int[]. Da das genau das ist, was wir machen wollen, werden wir die Warnung ignorieren. Nun geben wir die Adresse und den Inhalt der
adressierten Speicherzelle aus. Dies ist erwartungsgemäß der erste Wert im Array, nämlich die 1. Nun erhöhen wir den Adresswert um
1 mit dem
++ Operator. Interessanterweise erhöht sich der tatsächliche Adresswert um 4; was daran liegt, dass der Computer bei einem Zeiger auf
int die 4 Bytes, welche ein
int Wert belegt, bei Erhöhung um 1 auf die aktuelle Adresse hinzufügt. Nun geben wir den Inhalt dieser Speicherzelle aus (was wir bei
Pointervariablen mit einem Vorangestellten
“*“ machen müssen) und erhalten als Wert die 20, was der zweite Wert unseres Arrays ist.
Hier der Vollständigkeit halber nochmal die Ausgabe aus meinem Testlauf des Programms:
Zweidimensionale Arrays in C
Wir sehen also, dass C die Arraydaten sequenziell im Speicher ablegt. Dies erklärt, warum der Zugriff auf Arrays sehr schnell
vonstattengeht – die Adressarithmetik ist relativ unkompliziert. Arrays befinden sich in der Hierarchie der Programmierelemente relativ
weit unten – sie werden neben den primitiven Datentypen auch als einer der Grundbausteine gesehen (auch wenn sie streng genommen eine
Ebene höher liegen, da sie ja aus primitiven Datentypen zusammengesetzt sind). Unser Array aus dem vorigen Beispiel war jetzt eine
Liste von 5 Werten. Was ist aber, wenn wir keine eindimensionale Liste benötigen, sondern eine Matrix – sprich eine zweidimensionale
Liste? Es gibt viele Einsatzmöglichkeiten für solche Konstrukte. Gehen wir beispielsweise davon aus, wir wollen einem Grafikprogramm
die Informationen für ein Rechteck mitgeben:
Abb.: 3: Rechteck im Pixel-Koordinatensystem
Die vier Punkte liegen auf 200/200, 600/200, 600/400 und 200/400 Pixel. Diese Informationen können wir sehr einfach in einer
zweidimensionalen Liste ablegen:
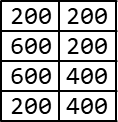
Abb.: 4: Zweidimensionale Liste
Und genau solch eine zweidimensionale Liste würden wir in unseren Programmen auch in einem zweidimensionalen Array ablegen. Der
zugehörige C Code hierzu würde wie folgt aussehen:
Listing 7: Zweidimensionales Array in C
Kurze Erklärung der Codezeilen: Das Array erzeugen wir diesmal mit der Angabe der Höhe und Breite des zweidimensionalen Feldes, jeweils
in einer eigenen eckigen Klammer. Die Zeilenanzahl beträgt 4 und die Spaltenanzahl 2. Auch hier können wir gleich das ganze Array mit
Werten belegen, diesmal müssen wir ein äußeres Klammernpaar für alle Zeilen vorsehen und pro Zeile je ein inneres Klammernpaar, in das
wir die beiden Koordinatenwerte je Punkt eintragen. Der Zugriff auf einzelne Elemente erfolgt dann konsequenterweise wieder über je eine eckige
Klammer für Zeilen- und Spaltenposition
Die Frage ist nun, wie wird das Array jetzt im Speicher abgelegt? Nun, das können wir wieder mit einem einfachen C Programm herausfinden:
Listing 8: Adressanalyse eines zweidimensionalen Arrays in C
Da der Code nichts Neues enthält, spare ich mir hier eine weitere Erklärung und wir sehen uns gleich die Ausgabe an:
Die Daten liegen also sequenziell im Speicher. Wenn wir das in unserem gedachten Speichermodell mal ansehen, können wir uns das wie folgt vorstellen:
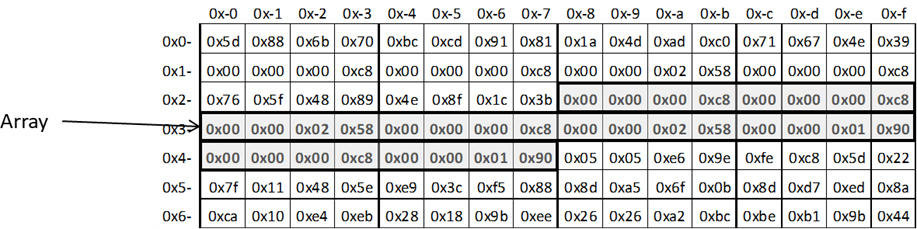
Abb.: 5: Ablage eines zweidimensionalen Arrays in C
Die Adressrechnung, welche der Computer durchführen muss, ist auch hier recht simpel. Da wir wissen, wie viele Spalten unsere Matrix hat
(in unserem Fall 2), ist die Adresse für jeden Punkt in unserem Array wie folgt zu ermitteln: Adresse für
punkte[Zeile][Spalte] ist Anfangsadresse des Arrays + 2*4*Zeile + 4*Spalte. Versuchen wir mal die Adresse unseres Punktes
„punkte[3][1]“ (das ist der letzte Eintrag unseres Arrays) herauszufinden: Spalte = 1, Zeile = 3 und die Anfangsadresse ist
2816 oder im Dezimalsystem 40. Dadurch ist die Adresse unseres Punktes 40 + 2*4*3 + 1*4 = 68
oder 4416. Das ist genau die Position des letzten int Wertes im Speicher. Das Ganze funktioniert aber nicht
nur bei ein- oder zweidimensionalen Arrays, sondern auch bei noch höheren Dimensionen. Einzige Einschränkung ist hier, dass das Array
„symmetrisch“ sein muss, sprich im zweidimensionalen Fall müssen die Anzahl der Spalten für jede Zeile gleich sein. Wir werden gleich noch
sehen, dass man das in anderen Programmiersprachen durchaus anders gestalten kann. Doch zuvor möchte ich noch auf eine kleine Besonderheit
von C eingehen, welche mit ein Grund für die sinkende Popularität von C erklärt. Sehen wir uns den folgenden Code genauer an:
Listing 9: Fehlerhafter Arrayzugriff in C
Die Ausgabe dieses Codes (zumindest beim ersten Durchlauf auf meinem Rechner) ist:
Was ist hier passiert? Nun, wir haben ja auf die Arrayposition 4/0 zugegriffen. Nachdem die erste Arrayposition die „0“ ist, muss die
letzte entsprechend „3“ sein. Wir greifen aber auf „4“ zu, was bedeutet, wir „schießen über das Ziel hinaus“. Wir greifen also auf
Werte zu, die nicht Teil des Arrays sind und wir somit einen „zufälligen“ Wert auf dem Speicher lesen. Dem nicht genug – wir könnten
theoretisch auch einen Schreibzugriff an dieser Stelle durchführen! Wenn nun zufällig eine andere, wichtige Information genau auf
dieser Speicherzelle liegt, könnten wir unser Programm hiermit zum Absturz bringen. Wir greifen also auf „fremde“ Speicherbereiche zu,
was bei Arrays auch als Überlauf bezeichnet wird. C verhindert solche Zugriffe erstmal nicht! Dies bedeutet, dass ein C-Programmierer sehr genau
auf seinen Code achten muss. Das Problem ist, dass solche Abstürze auftreten können, aber nicht müssen... je nachdem welche Information
„zufällig“ direkt nach dem Array abgelegt wurde. Es ist also möglich, dass solche Abstürze im Test nicht entdeckt werden und dann
irgendwann mal auf dem Userrechner zu einem Fehlverhalten führen. Dieses Problem tritt insbesondere auch dann zutage, wenn wir direkt
mit Pointern und der dazugehörigen Adressarithmetik arbeiten.
Die Frage ist nun, ob C auch so etwas wie dynamische Arrays anbietet und man ahnt es schon – nein! Man muss es mal wieder selbst
durchführen oder eine externe Bibliothek nutzen, in der sich schon jemand diese Mühe gemacht hat. Eine Lösung wäre das für Java/C#
genutzte Prinzip der dynamischen Listen basierend auf Arrays selbst zu programmieren. Eine andere Möglichkeit, welche tatsächlich gerne genommen wird, sind
die verketteten Listen. Eine solche Liste werde ich später nochmal vorstellen.
Strings in C
Das Verständnis von Arrays ist in C nun auch eine Grundvoraussetzung, Texte zu speichern. Anders als C# oder Java speichert C Texte –
meist auch „Strings“ genannt – in Arrays ab. Das liegt insofern nahe, als dass Strings ja eine Aneinanderreihung von Zeichen sind. Wenn
wir also ein Zeichen in einer
char Variable speichern können, dann müsste ein
char Array ja einen String ablegen können. Probieren wir es aus:
Listing 10: Versuch, Strings in C als char Array abzubilden
Die Ausgabeformatierung ist nun nicht mehr
%d, sondern
%s für eine Interpretation als String. Sehen wir uns das Ergebnis an:
Unser Text „hallo welt“ ist zwar zu sehen, aber es kommen noch weitere „merkwürdige“ Zeichen ans Licht. Was ist hier also passiert?
Wir haben ja bereits festgestellt, dass in C für ein Array der Platz reserviert ist. Dass wir beim Zugriff nicht „über das Ziel
hinausschießen“ sind aber wir zuständig. Wir sollten also nicht auf den Speicherbereich nach dem Array zugreifen, können es aber.
Und genau das ist hier passiert. Der Computer hat einfach munter die Speicherzellen nach dem reservierten Speicherbereich für das Array
ausgelesen. Und dort standen nun irgendwelche zufälligen Daten, die eben zu zufälligen Zeichenausgaben geführt haben. Wir müssen also
dem Rechner mitteilen, wo der String endet. Dazu fügen wir den sogenannten „Stringterminierer“ oder englisch „string terminator“ ein.
Das ist das Zeichen mit der ID „0“ in unserer Zeichentabelle. Diese ID können wir direkt als Zahl eingeben, wodurch sich unser Programm wie
folgt verändert.
Listing 11: Versuch, Strings in C als char Array abzubilden
Wenn wir den Code ausführen, sehen wir den erwarteten Text:
Jetzt möchte man meinen, das ist doch sehr umständlich. Eine Vereinfachung der Initialisierung wäre es, den Text in einer Stringkonstanten
zu hinterlegen. Diese werden bei den meisten kompilierten Programmiersprachen mit doppelten Anführungsstrichen eingegeben (im Gegensatz zu
dem einen Anführungsstrich bei
char).
Listing 12: Stringzuweisung in C
Hier scheint die 0 nicht notwendig zu sein. Wenn man den String jedoch wieder als Array untersuchen würde, dann findet
man an der Indexposition 10 doch wieder die 0 – sie wurde einfach automatisch erstellt. Warum ist das nun so
umständlich? Nun – bei näherer Betrachtung haben wir ein wichtiges Problem noch nicht auf dem Schirm! Gehen wir mal
davon aus, dass wir eine Konsoleneingabe in einer Variablen ablegen möchten. C bietet verschiedene Ansätze für die
Konsoleneingabe – ich verwende hier die einfachste, wohlwissend, dass das Leerzeichen nicht 1:1 eingelesen wird und
vor allem es bezüglich des Überlaufs meiner Variablen gefährlich werden kann. Wir werden gleich sehen, was damit
gemeint ist. Das Hauptproblem bei diesem Anwendungsfall „Usereingabe“ ist, dass wir vorab nicht wissen können, wie
lang der String sein wird, den der User eingibt. Insofern können wir eigentlich die Arraylänge unserer Variablen nicht
festlegen. Wir haben also immer, wenn die Stringlänge nicht vorab feststeht oder gar während der Ausführung des Programms
geändert werden kann, ein Dimensionierungsproblem. Eine – zugegebenermaßen nicht sehr elegante und nicht sichere – Lösung
ist, das Array erstmal sehr groß anzulegen. Sehen wir uns trotzdem mal einen Beispielcode hierfür an, der ganz nebenbei
nur für Demonstrationszwecke genutzt werden sollte(3)
(3) In „realen“ Programmen würden wir dies natürlich besser lösen, bspw. durch zeichenweises Einlesen oder „fgets“
Listing 13: Speicherung einer Konsoleneingabe in C
Kurze Erklärung der Codezeilen: Wir erzeugen ein char Array der Länge 100 in der Annahme, dass der User nie die 100
Zeichen benötigen wird. Danach erfolgt
scanf, was eine Konsoleneingabe vom User einfordert. Diese wird bis zum nächsten „Whitespace“ (bspw. dem Leerzeichen)
oder zur Betätigung der Enter Taste gelesen.
scanf benötigt darüber hinaus noch die Info, wie die Eingabe interpretiert werden soll (bei uns als String: %s) und
die Adresse des
char Arrays, in der die Eingabe abgelegt werden soll:
&eingabe. Danach geben wir den Inhalt der Variablen eingabe wie gewohnt aus.
Bei Starten können wir nicht über den CodeRunner „Play Button“ gehen, sondern müssen über das „Run and Debug“
 Werkzeug
am linken Rand gehen. Hier müssen wir den „gcc“ bzw. „GND“ Compiler auswählen. Dadurch startet der Code so, dass wir auch eine
Eingabe in der Konsole durchführen können. Wenn wir nun den Text „hallo“ eingeben („hallo welt“ geht nicht, da ja ein
Leerzeichen enthalten ist), dann sehen wir auf der Konsole tatsächlich „hallo“ und nicht das Wort „hallo“, gefolgt von
95 zufälligen Zeichen, die durch Zufallszahlen im Speicher erzeugt wurden. Der Rechner scheint also den Terminator
eingefügt zu haben. Das können wir sehr einfach feststellen, indem wir einen Text mit nur 5 Zeichen einzugeben und den
Wert der 6. Indexposition des Arrays (also die Nummer 5, da die 0 ja mitzählt) als Zahl ausgeben lassen:
Werkzeug
am linken Rand gehen. Hier müssen wir den „gcc“ bzw. „GND“ Compiler auswählen. Dadurch startet der Code so, dass wir auch eine
Eingabe in der Konsole durchführen können. Wenn wir nun den Text „hallo“ eingeben („hallo welt“ geht nicht, da ja ein
Leerzeichen enthalten ist), dann sehen wir auf der Konsole tatsächlich „hallo“ und nicht das Wort „hallo“, gefolgt von
95 zufälligen Zeichen, die durch Zufallszahlen im Speicher erzeugt wurden. Der Rechner scheint also den Terminator
eingefügt zu haben. Das können wir sehr einfach feststellen, indem wir einen Text mit nur 5 Zeichen einzugeben und den
Wert der 6. Indexposition des Arrays (also die Nummer 5, da die 0 ja mitzählt) als Zahl ausgeben lassen:
Werkzeug
am linken Rand gehen. Hier müssen wir den „gcc“ bzw. „GND“ Compiler auswählen. Dadurch startet der Code so, dass wir auch eine
Eingabe in der Konsole durchführen können. Wenn wir nun den Text „hallo“ eingeben („hallo welt“ geht nicht, da ja ein
Leerzeichen enthalten ist), dann sehen wir auf der Konsole tatsächlich „hallo“ und nicht das Wort „hallo“, gefolgt von
95 zufälligen Zeichen, die durch Zufallszahlen im Speicher erzeugt wurden. Der Rechner scheint also den Terminator
eingefügt zu haben. Das können wir sehr einfach feststellen, indem wir einen Text mit nur 5 Zeichen einzugeben und den
Wert der 6. Indexposition des Arrays (also die Nummer 5, da die 0 ja mitzählt) als Zahl ausgeben lassen:
Listing 14: Speicherung einer Konsoleneingabe in C mit Ausgabe einzelner Char Codes
Bei Eingabe von „hallo“ ist die Ausgabe des Codes ist entsprechend:
Der Stringterminierer ist also ein Indikator, wo der String aufhört, damit wir nicht vorab 100% exakt wissen müssen,
wie viele Zeichen wir reservieren müssen. Dies hat nun ein paar Implikationen, die allerdings nur bei der
Stringverarbeitung in C gelten:
- Ein String benötigt immer ein Zeichen mehr, als effektiv genutzt werden kann – den Stringterminierer.
- Wir müssen vorab wissen, wie viel maximal in einem String abgelegt werden soll, damit die Größe des char Arrays ausreicht und kein Überlauf während der Laufzeit auftritt.
Listing 15: String Initialisierung als Konstantwert
Kurze Erklärung der Codezeilen: Wir erzeugen nun kein
char Array mehr, sondern eine Pointervariable, welche auf ein
char zeigt. In der gleichen Zeile weisen wir „hallo welt“ dieser Variablen zu. Was wir aber eigentlich hier machen ist,
dass wir die Adresse der Stringkonstanten „hallo welt“ auf den Pointer
„stringVar“ kopieren. Dadurch zeigt diese Variable auf die gleiche Adresse wie die Stringkonstante, weshalb wir sie
ausgeben können. Das Problem hierbei ist, dass die Stringkonstante im Speicher so abgelegt ist, dass sie nicht änderbar
ist (deshalb der Name „Konstante“). Wenn wir beispielsweise versuchen
stringVar[0] = 'H' zu setzen, würden wir einen Fehler bei der Ausführung erhalten.
Die Nutzung von char Pointern als Strings und der Initialisierung mit Konstanten ist nur dann sinnvoll, wenn wir den
Inhalt der Strings nicht mehr ändern wollen. Ansonsten müssen wir über Arrays oder dynamisch erzeugte Speicherbereiche
gehen, da hier bei einer Zuweisung C die Stringkonstante Zeichen für Zeichen in das Array hineinkopiert.
Arrays - Objektorientiert
So viel zu Arrays (und Strings) in C. Sehen wir uns das Ganze mal in Java und C# an. Die beiden Programmiersprachen
verfolgen jeweils ähnliche Ansätze – sie sind objektorientiert und versuchen die Konzepte der Adressarithmetik wie in C
weitestgehend zu „verstecken“. Wir werden die Ideen hinter der Objektorientierung in einem eigenen Abschnitt dieses Buches
noch näher kennen lernen. Für den Moment reicht uns folgende kurze Erklärung: Ein Objekt ist ein Zusammenschluss von
Variablen und Funktionalitäten, der jeweils in einem eigenen Konstrukt – dem Objekt – zu finden ist. Die Konsequenz hieraus
ist, dass im inneren der Objekte solche Situationen wie ein Arrayüberlauf bei Strings von vorneherein abfangen und Fehler generiert werden
können, da wir vor jedem Zugriff auf eine Variable eine Funktionalität setzen können. Zusammengehörige Daten und
Funktionalitäten werden „gekapselt“, was die strukturierte Programmierung erheblich fördert. Um die Begrifflichkeit etwas
eindeutiger zu machen, hat man bei den Objekten die Funktionalitäten „Methoden“ und die Variablen „Eigenschaften“ genannt.
Sehen wir uns nun mal die Erzeugung eines Arrays in C# an (der Code für die Erzeugung ist in Java identisch, lediglich die
Ausgabefunktionalität würde mit
System.out.println() erfolgen):
Listing 16: Arraydeklaration und Ausgabe in C#
Kurze Erklärung der Codezeilen: Wir erkennen bei der Erzeugung des Arrays gewisse Parallelen zu C. Arrays werden in C# und auch in
Java mit eckigen Klammern verwaltet. Der Unterschied hier ist, dass wir die eckigen Klammern gleich beim Datentyp eintragen,
womit die Variable
zahlArray zum Typ
int[](integer Array) wird. Die eigentliche Erzeugung des Arrays wird mit dem Schlüsselwort
new durchgeführt, womit ein innerer Prozess angestoßen wird, der das Array erzeugt. Dadurch haben C# und Java nicht nur die
Möglichkeit das Array zu erstellen, sondern sich auch gleich darum zu kümmern, die initialen Werte im Array auf 0 zu setzen.
Dies können wir dann bei der Konsolenausgabe beobachten. Die Zugriffe auf die einzelnen Arrayposition läuft wiederum exakt
wie in C.
Bei der Ausgabe des Codes sehen wir schließlich auch die definierten Startwerte des Arrays (hier beispielhaft für die
Indexposition 0):
Nun versuchen wir einen Überlauf im Array, indem wir bei der Ausgabe nicht auf
zahlArray[0], sondern auf
zahlArray[5] zugreifen:
Der Computer stoppt mit einer Exception das Programm mit einer Fehlerausgabe. Warum er es stoppt, bzw. was eine
„Exception“ ist werden wir später noch behandeln, soviel sei hier aber gesagt: Wenn der Computer eine für ihn nicht
sinnvoll ausführbare Konstellation findet, wird die Ausführung unterbrochen, das Programm „stürzt ab“.
Der Vollständigkeit halber zeige ich das gleiche Phänomen nochmal in Java:
Listing 17: Arraydeklaration und fehlerhafter Zugriff in Java
Die Java Ausgabe der Exception sieht dann ähnlich wie bei C# aus:
Dadurch, dass wir in C# und Java über Objekte verfügen und diese die Zugriffe kontrollieren können (wir erinnern
uns – Objekte haben auch eigene Funktionalitäten, in denen wir solche Kontrollen einbauen können), verhindert das System
einen unerlaubten Zugriff auf eine nicht reservierte Speicherzelle. Dieses Verhalten hat so manche massiven
Systemabstürze verhindert, da die Chance, dass während des Tests dieses Problem entdeckt wird im Vergleich zu C und
C++ sehr viel höher ist. Gehen wir nun noch einen Schritt weiter und sehen uns an, wie C# und Java Arrays intern behandeln.
Auch hier bedienen wir uns einer modellhaften Vorstellung die ausreicht, das Verhalten von Arrays zu verstehen und somit
vorherzusehen.
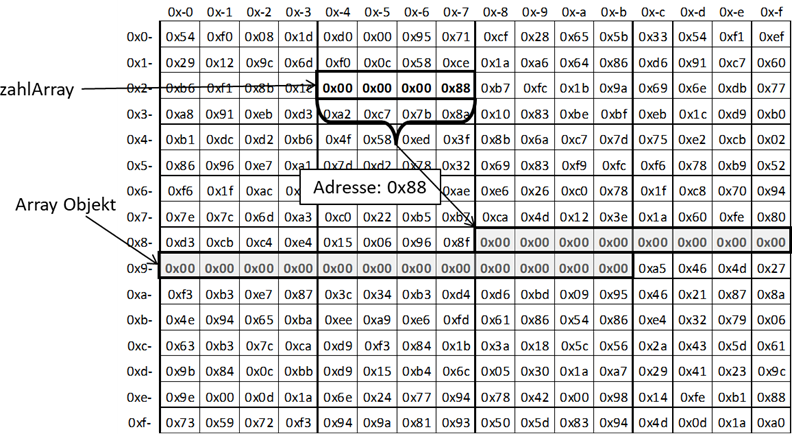
Abb.: 6: Modellhafte Speicherbelegung eines C# bzw. Java Arrays
Die Variable
„zahlArray“ existiert als eigene Speicherzelle. Diese hat zwar eine Adresse, welche aber beim Programmieren faktisch
keine große Rolle mehr spielt. In dieser Speicherzelle befindet sich nun eine Adresse – man spricht hier von einer
„Referenz“ – auf das eigentliche Array Objekt. Im Bild sind „nur“ die Daten dargestellt, in Wirklichkeit liegt hier
sehr viel mehr drin, nämlich die gesamte Funktionalität des Objektes und eventuell notwendige zusätzliche Daten,
was für unsere Vorstellung jetzt erstmal nicht sonderlich wichtig ist. Genauso wie die Tatsache, dass diese
Ablagestruktur nur virtuell in der Laufzeitumgebung („virtual machine“) von Java bzw. C# vorliegt. Entscheidend ist
eben die Trennung des eigentlichen Wertes der Variable
zahlArray und dem tatsächlichen Objekt. Durch die
Objektorientierung unseres Arrays können wir nun beispielsweise die Länge des Arrays einfach abfragen.
Das Arrayobjekt ist sich seiner Länge also bewusst, was nicht verwundert, da es ja den Zugriff außerhalb der
definierten Länge kontrolliert und blockiert, was ohne dieses Wissen nicht möglich wäre. Sehen wir uns an, was der
folgende Code bewirkt:
Listing 18: Längenbestimmung eines Arrays in C#
Kurze Erklärung der Codezeilen: Die initiale Belegung eines Arrays mit Werten erfolgt in C# und Java genauso, wie in
C mit einer geschweiften Klammer (dies gilt übrigens auch für mehrdimensionale Arrays). In der Ausgabe wiederum rufen
wir eine Eigenschaft des Arrayobjektes auf. Diese Aufrufe von objektinternen Eigenschaften und Methoden erfolgt mit
dem Puntkoperator, gefolgt von der entsprechenden Eigenschaft bzw. der Methode. In unserem Fall wollen wir die
Eigenschaft „Länge“ des Objektes wissen, weshalb wir
zahlArray.Length ausgeben.
Die Ausgabe liefert uns:
Diese Information hilft uns schon mal in unserem Code, unzulässige Zugriffe auf unser Array von vorneherein zu verhindern,
da wir die Länge nun prüfen können.
Welche Eigenschaften und Funktionen die jeweiligen Objekte besitzen, muss im Zweifelsfall in der
API-Dokumentation(4) der jeweils genutzten Elemente nachgelesen werden. Soweit schon mal
ein kleiner Vorteil des Objektansatzes von Java und C#. Nun gehen wir mal auf die nächste Ebene und sehen uns den
Aufbau von mehrdimensionalen Arrays an, welche in C# und Java nicht als Matrix wie in C, sondern als „Arrays von Arrays“
realisiert werden kann:
(4) API: Application Programming Interface ist die Sammlung der zur Verfügung stehenden Elemente der Programmiersprache
Listing 19: Erzeugung eines zweidimensionalen Arrays in Java
Soweit sieht das jetzt erstmal „unverdächtig“ aus, da die Gedanken aus dem eindimensionalen Array sinnvoll um die zweite Dimension (und wer möchte auch
viel höhere Dimensionen) erweitert wurde. Wir werden später noch sehen, dass in C# hier eine weitere Syntaxvariante existiert (die eigentlich den
„alten“ C Gedanken einer Matrix wiederbelebt). Insofern bleiben wir jetzt erstmal bei Java und sehen uns deshalb mal folgenden Code an:
Listing 20: Initialisierung mehrdimensionales Array in Java
Kurze Erklärung der Codezeilen: Der Datentyp, welcher vor
zahlArray steht, ist jetzt mit
int[][] als „Array von Array“ gekennzeichnet – was ein zweidimensionales Array darstellt. Wie in C auch, können wir
mit vordefinierten Werten initialisieren. Nun geben wir die Länge des Arrays aus (in Java wird hier
length mit
kleinem „l“ geschrieben). Danach sehen wir uns die Breite der 0. Zeile an.
Die Ausgabe des Programms:
Hier haben wir schon den ersten Indikator dafür, dass der „Array von Array“ Ansatz recht praktisch sein kann. Wir
können also nicht nur die Länge, sondern auch die Breite unseres Arrays feststellen. Nun ergänzen wir unseren Code
wie folgt:
Listing 21: Asymmetrisches Array in Java
Die zweite Zeile ist jetzt also breiter als die erste und letzte Zeile. Sehen wir uns dies in der Ausgabe an:
Wir haben also ein asymmetrisches zweidimensionales Array geschaffen. Das Ganze geht auch flexibler, wie folgender Code beweist:
Listing 22: Dynamische Erzeugung eines asymmetrischen Arrays in Java
Kurze Erklärung der Codezeilen: Wir erzeugen nun im Speicher ein Array von Arrays und sagen, dass das äußere Array
in Summe 3 innere Arrays aufnehmen kann. Danach erzeugen wir für jede Position des äußeren Arrays jeweils ein
individuelles inneres Array. Zuerst eins der Länge 4, dann eins der Länge 3 und am Schluss eins der Länge 5.
Anschließend lassen wir uns die Längen der jeweiligen Arrays wieder ausgeben.
Die Ausgabe dürfte nun niemanden mehr überraschen:
Trotzdem sehen wir uns nochmal schnell die Belegung in unserem vereinfachten Speichermodell an:
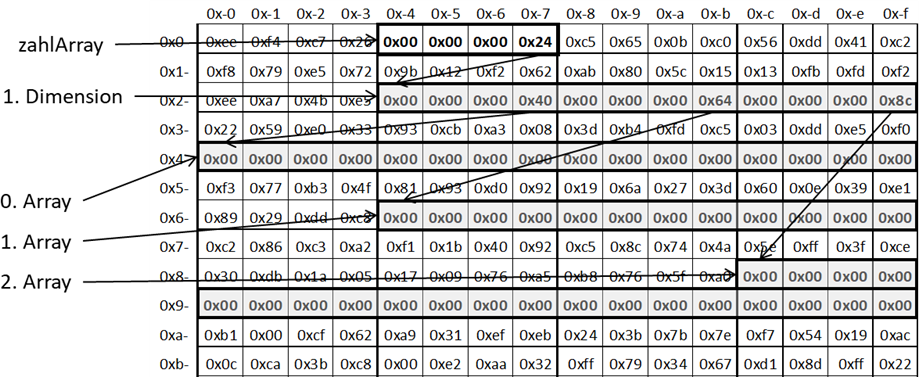
Abb.: 7: Speichermodell von 2-dimensionalem Array als Objekte
Die Variable
zahlArray liegt im Speicher und trägt die Adresse des Arrays der 1. Dimension. Dieses hat drei Einträge. In jedem dieser
Einträge finden wir wieder eine Adresse, und zwar die des 0., 1. und 2. Arrays der Längen 4, 3 und 5. Wo diese
Arrayobjekte liegen, ist vollkommen irrelevant – im Gegensatz zu C, wo die Arrays in einem Block abgelegt werden.
Wichtig ist nur, dass die Adressen jeweils im Array der 1. Dimension abgelegt wurden. In Java (und auch C#) finden wir
in einer Variablen welche ein Objekt enthält, ja lediglich die Adresse, unter der das Objekt im Speicher zu finden
ist (Achtung – dies ist bei primitiven Datentypen nicht der Fall!). Wenn wir diesen Gedanken jetzt näher analysieren,
kommt uns hier noch ein weiterer Punkt in die Quere. Sehen wir uns das folgende Listing an:
Listing 23: Dynamische Erzeugung eines asymmetrischen Arrays in Java ohne Belegung der 2. Dimension
Kurze Erklärung der Codezeilen: Wie im vorausgegangenen Code erzeugen wir eine Variable für ein zweidimensionales Array,
legen aber nur das Array der 1. Dimension fest. In die drei Felder des Arrays legen wir aber kein neues Array hinein –
die Felder bleiben ohne Initialisierung. Bei der Ausgabe lassen wir uns wieder die Länge des Arrays der 1. Dimension
anzeigen. Anschließend versuchen wir den direkten Wert aus dem Feld der 0. Indexposition auszugeben, also dort, wo wir
eigentlich nichts hineingelegt haben.
Die Ausgabe zeigt uns jetzt einen neuen, in der Programmierung wichtigen Begriff, die „null“:
Wir sind hier auf ein Phänomen bei Objekten gestoßen, welches wir bei den einfachen Datentypen so nicht kannten. Was ist
passiert? Nun, bei einfachen Datentypen, bspw. bei
int haben wir festgestellt, dass jede der 216 Bitkombinationen einer tatsächlichen Zahl
zugeordnet wurde. Es gibt also keine Bitkombination, die keine „Bedeutung“ hat. Bei Objektvariablen ist dies anders.
Hier steht ja die Adresse des Objektes in der Variablen. Wenn dort aber eine Adresse steht, die nicht existiert (meist
als Adresse „0“ referenziert), dann kann der Computer mit diesem Objekt auch nicht arbeiten. Da ein Array in Java bei
der Erzeugung automatisch initialisiert wird (Java setzt ja beispielsweise bei einem
int Array alles auf 0), trägt Java bei
Objekten eine Bitkombination für
„null“ ein – sprich eine nicht existente Adresse.
„null“ bedeutet also „kein Objekt vorhanden“. Die Variable existiert zwar, zeigt aber auf „nichts“, was ja mit „Null“
übersetzbar wäre (weshalb man auch vom „Null Pointer“ spricht). Sehen wir uns mal an, was passiert, wenn wir versuchen
die Länge des nicht vorhandenen Arrays auf der Indexposition 0 festzustellen:
Listing 24: Versuch des Zugriffs auf ein nicht vorhandenes Objekt in Java
Die Ausgabe verwundert nun nicht – schließlich haben wir etwas Unmögliches verlangt: die Eigenschaft von etwas auszulesen,
das gar nicht existiert:
Diese
NullPointerException ist vermutlich die häufigste Fehlersituation, mit der man als Programmierer von objektorientierten
Sprachen zu tun haben wird. So viel zu den Arraykonzepten in Java. Widmen wir uns nun kurz den Besonderheiten von C#
in diesem Zusammenhang. C# würde die dynamische Generierung von Arrays in Arrays genauso unterstützen wie Java.
Der folgende Code unterscheidet sich kaum vom Listing 21:
Listing 25: Dynamische Erzeugung eines asymmetrischen Arrays in C#
Die Ausgabe ist exakt die Gleiche, wie bei Java. Allerdings haben sich die C# Macher wohl an das Konzept aus C erinnert,
dass man auch symmetrische Arrays ganz gut gebrauchen kann. Nun ist es so, dass mit dem Java Konstrukt
int[][] zahlArray = new int[3][4] auch ein symmetrisches Array erzeugt werden würde, aber es ist nun eben intern ein
Array von Arrays und nicht ein Array, in dem wir mit einer schlauen Adressarithmetik auf die einzelnen Zeilen uns Spalten
zugreifen können. Nun haben die C# Entwickler jedoch beschlossen, die Java Konstruktion so nicht umzusetzen, sondern sie
fordern immer den Weg aus Listing 24, also zuerst Erzeugung des äußeren
Arrays und dann die explizite Erzeugung der inneren. Um nun doch wieder in einer Zeile ein leeres mehrdimensionale Array
zu erzeugen gibt es in C# die Option, die Matrixschreibweise anzuwenden. Sehen wir uns das mal im Code an:
Listing 26: Zweidimensionales Array als Matrix in C#
Kurze Erklärung der Codezeilen: Die Variable wird nun als zweidimensionales Matrixarray mit
[,] erzeugt. Dreidimensional wäre dann entsprechend
[,,]. Die Initialisierung wurde hier mit vordefinierten Werten mit Hilfe der geschweiften Klammern vorgenommen.
Achtung – hier müssen nun die Anzahl der Spalten pro Zeile immer identisch sein, sonst gibt es einen Compilerfehler.
Wenn man keine vordefinierten Werte haben möchte, so kann man
new int[3,2] schreiben – C# würde dann überall die 0 eintragen werden. Bei der Ausgabe verlangen wir die Länge des
Arrays, wobei dies die Gesamtanzahl der Elemente ist, wodurch es konsequenterweise mit der
.Length Eigenschaft nicht Möglich ist die Breite auszulesen. Dies erfolgt mit der Methode
GetLength(), welche als Parameter die Dimension benötigt. Der Zugriff erfolgt sinnigerweise auch über die eckige
Klammer und den Indizes über Komma getrennt. C# wirft hier allerdings auch eine
IndexOutOfRangeException, wenn wir außerhalb des gültigen Bereiches auslesen.
Die Ausgabe ist nun wieder entsprechend. Es sei hier nochmal darauf hingewiesen, dass die Länge nun die Gesamtanzahl der Elemente aufzeigt – also 6 und nicht die Anzahl der Zeilen.
Die „Macher“ von C# standen nun wohl vor der Frage, wie die Initialbelegung mit Werten eines mehrdimensionalen Arrays
zu interpretieren ist. Der Ausdruck aus dem oberen Listing
{{11, 12}, {21, 22}, {31, 32}}; musste nun entweder für die Matrix, oder dem mehrdimensionalen Array festgelegt werden.
Dabei haben sie sich für die Matrix entschieden. In Java gibt es keine Matrix in dieser Form, weshalb dieser Code dort
als Initialisierung eines mehrdimensionalen Arrays gewertet wird wie wir im
Listing 20
gesehen haben.
Der ein oder andere kann an diesen „Matrix-“ Arrays erkennen, dass der Verzicht von Java auf dieses Konstrukt nun kein
großer Verlust ist, da der „Array von Array“ Ansatz auch die symmetrischen Konstrukte abbildet und die Feststellung der
Breite und Länge relativ eingängig ist. Eingefleischte C# Programmierer wiederum würden vermutlich nicht auf dieses
Konstrukt der Matrix verzichten wollen. Was auf jeden Fall aber ersichtlich werden sollte ist, dass der C-Ansatz sehr
viel simpler gestrickt ist und somit sehr viel mehr Aufmerksamkeit vom Programmierer erfordert. Auf der anderen Seite
ist C die grundlegendere Sprache. Beispielsweise wurde die Java Virtuelle Maschine ursprünglich in C geschrieben.
Allein deshalb ist es meines Erachtens nicht sinnvoll, die eine Programmiersprache über die andere zu stellen. Jede
Sprache hat irgendwo seine Daseinsberechtigung. Der Vorteil der objektorientierten Sprachen wiederum ist, dass mit dem
Punktoperator die internen Methoden von Arrays genutzt werden können, wo einiges an potentiellen Fehlern bereits abgefangen
wird. In den einzelnen objektorientierten Programmiersprachen gibt es darüber hinaus noch „Utilitiy Klassen“, welche den
Umgang mit Arrays vereinfachen. In Java wäre dies beispielsweise die Klasse
java.util.Arrays, in C#
ArrayUtil und in C++
utils::ArrayUtils. Die Utilities muss man meist aus externen Bibliotheken importieren oder gleich selbst anfertigen.
Prozedurale Ansätze wie in C sind wiederum gegenüber den objektorientierten Sprachen meist performanter.
Dynamische Arrays
Lösen wir nun unser Problem mit der statischen Arraygröße. Gehen wir mal davon aus, wir wollen Usereingaben in einem
Array speichern. Immer wenn die Informationen bzw. Inhalte für unsere Arrays von außen kommen, wissen wir nicht wie
viele Einträge wir haben werden – sprich wir können die Arraygröße nicht von vorneherein festlegen. In den
objektorientierten Programmiersprachen gibt es hierfür im Regelfall eigene Klassen (zum Teil sogar mehrere), welche
dieses Problem in den Griff bekommen. Der Überbegriff von solchen Konstrukten lautet „dynamische Arrays“. Eine
Internetsuche mit „dynamic array java“ bringt uns beispielsweise relativ schnell zu dem vermutlich am häufigsten
genutzten Java Konstrukt für diese Aufgabe, der
ArrayList. Sehen wir uns mal ein Beispiel an, in der eine ArrayList mit Werten gefüllt wird. Danach wird ein Wert
ausgegeben, mittig einen Wert hinzugefügt, der vorletzte Wert gelöscht und der letzte ausgetauscht. Am Schluss werden
alle Werte nochmal per Schleife ausgegeben:
Listing 27: ArrayList als dynamisches Array in Java
Kurze Erklärung der Codezeilen: Die
ArrayList befindet sich in
java.util, weshalb wir diese Bibliothek importieren müssen. Danach wird eine leere
ArrayList erzeugt, indem der „Konstruktor“
new ArrayList() aufgerufen wird. Damit das Objekt weiß welche Daten es verarbeiten soll, wird über einen
Typenparameter mitgeteilt, dass es sich um
„Strings“ kümmern muss. Dieses Konzept nennt man „Generics“, was so viel bedeutet, dass die Klasse zwar generisch
agiert (sprich mit allen Klassen arbeiten kann), über den Parameter aber typisiert wird, damit beim Zugriff kein
Typecast auf „Object“ notwendig ist. Wem das nun zu „kompliziert“ vorkommt, soll sich noch ein wenig auf das
Kapitel „Objektorientierung“ warten, wo das Konzept nochmal etwas deutlicher gemacht wird. Für jetzt müssen wir uns
lediglich merken, dass eine
ArrayList in Java zwischen den
<> Zeichen einfach die Klasse haben möchte, welche wir mit der
ArrayList verarbeiten wollen – in unserem Fall eben
String. Da wir nun mit einem Objekt der Klasse
ArrayList arbeiten, gehen wir beim Zugriff immer über Methoden - also
"Funktionalitäten", welche mit dem Punktoperator "." nach dem Variablennamen des
ArrayList Objektes angesprochen werden, bspw.
myList.get(i).
Die wichtigsten Methoden der Java ArrayList finden sich weiter unten in
Tabelle 1. Wenn wir unseren Code nun ausführen, sehen wir:
Zwei Dinge müssen wir bei der
ArrayList nun noch klären. ArrayListen können in Java nur Objekte verwalten. Das ist in Bezug auf die primitiven
Datentypen eine erhebliche Einschränkung. Warum die Java Autoren die ArrayList so gestalten mussten, werden wir im
Abschnitt zur Objektorientierung noch sehen. Die Frage ist nun, wie bekommen wir eine ArrayList von Zahlen, wie bspw.
„int“ realisiert? Hier kommen wieder die Wrapperklassen ins Spiel. Der Umgang mit Variablen vom Typ dieser
Wrapperklassen funktioniert genauso wie mit den primitiven Datentypen. Dadurch können wir eine
ArrayList() erzeugen und bspw. mit
„add(123)“ eine ganze Zahl anhängen.
Das zweite wichtige Detail ist der innere Aufbau von solchen Konstrukten. Sehr einfach ausgedrückt handelt es sich um ein
Objekt, in dem sich ein Array befindet, welches über Manipulationsmethoden befüllt und verwaltet wird:

Abb.: 8: Vereinfachter innerer Aufbau einer ArrayList in Java
Wenn wir also
get() aufrufen, wird lediglich auf das innere Array zugegriffen und der Wert zurückgegeben. Das ist nun auch
deshalb „vereinfacht“, weil ich das ganze Thema Typisierung hier der Einfachheit halber mal weggelassen habe.
Die wichtige Frage ist, was passiert nun, wenn ich das innere Array mit zusätzlichen Einträgen bestücken möchte. Bis
zum 10. Element ist dies ja kein Problem, da ich das innere Array mit der Größe „10“ angenommen habe. Was passiert aber
beim 11. Element? Hier muss ein neues Array erzeugt und die Werte vom alten Array übernommen werden:

Abb.: 9: Erweiterung der inneren Datenhaltung von ArrayListen in Java
Man kann sich vorstellen, dass dieser Prozess nicht in null Zeit durchgeführt werden kann – aber schließlich zahlt man
für jede Annehmlichkeit einen Preis – in diesem Fall zahlt man für die Flexibilität der
ArrayList den Preis der Performance. Wenn ich jedoch von vorneherein bereits weiß, dass ich – sagen wir 500 – Werte
eintragen muss, so würde es sinnvoll sein, das innere Array bereits mit dieser Größe anzulegen. Und genau dafür gibt es
einen weiteren Konstruktor, welcher einen Parameter akzeptiert:
new ArrayList(500) .
Das Ganze funktioniert auch in C# - nur dass die Klasse hier
List heißt und in der Bibliothek
System.Collections.Generic zu finden ist:
Listing 28: List als dynamisches Array in C#
Bemerkenswert gegenüber Java ist, dass der Zugriff hier wie bei normalen Arrays funktioniert. Die C# Autoren haben
zugunsten der einfacheren Nutzbarkeit auf die strikte Umsetzung der objektorientierten Idee, alle Funktionalitäten
über Methoden zu realisieren, verzichtet.
Sehen wir uns noch eine Möglichkeit für dynamische Array an, die uns C++ bietet, der
vector.
Listing 29: Vector als dynamisches Array in C++
Ansonsten sind die Implementierungen in Java, C# und C++ sehr ähnlich, was der Vergleich der wichtigsten Methoden zeigt:
| Java: | C#: | C++: | Funktion: |
|---|---|---|---|
| new ArrayList<class>() | new List<class>() | std::vector<std::class> | Konstruktor – erzeugt ein leeres dyn. Array, welches Objekte der Klasse „class“ verarbeitet |
| new ArrayList<class>(cap) | new List<class>(cap) | existiert nicht | Konstruktor – erzeugt eine leeres dyn. Array, welches Objekte der Klasse „class“ verarbeitet, mit einer initialen Kapazität von „cap“. |
| .add(object) | .Add(object) | .push_back(object) | Hängt „object“ am Ende an. |
| .add(object) | .Add(object) | insert(v.begin()+pos, object)(5) | Fügt „object“ an der Position „pos“ ein. |
| .get(pos) | [pos] | [pos] | Gibt den Eintrag an der Position „pos“ zurück. |
| .remove(pos) | .RemoveAt(pos) | .erase(pos) | Löscht den Eintrag an der Position „pos“. |
| .set(pos, object) | [pos] = object | [pos] = object | Ersetzt den Eintrag an der Position „pos“ durch „object“. |
| .size() | .Count() | .size() | Gibt die Anzahl der Elemente aus. |
Tabelle 1: Wichtige Methoden der Java ArrayList, C# List und C++ vector
(5) „v“ steht für das Vektorobjekt selbst.
v.begin() liefert einen Iterator, mit dessen Hilfe der C++ Compiler die Adressarithmetik durchführen kann.
Nun ist noch ein Hinweis sinnvoll, der im Zusammenhang mit dynamischen Listen wichtig ist. Sehen wir
uns das am Beispiel eines Java Codes mal an:
Listing 30: Indexverschiebung durch Ergänzung in Java
Die Ausgabe ist nun nicht sehr verwunderlich:
Die hier wichtige Erkenntnis ist jedoch, dass wir uns bei dynamischen Arrays nicht darauf verlassen können,
dass ein Wert, den ich zum Zeitpunkt 1 auf einer Indexposition finde, zu einem späteren Zeitpunkt 2 hier zwingend
auch wieder vorfinde. In unserem Beispiel ist der Text „einkaufen“ von Indexposition 2 auf 3 gerutscht. Solch
ein Verhalten werden wir bei Arrays nie vorfinden, es sei denn ich schreibe explizit auf Indexposition 2 einen
anderen Wert. Das ist nun auf den ersten Blick trivial und scheinbar von keiner großen Bedeutung, jedoch sollten wir
vor diesem Hintergrund wirklich nur dann dynamische Arrays nutzen, wenn wir wirklich die Dynamik brauchen. Wenn wir
bspw. Konfigurationsdaten in ein Array verpacken, dann erwarten wir, dass die einzelnen Konfigurationsinformationen
immer auf festen Plätzen zu finden sind. Beispielsweise packen wir in ein Array auf Indexposition 0 die IP Adresse,
auf Indexposition 1 den Port und auf 2 das genutzte RDBMS. In solch einer Situation wäre es sinnvoll, die Werte
0, 1 und 2 als Konstanten zu erstellen:
Listing 31: Nutzung als Konstanten für Arrayzugriffe in Java
Kurze Erklärung der Codezeilen: Wir wollen die drei Werte IP-Adresse, Port und Datenbanktyp in einem Array speichern.
Damit wir uns die Indexpositionswerte nicht merken müssen, erzeugen wir mit dem Schlüsselwort
final jeweils eine int Variable
IP,
PORT und
DB_TYPE (Konstanten schreibt man üblicherweise in Großbuchstaben, um den Code lesbarer zu machen). Somit können wir
auf die jeweiligen Arraypositionen über die Konstanten zugreifen – also anstatt
cfgValues[1] schreiben wir nun
cfgValues[PORT], was einfacher lesbar ist.
Die Ausgabe dieses Codes wäre somit:
Dadurch, dass wir zu 100% wissen, dass sich die Positionen der Elemente nicht verschieben können, ist die Nutzung von
Konstanten für die Positionen entsprechend problemlos möglich. Gerade für Informationen, wie Konfigurationen oder
technisch wichtige Daten, greift man gerne auf solche Konstrukte zurück. Bei dynamischen Arrays wäre dieser Ansatz
fehleranfällig, da wir die Position der Elemente ja im Nachhinein ändern können.
Assoziative Arrays / Dictionaries
Und in diesem Zusammenhang kommen wir nun zu dem letzten wichtigen Konstrukt bei Arrays, den „assoziativen Arrays“; also Arrays, bei
denen wir nicht über die Indexpositionen zugreifen, sondern über eindeutige Werte. Jeder Eintrag in solchen Arrays erhält ein
eindeutiges Label, oder auch Schlüssel (engl. „key“) genannt – ähnlich wie ein eindeutiger Name des Eintrags. Wenn man also einen neuen
Eintrag einfügen möchte, muss man neben dem Eintrag auch einen Schlüssel mitgeben. Beim Auslesen der Einträge wiederum, benötigen wir
nur den Schlüssel. Im Regelfall sind diese Konstrukte ungeordnet, was so viel bedeutet, als dass die Reihenfolge des Einfügens keine
Rolle für die Ausgabe spielt – sie existiert schlichtweg nicht. Intern existiert natürlich eine Struktur, welche für das möglichst
schnelle Auffinden der richtigen Elemente optimiert ist, meist eine Baumstruktur. Beginnen wir hier auch mit einem Java Beispiel der
Hashtable:
Listing 32: Asoziatives Array am Beispiel einer Hashtable in Java
Kurze Erklärung der Codezeilen: Die
Hashtable benötigt nun die Typinformation für zwei Klassen – der Klasse für den „Key“ und der für den eigentlichen Wert, dem „Value“.
Der Key wird üblicherweise mit einem String oder einem ganzzahligen Datentyp hinterlegt, es ist aber im Prinzip jede
Klasse(6) möglich. Die Daten werden mit
put eingefügt und mit
get wieder ausgelesen.
(6) Die gewisse Eigenschaften erfüllen muss – Details finden sich in der API Dokumentation von Java
Starten wir die Software erhalten wir erwartungsgemäß:
In Java gibt es neben der
Hashtable noch weitere Implementierungen dieses Prinzips, wie beispielsweise die
Hashmap. In C# existiert zwar auch eine
Hashtable, gebräuchlicher ist jedoch
Dictionary:
Listing 33: Asoziatives Array am Beispiel eines Dictionaries in C#
Und das Ganze nochmal in C++:
Listing 34: Assoziatives Array am Beispiel einer Map in C++
Wie immer, gleichen sich die Ansätze in gewissen Grenzen. Auch hier der Vollständigkeit halber noch die wichtigsten Befehle der
assoziativen Arrays in den drei Sprachen:
| Java: | C#: | C++: | Funktion: |
|---|---|---|---|
| new Hashtable<classK, classV>() | new Dictionary<classK, classV>() | std::vector<std::classK, classV> | Konstruktor – erzeugt ein leeres assoziatives Array, welches Objekte der Klasse „classK“ als Key und „classV“ als Value verarbeitet |
| new Hashtable<classK, classV>(cap) | new Dictionary<classK, classV>(cap) | existiert nicht | Konstruktor – erzeugt ein leeres assoziatives Array, welches Objekte der Klasse „classK“ als Key und „classV“ als Value verarbeitet, mit einer initialen Kapazität von „cap“. |
| .put(objK, objV) | .Add(objK, objV) | .insert(std::make_pair(objK, objV)) | Fügt „objV“ mit dem Key „objK“ ein. |
| .get(pos) | [pos] | [pos] | Liest das Objekt mit dem Schlüssel „objK“ aus. |
| .remove(pos) | .RemoveAt(pos) | .erase(pos) | Löscht den Eintrag mit dem Schlüssel „objK“. |
| .size() | .Count() | .size() | Gibt die Anzahl der Elemente aus. |
Tabelle 2: Wichtige Methoden der Java Hashtable, C# Dictionary und C++ map
Ein letzter Hinweis noch für die assoziativen Arrays. Da wir ja nur noch über Keys unsere eingetragenen Werte herauslesen können,
gibt es keine einfache Schleife mehr, mit der wir alle Elemente auslesen können. Wir müssen hierzu immer auch alle Keys wissen. Sowohl
in Java, C# als auch für C++ gibt es jedoch Ansätze, alle Keys auszulesen. Hierfür lässt man „Iteratoren“ oder „Enumeratoren“ erzeugen –
sogenannte „Aufzählungstypen“, mit deren Hilfe wir uns sequenziell alle Keys ausgeben lassen können. Wer hier tiefer einsteigen möchte
oder muss, der findet mit Suchanfragen wie bspw. „get all keys from Hashtable in Java“ relativ schnell gute Hinweise.
Strings - Objektorientiert
Doch gehen wir mit unseren zusammengesetzten Datentypen weiter voran. Wir wissen jetzt, wie die Arrays in Sprachen wie C# oder Java
behandelt werden. Kümmern wir uns nun um Texte – oder besser gesagt „Strings“. Wir haben ja in den vorausgegangenen Codebeispielen schon
Strings genutzt, aber noch nicht intensiver darüber gesprochen. Wie die Arrays auch, werden in den objektorientierten Programmiersprachen
die Strings als Objekte gehandhabt, was die ganze Sache erheblich vereinfacht. Die gesamte Mechanik der Prüfung, ob ein String in ein
char Array reinpasst oder nicht, entfällt hier. Die Objekte kümmern sich selbstständig darum. Sehen wir uns mal die Stringnutzung in Java an:
Listing 35: Stringnutzung in Java
Wie wir sehen müssen wir nicht vorher festlegen, wie groß der Text sein soll, der in der Stringvariablen einzutragen ist. Die erste
Codezeile würde übrigens in C# genauso aussehen. Wie das Array auch, haben die Stringobjekte Eigenschaften und Methoden, welche den
Umgang mit Strings erleichtern. Je nach Programmiersprache gibt es unterschiedliche Hilfsmethoden, die wir in der API-Beschreibung
nachlesen müssen. Sehen wir uns beispielhaft mal ein paar an. Gehen wir davon aus, dass wir aus einem String einen Teilstring extrahieren
wollen. Um den Vorteil der Objektorientierung zu sehen, blicken wir zuerst nochmal auf C. Hier könnten wir beispielsweise folgenden –
zugegebenermaßen nicht sehr performanten, aber funktionierenden – Code nutzen, der die ersten 5 Zeichen aus einem gegebenen String
schneidet(7):
(7) Wer es performanter haben möchte, sollte sich „memcpy()“ mal ansehen.
Listing 36: Einfache Substringerstellung in C
Kurze Erklärung der Codezeilen: Wir beginnen mit einer für uns neuen Initialisierung eines Strings.
stringVar[] übernimmt einfach „nur“ die Adresse des Konstantwertes „hallo welt“ und muss somit nicht mehr weiter definiert werden. Danach
erzeugen wir eine Variable für die Aufnahme eines 5-stelligen Strings mit abschließendem Terminatorzeichen. In der nächsten Zeile
finden wir eine Standardzählschleife, welche von 0 bis kleiner 5 zählt (Zählschleifen werden wir im Rahmen der Kontrollstrukturen noch
näher beleuchten). Die Variable
„i“ hat also im ersten Durchlauf die 0, dann die 1 usw. bis zur 4. Im Rumpf der Schleife (also zwischen den geschweiften Klammern)
übernehmen wir nun Zeichen für die Werte in die Variable
subStringVar. Nach der Schleife setzen wir den Stringterminator explizit (auf 0) und geben am Ende den Wert aus.
Die Ausgabe liefert uns somit den String „hallo“. Sehen wir uns exakt die gleiche Logik mal in Java an:
Listing 37: Substringermittlung über Arrays in Java
Dadurch, dass wir die nicht objektorientierte Methodik dem objektorientierten Code „überstülpen“, ist das Ergebnis unnötigerweise
verkompliziert worden. Wir sehen uns gleich eine einfachere Möglichkeit an. Gehen wir aber vorher durch den Code durch:
Kurze Erklärung der Codezeilen: Wir erzeugen und initialisieren wieder eine Stringvariable für den ganzen Text. Danach zerlegen wir den
Text in ein
char Array, um den gleichen Algorithmus wie in C zu ermöglichen. Nun bereiten wir das Zielarray mit 5 Einträgen vor.
Wir benötigen in Java keinen Stringterminator, da wir aus dem Array gleich einen „normalen“ String erzeugen und dort kein Terminator
benötigt wird. Danach folgt wieder eine Zählschleife, welche exakt so wie in C funktioniert. Nach der Schleife erzeugen wir aus dem Array
mit
new String(subStringArray) den benötigten String und geben ihn schließlich aus.
Die Java Mechanik erzeugt nun die gleiche Ausgabe „hallo“ wie unser C Code – nur eben umständlicher. Nun kommen die Hilfsmethoden der
Klasse
String ins Spiel. Streng genommen sind sie uns ja schon vorher begegnet, da der Code
stringVar.toCharArray() ja bereits eine Hilfsmethode darstellt. Die Beschreibung der Java API für das
String Objekt liefert uns unter anderem die Methode
substring(beginIndex, endIndex). Sie liefert also den Substring vom angegeben Startindex bis (exklusive) dem Endindex. Der Code
reduziert sich also auf den folgenden:
Listing 38: Objektorientierte Substring Ermittlung in Java
Das ausgegebene Ergebnis ist wieder „hallo“. Die gesamte Mechanik ist also in der Hilfsmethode
substring() vorab geschrieben worden. Das ist so weit recht praktisch – nur muss man eben wissen, welche Hilfsmethoden existieren,
weshalb man für die gerade genutzte Programmiersprache immer wissen muss, wo man nachsehen kann. Im Abschnitt über die Objektorientierung
werden wir noch sehen, wie wir eigene Hilfsmethoden generieren können. Sehen wir uns der Vollständigkeit halber auch nochmal den Code in
C# an:
Listing 39: Objektorientierte Substring Ermittlung in C#
Soweit nichts neues – wir haben ja schon öfter gesehen, dass in den einzelnen objektorientierten Sprachen das Rad nicht immer neu
erfunden wurde, zumal C# einige der recht erfolgreichen Ansätze von Java übernommen hat. Etwas anders sieht es da in C++ aus,
welche ja aus C hervorgegangen ist und als objektorientierte Erweiterung von C gehandelt wird. Aus diesem Grund funktioniert der Code
aus Listing 35 1:1 auch so in C++. Es ist aber auch möglich, in C++ einen
objektorientierten Ansatz des Codes umzusetzen:
Listing 40: Objektorientierte Substring Ermittlung in C++
Mal abgesehen von ein paar unterschiedlichen Syntaxregeln ist der allgemeine Ansatz der Objektorientierung wieder zu erkennen. Ist damit
C dem Untergang geweiht, weil es „zu umständlich“ ist? Nun, die Antwort ist „ja und nein“. Auf der einen Seite liefern uns die
C-Bibliotheken auch hilfreiche Funktionen für den Umgang mit Strings. Diese kann ich bei Bedarf auch noch erweitern. Darüber hinaus ist
C aufgrund des geringeren Overheads im Regelfall performanter als objektorientierter Code. Auf der anderen Seite ist Entwicklungszeit
oft bares Geld, weshalb man bei der Perfomance mitunter zugunsten schnellerer Entwicklungszyklen Abstriche macht. Der eigentliche
„Problemfall“ von C ist aber die Angst vor fatalen Fehlern in Code bezüglich der Adressarithmetik und der Speicherverwaltung, über die
wir später auch noch mal blicken müssen.
Bevor wir das Thema „Strings“ abschließen, müssen wir aber noch über ein oft unterschätztes Thema bei Strings sprechen – den Stringvergleichen.
Nun möchte man denken, dass der folgende Java Code relativ klare Ergebnisse liefern sollte:
Listing 41: Vergleich von verketteten Strings in Java
Kurze Erklärung der Codezeilen: Zuerst erzeugen wir drei Stringvariablen und initialisieren sie mit drei verschiedenen Werten. Danach
erzeugen wir drei weitere, indem wir die ersten drei mit
„+“ Verketten. Die Variable
string1 erhält dadurch den Wert „hallo welt“,
string2 auch „hallo welt“ und
string3 „hallo mars“. Danach geben wir die Variablenvergleiche, welche in Java mit
„==“ erfolgen, auf der Konsole aus. Wir vergleichen also zuerst
string1 mit
string2 und dann
string1 mit
string3.
Sehen wir uns das auf den ersten Blick überraschende Ergebnis an:
Java sagt mir also allen Ernstes, dass sich sowohl
string2 als auch
string3 von
string1 unterscheiden, obwohl
string1 und
string2 die gleichen Inhalte aufweisen sollten, nämlich „hallo welt“! Nun, um dieses Verhalten zu verstehen, müssen wir uns nochmal in
unseren Modellspeicher begeben.
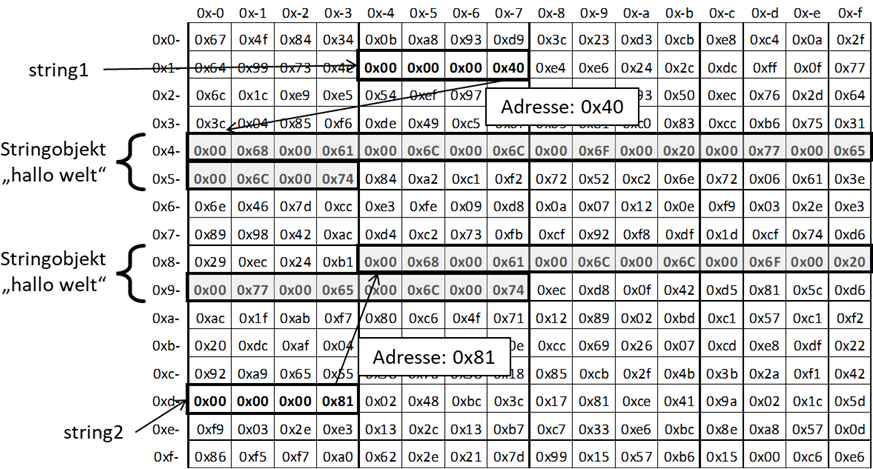
Abb.: 10: Ablage zweier identischer Stringobjekte in Java
Wie wir sehen, ist der Inhalt der Variablen
string1 nicht der Text „hallo welt“, sondern die Adresse, unter der dieser Text zu finden ist.
string2 beinhaltet eine andere Adresse – die zwar auch auf ein Stringobjekt mit dem Inhalt „hallo welt“ zeigt, aber eben unter einer
anderen Adresse. Dies bedeutet, dass in Java der Vergleich von zwei Objektvariablen zum Vergleich der Adressen führt. Dies ist
übrigens auch der Grund, warum ich
string1 und
string2 so „umständlich“ durch Verkettung aufbaue. Hätte ich den Code wie folgt geschrieben:
Listing 42: Belegung zweier Stringvariablen mit ein und demselben Objekt
hätte Java die Gleichheit der beiden Stringkonstanten bemerkt und sie nur einmal angelegt, wodurch beide die gleiche Adresse erhalten hätten.
Die Frage ist nun, ob das ein sinnvolles Verhalten ist, die Adressen zu vergleichen und nicht die Inhalte. Die Antwort ist wie so oft
„ja und nein“. Beginnen wir mit der „ja“ Antwort. Wenn wir den Code
„string1 == string2“ als Frage auf „ist es ein und dasselbe?“ interpretieren, ist die Antwort darauf in der Tat „falsch“, da es sich ja
um zwei verschiedene Objekte handelt. Die Tatsache, dass sich im
(Listing 42)
tatsächlich nur ein Objekt verbirgt wäre ohne diesen Ansatz nicht überprüfbar. Darüber hinaus ist die Frage, „was ist eigentlich gleicher
Inhalt?“ nicht so einfach beantwortbar. Ist beispielsweise der String „hallo welt“ der gleiche, wie „Hallo Welt“? Diejenigen, welche die Java
Sprache entwickelt haben konnten diese Frage wohl auch nicht beantworten, weshalb sie für den Vergleich zwei Hilfsmethoden erstellt haben – und
zwar
„equals()“ und
„equalsIgnoreCase()“. Sehen wir uns das im Code an:
Listing 43: Case sensitiver Vergleich von Strings in Java
Die Ausgabe ist nunmehr erwartbar, da der erste Vergleich "case sensitive" - also unter Berücksichtigung von Groß- und Kleinschreibung
durchgeführt wurde:
In Java ist der Objektvergleich mit
„==“ immer der Vergleich auf ein und dasselbe Objekt. Anderweitige Vergleiche müssen stets mit Hilfsmethoden durchgeführt werden, da
„Gleichheit“ vom Anwendungsfall abhängt. Wie sieht das Ganze nun in C# aus? Nun hier hat man sich für einen anderen Weg entschieden. Man geht
davon aus, dass ein Vergleich immer auf die Inhalte abzielt.
Listing 44: Vergleich von verketteten Strings in C#
Die Ausgabe hier ist anders als in Java:
C# vergleicht also nicht die Adressen! Der Grund liegt darin, dass die Entwickler von C# den
„==“ Operator mit einer anderen Funktionalität „überladen“ haben. Intern wird
„string1 == string2“ mit der gleichen Routine verarbeitet wie
„string1.Equals(string2)“. Das heißt, der Compiler setzt intern die beiden Codevarianten in die gleiche Funktionalität um.
Diese vergleicht dann die beiden Strings case sensitive. Wenn wir case insensitive vergleichen wollen, wird eine andere Form von
„Equals“ benötigt, welche allerdings nicht mit
„==“ ersetzbar ist:
Listing 45: Case insensitiver Stringvergleich in C#
Wenn man es dann noch genauer nehmen möchte, kann man noch kulturelle Eigenheiten berücksichtigen lassen, wobei dies den Rahmen hier
sprengen würde und für den Anfang unserer Programmiererkarriere auch keine große Rolle spielt. Details können wie immer aus der
API-Beschreibung entnommen werden. Widmen wir uns nun noch kurz der C++ Variante und sehen, wie es hier gelöst wird:
Listing 46: Vergleich von verketteten Strings in C++
Auch hier erstmal keine besonderen Neuigkeiten. Lediglich bei der Ausgabe ist für C# und Java Programmierer aufgrund der internen
Verarbeitung von bool in C++ eher ungewohnt:
Wir erinnern uns: C++ übernimmt 1 als true und 0 als false. Ansonsten zeigt C++ das gleiche Verhalten wie C# in Puncto Stringvergleiche mit
„==“. C++ bietet übrigens in der String Klasse keine direkte Hilfsmethode für einen case insensitive Stringvergleich. Diese müssen
entweder selbst geschrieben oder eine entsprechende Bibliothek für einen solchen Vergleich eingebunden werden.
Für die wichtigsten Stringfunktionalitäten in Java, C#, C++ und C habe ich hier ein paar Methoden und Funktionen zusammengetragen, wobei
„s1“ und
„s2“ jeweils für einen beliebigen String steht:
| Funktion: | Java: | C#: | C++: | C: |
|---|---|---|---|---|
| Vergleich (case sens.) | s1.equals(s2) | s1==s2 | s1==s2 | strcmp(s1,s2) |
| Substring | s1.substring(…) | s1.Substring(…) | s1.substr(…) | - |
| Teilstring suchen | s1.indexOf(s2) | s1.IndexOf(s2) | s1.find(s2) | - |
| Länge des Strings | s1.length() | s1.Length | s1.length() | - |
| Alles zu Großbuchst. | s1.toUpperCase() | s1.ToUpper() | - | - |
| Alles zu Kleinbuchst. | s1.toLowerCase() | s1.ToLower() | -/td> | - |
Tabelle 3: Ausgewählte String Funktionalitäten
Wie man sieht, ist bei der Programmiersprache C die Spalte kaum gefüllt – man muss sich hier die Funktionalitäten meist selbst erstellen
oder entsprechende Bibliotheken einbinden, welche die gewünschten Funktionen mitliefern. Die objektorientierten Programmiersprachen sind da
besser bestückt und ähneln sich durchaus in der Funktionalität. Insofern wird ein Java Programmierer keine großen Probleme haben, sich mit
C# zurechtzufinden und umgekehrt.
Einen letzten Punkt bei den beiden objektorientierten Programmiersprachen Java und C# möchte ich aber noch anbringen. Die Strings dieser
beiden Programmiersprachen sind „immutable“, sprich unveränderbar. Das bedeutet, dass wenn ein String einmal erzeugt wurde, man diesen
nicht verändern kann. Dies kann man mit folgendem Code – erstmal in C++, wo Strings nicht immutable sind, veranschaulichen:
Listing 47: Stringergänzung in C++
Kurze Erklärung der Codezeilen: In die Stringvariable
stringVar schreiben wir einen Text „hallo “ und hängen danach „welt“ hinten dran. Am Schluss geben wir
stringVar wieder aus.
Nun versuchen wir das Ganze mit Java (in C# ist die einzige Möglichkeit etwas anzuhängen der „+“ Operator):
Listing 48: Stringergänzung in Java
Sehen wir uns auch hier das Ergebnis an:
Das „welt“ wurde also nicht angehängt. Der String
stringVar hat sich also nicht verändert. Nun, was soll jetzt aber die Methode
„concat“ eigentlich bewirken. Die Lösung hierzu sehen wir im folgenden Code:
Listing 49: Stringergänzung in Java – jetzt richtig
Und jetzt haben wir erst das erwartete Ergebnis:
„concat“ hängt schon etwas an den String
„stringVar“ dran, ändert ihn aber nicht. Stattdessen wird ein neuer String erzeugt und diesen speichern wir in der Variablen
„stringVar2“. Zugegebenermaßen nutzen wir
concat eher nicht, sondern gehen mit dem „+“ Operator vor, wie in C# - aber hier lässt sich das unterschiedliche Verhalten von
C#/Java und C++ am besten Zeigen. Dieses Verhalten hat nun aber eine recht unschöne Nebenwirkung. Sehen wir uns das mal im Detail in
Java an (da hier die interne Adressierung relativ einfach auszulesen ist):
Listing 50: Unveränderbarkeit von Strings in Java
Kurze Erklärung der Codezeilen: Zuerst wird
stringVar mit einem Stringwert initialisiert. Danach lassen wir mit der Methode
identityHashCode() die interne ID des Objektes ausgeben, mit deren Hilfe Java die einzelnen Objekte innerhalb der Virtuellen Maschine
adressiert. Danach hängen wir einen leeren String an.
„+=“ bedeutet soviel wie „nehme den String auf der linken Seite und hänge den String auf der rechten Seite hinten dran“. Dadurch ändert
sich der Inhalt von
stringVar nicht. Wenn wir nun die interne ID wieder ausgeben, sehen wir, ob intern ein neues Objekt erstellt wurde, oder nicht.
Mit anderen Worten: in Java (und C#) wird bei der Änderung eines Strings immer ein neuer String erzeugt! Wenn wir bei den Filezugriffen
sind sehen wir, dass dies beim zeichenweisen Einlesen von großen Files ein Problem für das Speichermanagement sein wird, da der Computer
die vielen „alten“ Stringobjekte ja wieder los werden muss. So viel vorab – es gibt mit Hilfe von Stringbuffern die Möglichkeit dieses
Problem zu umgehen. Doch davon später mehr.
Stellen wir uns für den nächsten Punkt in Sachen Strings folgende Situation vor. Wir haben eine Eingabemaske für Informationen – sagen wir
das Alter soll eingegeben werden. Wir wollen nun prüfen, ob der User volljährig ist – sprich mindestens 18, oder minderjährig, also unter 18.
In Java können wir bspw. eine sehr einfache Eingabemechanik für Usereingaben verwenden, das
JOptionPane.showInputDialog(). Hier geben wir einen beliebigen Text ein und können diesen Text in einer Variablen speichern. Da wir aber
nicht ahnen können, ob der User nun Zahlen oder einen beliebigen Text eingibt, ist der Rückgabetyp dieser Funktionalität
„String“. Einen String können wir aber bezüglich des Größenvergleiches nicht wie eine Zahl behandeln, weshalb wir den String in einer Zahl
„umwandeln“ müssen. Dies ist aber kein Typecast, da wir den String analysieren müssen und dann die Zahl daraus „interpretieren“. Diesen
Vorgang der Stringanalyse und der anschließenden Extraktion von Informationen nennt man „Parsen“. Sehen wir uns den entsprechenden Code
hierzu an:
Listing 51: Beispiel für Stringparsing
Kurze Erklärung der Codezeilen: Da die
JOptionPane nicht im Standardkontext vorhanden ist, müssen wir den Ort
javax.swing.* über den
import bekannt machen. Mit
JOptionPane.showInputDialog("Eingabe Alter:") wird ein kleiner Popup Dialog erstellt, der die Eingabe einfordert. Was immer der User
eingibt und mit „OK“ bestätigt, wird durch die Zuweisung in
sEingabe übergeben – und zwar als
String. Nun wandeln wir den String über
Integer.parseInt() in eine Zahl um. Wenn der User etwas eingibt, was keine int Zahl ist, würde das Programm hier abstürzen – was aber für
unseren Test OK ist. Nun können wir den geparsten Wert in
iAlter ablegen und prüfen.
Wenn wir das Programm starten, dann sehen wir die Eingabemaske. Geben wir nun eine Zahl kleiner 18 ein, erscheint „Minderjährig“, bei einer
Zahl größer oder gleich 18 entsprechend „Volljährig“. In C# wäre die Parsefunktion unter
„Int32.Parse(sEingabe);“ zu finden, unter C++ gibt es die Funktion
„std::stoi(sEingabe);“ oder bei
char* Zeichenketten den C-Weg über
„atoi(sEingabe)“.
Structs
Die letzte Notwendigkeit für „zusammengesetzte“ Daten machen wir uns am folgenden Beispiel klar. Gehen wir davon aus,
dass wir die Position von Personen – sagen wir Spieler in einem Spielfeld – tracken möchten. Hierzu benötigen wir für
jeden Spieler drei Informationen: X-Koordinate, Y-Koordinate und den Namen des Spielers.

Abb.: 11: Kombinierte Informationen pro Element
Diese drei Informationen möchten wir jetzt in einem Array halten – allerdings wollen wir pro Array Eintrag alle drei
Informationen in einer Einheit verwalten. Eine recht einfache Möglichkeit wäre, die drei Informationen in einem
zweidimensionalen Array zu speichern:

Abb.: 12: Datensätze in zweidimensionalen Array
Diese Vorgehensweise hat aber einen entscheidenden Nachteil. Die Namen müssen als Strings abgelegt werden – es gibt
hier keine Alternative(8). Da in einem zweidimensionalen Array die Datentypen in allen
Spalten aber gleich sein müssen sind wir gezwungen, auch die X und Y Koordinaten als Strings abzulegen. Das ist
sehr unpraktisch, da wir mit Strings nicht rechnen können. Das heißt, wir können nicht ohne weiteres die Abstände
zwischen den einzelnen Spielern berechnen, sondern müssten bei jedem Zugriff erst den String in einen int Wert parsen.
Wir benötigen also eine andere Möglichkeit, diese drei Informationen zu bündeln. In der Programmiertechnik finden wir
hier zwei unterschiedliche Konzepte, je nachdem ob wir objektorientiert oder strukturiert/prozedural programmieren.
Beginnen wir mit dem Ansatz für nicht objektorientierte Programmiersprachen und greifen uns hier wieder C heraus.
C erlaubt es uns, sogenannte „Strukturen“ zu erstellen. Dies sind Elemente, welche eine Klammer um die verschiedensten
Variablen bilden. Sehen wir uns den Code für unser Datenproblem an:
(8) Zumindest in den statisch typisierten Programmiersprachen
Nutzung eines struct in C
Kurze Erklärung der Codezeilen: Mit
„typedef“ kann man einem Datentyp oder einer Struktur einen eigenen Namen geben – in unserem Fall wollen wir ein
neues
„struct“ benennen. In den geschweiften Klammern reihen wir die einzelnen Teilinformationen mit entsprechenden
Datentypen auf. Dies können alle bis dahin bekannten Datentypen sein (also auch structs, welche vorher definiert
wurden). Beim Namen setzen wir einfach einen
char Pointer, da wir den Namen später nicht ändern wollen. Danach erzeugen wir eine Variable
„p1“ vom Typ
„player“, was ja unser neu erzeugtes
struct ist. Der Zugriff auf die inneren Elemente des structs erfolgt mit dem „Punktoperator“. Insofern können wir
die Elemente mit Werten belegen und auch wieder ausgeben.
Die Ausgabe sollte dadurch nachvollziehbar sein:
Wir können die Spieler somit auch in ein Array eintragen – hier beispielhaft mit den ersten beiden:
Listing 53: Array of struct in C
Es ist zugegebenermaßen in dem Programm kein großer Vorteil darin zu erkennen, Arrays zu nutzen. Wenn wir uns aber später
mit Schleifen beschäftigen, werden wir sehen, dass wir die Zugriffe auf unsere Arrays sehr viel kompakter programmieren können.
Jetzt, da wir das
struct verstanden haben, muss ich noch auf ein in C relativ häufig genutztes Konzept eingehen, den verketteten
Listen. Die Idee ist hier, dass wir ein
struct realisieren, welches einen Zeiger auf ein weiteres
struct beinhaltet. Hierdurch können wir eine Kette bilden:

Abb.: 13: Verkettete Liste
Diese verkettete Liste (oder engl. „linked list“) benötigt also ein
struct, in dem die Referenz auf das nächste Element als Zeiger abgelegt werden kann und darüber hinaus die eigentlichen
Daten, die als Liste abgelegt werden sollen („Payload“). Sehen wir uns ein einfaches Beispiel hierzu mal an:
Listing 54: Verkettete Listen in C
Kurze Erklärung der Codezeilen: Das
struct muss einen Namen bekommen, damit wir intern wieder darauf verweisen können
(elmt). Unsere Payload soll ein Text sein und
next ein Zeiger auf ein
„struct namens
elmt“. Damit ich später bei der Erzeugung auf
„struct namens
elmt“ verzichten kann, mache ich mit
typedef einen Datentyp namens
„element“ daraus. Nun erzeuge ich in der main Funktion einen Zeiger auf ein
element in der Variable
el0, was unser nulltes Element darstellt (mitunter auch „Kopf“ „root“ oder „header“ genannt). Nun muss ich C noch
explizit sagen, dass ich einen Speicherplatz für dieses Element benötige, was ich mit
malloc() mache (weshalb auch
stdlib.h benötigt wird). Damit der Rechner aber weiß, wie viel Speicherplatz benötigt wird, nutze ich hierfür die
Funktion
sizeof(), welche als Parameter entweder ein Datentypkonstrukt oder ein Zeiger für die Ermittlung des belegten
Speicherplatzes erwartet. Nach der Speicherplatzreservierung kann ich nun Werte eintragen. Der
next Wert sollte immer definiert sein, weshalb ich immer gleich
NULL eintrage – es wird also nicht auf ein nächstes Element gezeigt. Nun erzeuge ich auf die gleiche Weise ein
weiteres Element
el1. Jetzt kann ich den Zeiger von
el0->next auf das neue Element
el1 zeigen lassen (der Zugriff auf Zeiger in
structs wird über
„->“ realisiert). Danach wird ein weiteres Element angehängt. Für die Ausgabe erzeuge ich eine Variable für die
Verarbeitung
myEl und lasse sie auf das nullte Element zeigen. Solange nun in
myEl keine
NULL steht, kann ich die Payload ausgeben. Nach der Ausgabe setze ich den Zeiger von
myEl auf das nächste Element – eben bis hier
NULL steht.
Die Ausgabe des Codes lautet somit:
Structs sind in C also ein wesentliches Element, um überhaupt sinnvoll und wie der Name schon sagt „strukturiert“
zu arbeiten. Wie sieht das Ganze denn nun in objektorientierten Sprachen aus? C++ und C# kennen das Konzept von
struct auch. Man kann also dort den „klassischen“ Weg über
struct gehen oder über den Objektweg in Form von Klassen. Bevor ich nun auf den objektorientierten Weg eingehe, noch
ein kurzer Hinweis für C++ und C#, wann ein
struct sinnvoller ist und wann eine Klasse. Klassen sind „komfortabler“ in der Nutzung, da wir beim Belegen von
Werten auch Funktionalitäten hinterlegen können, sogenannte „Setter“ – was wir im Teil „Objektorientierung“ näher
betrachten werden. Structs hingegen haben eine sehr viel einfachere Speicherstruktur, weshalb sie in puncto
Performance schneller sind als Klassen und Objekte. Sehen wir uns nun mal eine objektorientierte Lösung für unsere
Spielerdaten an, wobei ich nur dort auf das
Kapitel über die Objektorientierung
vorgreife, wo es für die Erklärungen hier notwendig ist. Zuerst erstellen wir uns eine Klasse für die Spieler:
Listing 55: Klasse als Datencontainer in Java
Kurze Erklärung der Codezeilen: Das ganze Konstrukt ist eine sogenannte „Klasse“, weshalb wir die Schlüsselwörter
public class benötigen. Innerhalb der Klasse reihen wir wieder – wie im struct auch – die einzelnen Datentypen
nacheinander.
Diese Klasse würden wir in ein eigenes File auslagern. Die Nutzung der Klasse sieht dann wie folgt aus:
Listing 56: Nutzung einer Klasse als Datencontainer in Java
Kurze Erklärung der Codezeilen: Das einzig wirklich neue ist
„new Player()“. Mit diesem Befehl erzeugen wir im Speicher ein neues Objekt aus der Klasse
„Player“. Die Nutzung ist auf den ersten Blick genauso wie die struct Nutzung in C.
Mit Ausnahme der Ausgabe ist der Code in Java und C# identisch. Wie in C auch, können wir jetzt in Java
oder C# auch ein Array aus diesen Objekten bilden:
Listing 57: Array of Object in Java
Kurze Erklärung der Codezeilen: Auch hier erkennen wir die Parallelen zu C. Das Einzige, worauf man
hier wirklich achten muss ist, dass wir für jeden Arrayeintrag mit
new Player() das Objekt wirklich erzeugen müssen. Bei der Erzeugung des
allPlayer Arrays wird in Java und in C# das Array mit null Werten initialisiert, wie wir es schon bei den
„Arrays von Arrays“ gesehen haben.
So weit haben wir nun die wichtigsten Möglichkeiten gesehen, Daten strukturiert im Speicher abzulegen, womit wir einen
großen Schritt in Richtung Programmierung gegangen sind.

CC Lizenz (BY NC SA)