
Speicher – von Stapeln und Haufen
Man unterscheidet bei der Programmausführung zwei grundsätzliche Speicherbereiche – den Stack Speicher und den Heap Speicher. Es ist
als Programmierer zwar nicht kriegsentscheidend diese beiden Speicherbereiche voneinander unterscheiden zu können aber ein gewisses
Grundverständnis kann an dieser Stelle nicht schaden.

Stack vs. Heap
Versuchen wir erstmal die beiden Speichertypen zu klassifizieren. Wie der Name schon sagt, ist der „Stack“ ein Stapelspeicher. Es
werden Dinge von unten nach oben übereinandergestapelt und von oben wieder entfernt. In diesem Speicher werden im Regelfall die
aufgerufenen Unterprogramme abgelegt. Wurde das Programm abgearbeitet, wird dieser Speicher wieder freigegeben. Solche Speicher nennen
wir auch „LIFO“ Speicher (Last In First Out). „Heap“ hingegen lässt sich als „Haufen“ übersetzen. Das hört
sich schon mal unstrukturierter an – erforderte aber für die Designer der Systeme einen sehr viel höheren Aufwand, diesen Speicher zu
realisieren. Der Heap ist also kein „LIFO“ Speicher, sondern ermöglicht dem Systemen eine komplett selbstbestimmte Allokation und
Deallokation der Ressourcen – sprich das System oder der Programmierer ist in der Lage selbst zu bestimmen, wann ein Heap Speicherbereich
reserviert wird und wann es dieser wieder freizugeben ist. Hier gibt es wieder immense Unterschiede zwischen Java/C# und C/C++.
Beginnen wir wieder mit den Grundlagen und starten mit C. Sehen wir uns hierzu das folgende Programm an:
Listing 1: Unterschied Stack und Heap Memory Allokation
Kurze Erklärung der Codezeilen: Ganz oben erzeugen wir einen Pointer auf einen Integer Wert
("*myVar"). Dieser befindet sich außerhalb jeglicher
Unterprogramme, wodurch sie zu einer globalen Variablen wird. „Global“ bedeutet, dass jeder innerhalb dieses Programms immer auf diese
Variable zugreifen kann. Wir werden diese Variable als Testablage für unsere Variablen innerhalb der Unterprogramme nutzen. Danach folgen
zwei Unterprogramme. Beide haben die Aufgabe, eine Variable mit dem Wert 123 zu erzeugen – wobei eine Methodik die Variable im Stack
ablegt
createIntStack() und die andere im Heap
createIntHeap().
createIntStack() erzeugt eine „ganz normale“
int Variable und legt den Wert 123 dort hinein. Danach wird die Adresse dieser Variablen
(also &iHeap) in die globale
myVar geschrieben, so dass dort nun eine Referenz auf unsere Variable
„iHeap“ vorliegt.
Im createIntHeap wird einfach nur ein Pointer auf einen int Wert erzeugt – aber noch ohne den eigentlichen Wert. Mit malloc() wird nun ein Speicherbereich reserviert, in dem ein int Wert abgelegt werden kann, weshalb „sizeof(int)“ als Parameter benötigt wird. Die malloc() Funktion liefert einen Zeiger auf diesen Bereich zurück, den wir in unserer “iHeap“ Variablen speichern. Damit das funktioniert, müssen wir mit (int *) auf den richtigen Datentyp „wandeln“(1). Nun können wir dort wieder den Wert 123 ablegen und die Adresse auch in myVar schreiben.
Die dritte Funktion ist „fillMemory()“, in der einfach nur ein Speicherbereich mit irgendetwas vollgeschrieben wird. Es handelt sich hier um eine Zählschleife, welche 100 Einträge im Array iArray durchläuft und beschreibt.
Die main Funktion schließlich ruft die anderen Unterprogramme auf. Zuerst rufen wir createIntStack() auf. Danach fillMemory() und geben dann den Inhalt aus, auf den myVar zeigt.
Im createIntHeap wird einfach nur ein Pointer auf einen int Wert erzeugt – aber noch ohne den eigentlichen Wert. Mit malloc() wird nun ein Speicherbereich reserviert, in dem ein int Wert abgelegt werden kann, weshalb „sizeof(int)“ als Parameter benötigt wird. Die malloc() Funktion liefert einen Zeiger auf diesen Bereich zurück, den wir in unserer “iHeap“ Variablen speichern. Damit das funktioniert, müssen wir mit (int *) auf den richtigen Datentyp „wandeln“(1). Nun können wir dort wieder den Wert 123 ablegen und die Adresse auch in myVar schreiben.
Die dritte Funktion ist „fillMemory()“, in der einfach nur ein Speicherbereich mit irgendetwas vollgeschrieben wird. Es handelt sich hier um eine Zählschleife, welche 100 Einträge im Array iArray durchläuft und beschreibt.
Die main Funktion schließlich ruft die anderen Unterprogramme auf. Zuerst rufen wir createIntStack() auf. Danach fillMemory() und geben dann den Inhalt aus, auf den myVar zeigt.
(1) Das ist nichts anderes als ein „Typecast“, wie wir ihn schon besprochen haben.
Wenn wir das Programm ausführen, sehen wir – zumindest auf meinem Rechner(2) – folgende Ausgabe:
(2) Auf anderen Rechnern könnte das Stack Management anders verlaufen.
Zu erwarten wäre aber 123 gewesen. Nun, was ist passiert? Wir haben mit
createIntStack() die Variable
„iStack“ im Stack Speicher erzeugt und mit einem Wert belegt. Wenn wir nun aus dem Unterpogramm
createIntStack() herausgehen, dann wird dieser Speicher wieder freigegeben.
fillMemory() greift sich nun neuen Speicherplatz und schreibt irgendwelche Werte dort hinein – der alte Wert 123 wird im Regelfall
überschrieben. Löschen wir im
main Programm den Aufruf
fillMemory(), so finden wir die 123 als Ausgabe – das Programm hatte ja keine weiteren Befehle mehr, welche eventuell den
Speicherplatz überschreiben. Fügen wir
fillMemory() wieder ein und tauschen den
createIntStack() Aufruf durch
createIntHeap() aus, so lässt sich dieser Effekt nicht beobachten, 123 steht trotz Aufruf von
fillMemory() noch als Ausgabe auf der Konsole.
In C lässt sich somit über Stack und Heap Memory folgendes festhalten(3):
- Stack ist der Speicherort, in dem die einzelnen Unterprogramme während des Aufrufs die Daten ablegen.
- Wenn das Unterprogramm nicht mehr aktiv ist, wird der Speicher automatisch wieder freigegeben.
- Heap ist der Speicherort, in dem Daten unabhängig von den Unterprogrammen abgelegt werden können.
- Heap Speicher muss in C vom Programmierer allokiert werden, wozu die Funktion malloc() genutzt wird.
- Heap Speicher wird nicht automatisch wieder freigegeben.
(3) Den statischen Speicher rechnen wir der Einfachheit halber zum Stack dazu, was für den Programmierer eine vertretbare
Vereinfachung darstellt.
Sehen wir uns nochmal eine modellhafte Speichernutzung für den Fall an, dass unser Hauptprogramm folgende Unterprogramme
(in dieser Reihenfolge) aufruft:
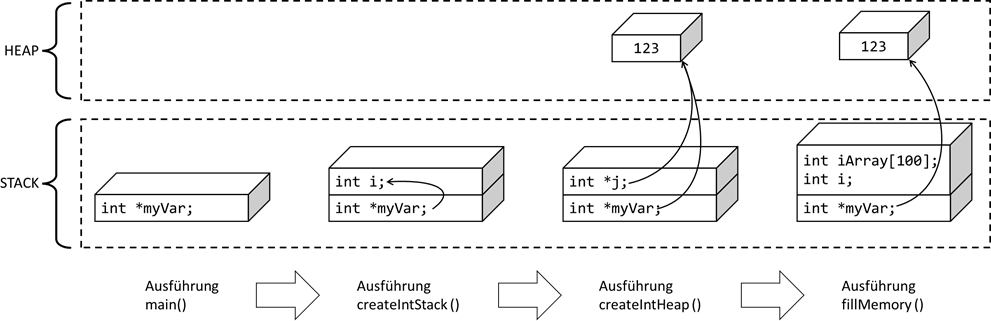
Abb.: 1: Abbildung 1: Stack vs. Heap in C
Während der
main() Ausführung existieren alle Variablen im Main Programm (sofern vorhanden) und die globalen Variablen, wie bspw.
„myVar“. Beim Aufruf von
createIntStack() existieren die Main- bzw. globalen Variablen immer noch, da
main() ja noch ausgeführt wird und zusätzlich existieren die Variablen in
createIntStack() – bei uns ist dies die Variable
„i“.
myVar zeigt nun durch die Zuweisung auf den Speicherplatz der Variablen
„i“. Nach der Ausführung von
„createIntStack()“ wird der Speicherplatz der Variablen
„i“ wieder automatisch freigegeben,
myVar zeigt aber immer noch auf diesen Speicherplatz. Bei der Ausführung von
„createIntHeap()“ wird der freigegebene Stack Bereich wieder mit neuen Daten gefüllt – in unserem Fall mit
„*j“. In den Inhalt dieser Pointervariablen wird nun dieses mal eine Adresse im Heap abgelegt, der vorher durch
malloc() reserviert („allokiert“) wurde. Der Inhalt der
myVar Variable wird jetzt ebenfalls auf diese Speicheradresse gesetzt. Nach Beendigung von
„createIntHeap()“ wird nun die Variable
„*j“ wieder freigegeben – wir hätten also die Adresse „vergessen“, wenn wir sie nicht in die Variable
„myVar“ hineinkopiert hätten. Somit bleibt die Möglichkeit bestehen, auf diesen Wert später nochmal zuzugreifen (oder eben
auch mit
free() freizugeben). Wenn
fillMemory() läuft, werden zwei Variablen im Stack abgelegt, und zwar das Array und die Zählvariable
„i“, wodurch wir aber kein Problem mit
myVar haben, da diese ja auf den Heap zeigt und dort neue Variablen nur mit einer Allokation erzeugt werden können, welche
aber immer nur freie Speicherplätze verwendet.
Objektorientierte Sichtweise
Die nächste logische Frage muss nun sein, unterscheiden C# und Java überhaupt so etwas wie Stack und Heap, da sie ja nicht auf Zeiger
bauen und Funktionen wie
malloc() gar nicht existieren. Die Antwort ist „ja, aber anders“. In diesen Programmiersprachen entscheidet der Datentyp, wo die
Daten gespeichert werden. Als Faustregel kann man sagen, dass alle Variableninhalte im Stack gespeichert werden, wenn während der
Ausführung von Unterprogrammen Daten dort abgelegt werden. Unter „Variableninhalte“ verstehen wir die tatsächlichen Werte der
primitiven Datentypen wie
int,
double etc. und die Adresswerte bei Variablen der zusammengesetzten Datentypen wie bspw. Arrays oder Strings. Im Heap landen wiederum
die eigentlichen Objekte, sobald sie erzeugt werden, bspw. mit
„new int[10]“. Die nächste Frage ist nun, wie werden die Heap Speicherplätze wieder freigegeben? Hier kommt ein Konzept ins Spiel,
welches das „Memory Leakage“ zur Vergangenheit angehören lässt, der sogenannte „Garbage Collector“ – also „Müllsammler“. Man kann
sich den Algorithmus vereinfacht so vorstellen, dass dieser automatisch alle Speicherzellen der Objekte freigibt, welche nicht mehr
referenziert werden. Das entspricht zwar nicht ganz der Wahrheit, da beispielsweise Objekte sich gegenseitig referenzieren können
und trotzdem nicht mehr zugreifbar sein – also eine Art „Insel“ bilden – aber für das grundsätzliche Verständnis reicht diese
Vorstellung auf jeden Fall aus. In der Praxis wird ein sogenannter „Mark and Sweep“ Algorithmus angewendet, welcher vom Root Objekt
aus – also dem Hauptprogramm – die einzelnen Referenzen alle durchgeht und alle in dieser Routine gefundenen Objekte markiert. Alle
nicht markierten werden im Anschluss freigegeben. Da dieser Algorithmus durchaus einiges an Performance kostet, sehen C++
Programmierer ihren Weg, sich selbst um die Freigaben zu kümmern, als absolut sinnvoller an. Im Prinzip geht es aber um die
Abwägung Performance gegenüber Softwarestabilität. In fast allen modernen Programmiersprachen hat man sich für die Stabilität
entschieden und einen Garbage Collector eingebaut. Sehen wir uns deshalb das Ganze nochmal beispielhaft an:
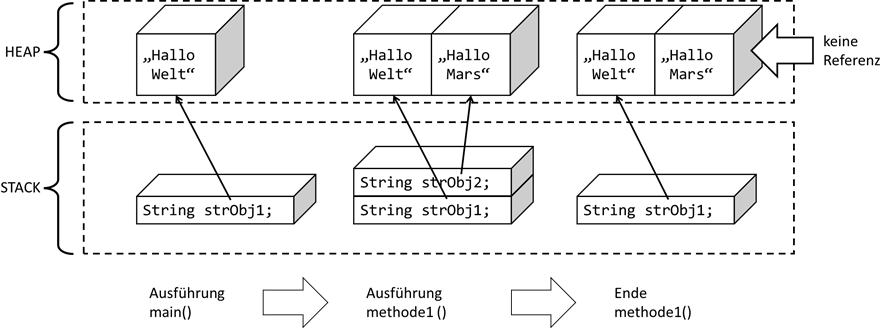
Abb.: 2: Unreferenzierte Objekte
In Abbildung 2 wird zuerst die
main Methode aufgerufen. Dort wird ein Stringobjekt
strObj1 erzeugt und referenziert. Danach folgt der Aufruf eines Unterprogramms
methode1(), in der ein zweites Stringobjekt
strObj2 erzeugt und referenziert wird. Wenn nun dieses Unterprogramm beendet wird, so existiert die Referenz auch nicht mehr,
wodurch danach das Objekt
strObj2 unreferenziert ist. Wenn aber niemand mehr die Adresse dieses Objektes besitzt, kann auch niemand mehr das Objekt nutzen,
weshalb es vom Garbage Collector entfernt werden kann – der Speicherplatz wird wieder freigegeben. Der Vollständigkeit halber
hier nochmal ein Javacode, welcher diese Situation hervorrufen würde. Der Einfachheit halber habe ich die Stringobjekte als
Konstantwerte erzeugt – was streng genommen ein Sonderfall darstellt, aber das gleiche Ergebnis zur Folge hat.
Listing 2: Objektreferenzen in Java
Ohne weiteres Zutun wird der Garbage Collector dann aktiv, wenn die virtuelle Maschine es für sinnvoll hält. Dies ist für die
meisten Fälle ok, für manche ist es störend – vor allem wenn eine zeitlich absolut störungsfreie Abarbeitung des Codes notwendig
ist, wie bspw. bei bewegten Grafiken. Hier kann es passieren, dass die Verarbeitung der Garbage Collector Routinen zu kurzen
Verarbeitungsverzögerungen führt. Abhilfe kann hier das bewusste Antriggern des Garbage Collectors schaffen. Alternativ können
auch Objektreferenzen global gehalten werden, damit die entsprechenden Objekte wiederverwendet werden können und somit kein Fall
für den Garbage Collector werden.
Destruktoren
Nun haben wir das Thema in Java/C# und in C behandelt. Wie funktioniert es aber in C++, welches von der Historie her irgendwo
zwischen C und Java/C# liegt? Nun, zum einen setzt C++ ja bekanntlich auf C auf, was die Nutzung von
malloc() genauso erforderlich macht, sofern wir primitive Datentypen oder
struct in C++ im Heap ablegen wollen oder müssen. Die Objekte, welche wie in Java/C# mir
„new“ erzeugt werden, sind ebenfalls im Heap abgelegt. Nun gibt es aber einen wesentlichen Unterschied zwischen C++ und Java/C#.
Da C++ die Option der dynamischen Allokation von Speicherplatz von C geerbt hat, benötigen wir einen Ort in unseren Objekten,
wo dieser auch wieder freigegeben werden kann. Dieser „Ort“ ist der sogenannte „Destruktor“, was ein Codeblock ist, welcher vom
Programmierer mit eigenem Code gefüllt werden kann. Dort muss sich der Programmierer darum kümmern, vom Objekt während seiner
Lebenszeit allokierten Speicherplatz wieder freizugeben. Der Destruktor wird dann vom System aufgerufen, sobald das Objekt
„stirbt“, was schlichtweg bedeutet, dass das Objekt keine Referenzen mehr aufweist. Sehen wir uns das mal im Code an:
Listing 3: Speichermanagement in C++ bei lokalen Objekten
Kurze Erklärung der Codezeilen: Dies ist ein kleiner Vorgriff auf die Objektorientierung – und zwar im C++ „Stil“.
Ganz oben referenzieren wir die notwendigen Bibliotheken für die Ausgabe. Danach erzeugen wir eine Klassendefinition –
die Klasse soll
TestObject heißen. Hier möchten wir einen sogenannten Konstruktor
TestObject() haben (der bei Erzeugung des Objektes aufgerufen wird) und einen Destruktor
~TestObject(), der bei der Löschung des Objektes aufgerufen wird. Zum „Beweis“, dass das Objekt existiert, möchte ich
noch eine einfache Methode haben, welche schlichtweg eine Ausgabe macht. Weiterhin soll die Klasse noch eine
Inzanzvariable
„iValue“ vorsehen (also eine Variable die existiert, solange das Objekt existiert), welche einen Zeiger auf einen
int Wert darstellt. Somit können wir den int Wert im Heap erzeugen. Das ist zugegebenermaßen etwas umständlich,
es geht hier aber ohnehin nur um das prinzipielle Verhalten von Destruktoren im Zusammenhang mit Freigabe von
Speicherplatz. In der
main Methode habe ich eine Schleife eingebaut, die zweimal durchlaufen wird. Innerhalb der Schleife (also innerhalb
des Kontexts der beiden geschweiften Klammern) wird das Objekt erzeugt, durch
TestObject myObj.
„new“ nutze ich hier nicht, da ich das Objekt erstmal nicht im Heap haben möchte – eine der Varianten von C++,
die in C# und Java nicht existieren. Die Variable heißt also
myObj und beinhaltet ein Objekt des Typs
TestObject. Durch diesen Code wird der Konstruktor
TestObject::TestObject() aufgerufen. Zur Kontrolle wird erst einmal eine kurze Ausgabe gemacht. Danach wird ein
Speicherplatz über
malloc() erzeugt, die Adresse an die Instanzvariable
iValue übergeben und mit dem Wert 1 belegt (die
if - Abfrage ist nur zur Sicherheit, dass
malloc() auch erfolgreich war).
Nun geht es in der Schleife weiter und die Methode printValue() wird aufgerufen, welche den Inhalt ausgibt, auf den iValue zeigt. Danach beginnt die Schleife von neuem. Da aber nach jedem Ablauf der Kontext geschlossen wird, gibt C++ das Objekt auch nach jedem Durchlauf frei. Also wird vor Neubeginn der Schleife der Destruktor aufgerufen. Dort wird auch eine Kontrollausgabe gemacht und danach der Speicherplatz für den int Wert wieder freigegeben.
Nun geht es in der Schleife weiter und die Methode printValue() wird aufgerufen, welche den Inhalt ausgibt, auf den iValue zeigt. Danach beginnt die Schleife von neuem. Da aber nach jedem Ablauf der Kontext geschlossen wird, gibt C++ das Objekt auch nach jedem Durchlauf frei. Also wird vor Neubeginn der Schleife der Destruktor aufgerufen. Dort wird auch eine Kontrollausgabe gemacht und danach der Speicherplatz für den int Wert wieder freigegeben.
Lassen wir das Programm mal laufen:
Die Ausgabe bestätigt diesen Ablauf. Der Konstruktor und vor allem Destruktor wird also in der Tat automatisch vom
System aufgerufen. Nun gibt es aber noch ein kleines Problem – was ist denn, wenn wir das Objekt nicht in einer
lokalen Variablen speichern, sondern im Heap und speichern lediglich den Zeiger hierauf? Ich ändere die Main Methode
wie folgt ab:
Listing 4: Anpassung auf Objekte im Heap
Kurze Erklärung der Codezeilen:
myObj ist nun ein Zeiger auf ein TestObject und existiert außerhalb der Schleife. Wir müssen nun in C++ das Objekt mit
„new“ erzeugen, schreiben die Adresse in
myObj und rufen
printValue() auf.
Wenn wir das Programm nun ausführen, sehen wir folgende Ausgabe:
Dies bedeutet also, dass das Objekt nicht aus dem Speicher genommen wird und somit auch der Destruktor nicht aufgerufen
wird, um die
int Speicherzelle freizugeben. Das heißt, wir haben wieder „Memory Leakage“. Dies lässt sich nun mit einem neuen
Operator verhindern, der explizit das Objekt entfernt – und somit auch den Destruktor wieder aktiviert. Ergänzen wir
also unsere Main Methode erneut und fügen
„delete myObj;“ hinzu:
Listing 5: Anpassung auf Objekte im Heap inklusive Speicherfreigabe
Führen wir nun das Programm wieder aus, wird der Destruktor wieder aufgerufen:
Wir sehen also, dass der Umgang mit Speicherresourcen in C++ durchaus komplizierter ist als in Java und C#. Auf der
anderen Seite bietet einem versierten Programmierer dieses Vorgehen eine sehr viel bessere Kontrolle über die
Ressourcen. Performanceprobleme aufgrund eines Garbage Collectors kennt der C++ Programmierer nicht. Weil es aber
eine durchaus große Herausforderung ist in C++ den Überblick über die Ressourcen zu behalten, kennen leider manche
Nutzer von fertigen C++ Programmen das Phänomen „Memory Leakage“ aus eigener Erfahrung, da manchen Programmierern
hier doch der ein oder andere Schwachpunkt seines Codes entgangen ist.
Rekursion
So viel zu unserem kleinen C++ Exkurs. Zum Abschluss des Themas „Speicherverwaltung“ kann ich jetzt endlich das
bereits angekündigte Thema „rekursive Funktionsaufrufe“ behandeln. Ein solcher Funktionsaufruf ist dann gegeben,
wenn sich eine Methode (bzw. Funktion) selbst aufruft. Die erste Frage, die man sich hier stellen muss ist:
geht das überhaupt? Kann eine Funktion sich überhaupt selbst aufrufen? Um das zu klären, probieren wir folgendes
Java Programm aus:
Listing 6: Erster Versuch von Rekursion
Wir sehen, dass die Funktion
methode() sich gleich in seiner zweiten Zeile im Rumpf selbst wieder aufruft. Der Compiler scheint den Code zu
akzeptieren. Was passiert nun, wenn wir diesen Code starten? Zuerst gibt uns das Programm sehr oft die Ausgabe
„in Methode“ aus, bis eine Fehlermeldung entsteht:
Unser Programm stürzt mit einem „Stack overflow error“ ab. Dies dürfte nun nicht mehr verwunderlich sein. Die Methode
wird aufgerufen und erhält im Stack Speicherplatz für die Variable
j. Danach erfolgt eine Ausgabe und die Methode wird wieder aufgerufen. Somit wird für den zweiten Aufruf nochmal Platz
für
j reserviert und so weiter. Irgendwann ist die Kapazität des Stack Speichers aufgebraucht und der Spe-cher
„läuft über“ – was entsprechend diese Fehlermeldung zur Folge hat. Bauen wir unsere Methode derart um, dass sie gar
keine Variable mehr aufweist und somit hierfür keinen Speicherplatz mehr benötigt:
Listing 7: Zweiter rekursiver Versuch
Interessanterweise würde auch dieser Code zu einem Stack overflow Error führen. Dies liegt daran, dass der Rechner
sich auch den aktuellen Zustand der Methoden irgendwo merken muss. Funktionen (bzw. Methoden) benötigen also auch
Speicherplatz, auch wenn sie keine lokalen Variablen besitzen. Heißt das jetzt, dass rekursive Aufrufe zwar möglich
sind, aber nicht funktionieren? Wohl kaum. Im Prinzip heißt das lediglich, dass wir, wenn wir rekursive Aufrufe
vorsehen, sehr gut aufpassen müssen, damit wir keinen Fehler machen. Versuchen wir mal folgende Methode mit
„methode(10);“ aufzurufen:
Listing 8: Rekursiver Rückwärtszähler
Kurze Erklärung der Codezeilen: Wir haben nun einen Parameter, der die Durchlaufanzahl angibt. Wir schreiben den Wert
auf die Konsole und prüfen danach, ob der Wert lauf gleich 0 ist. Wenn ja, beenden wir die Methode mit
return. Wenn nein, ruft sich die Methode wieder auf, allerdings wird der Aufrufparameter nun
„lauf – 1“ sein, sprich der nächste Aufruf startet mit einem geringeren Wert.
Wenn wir das Programm laufen lassen, sehen wir die Zahlen 10 bis 0. Das Programm wurde also beendet – es hat
„terminiert“. Wir haben also einen Rückwärtszähler realisiert(4). Die Frage ist, geht das nicht auch einfacher?
Die Antwort ist – ja es geht anders, eben mit einem Rückwärtszähler, wobei dies natürlich wiederum andere Codekonstrukte
bedingt:
(4) Wir werden bei den funktionalen Ansätzen solche Zählschleifen aus rekursiven Aufrufen nochmal näher be-leuchten
Listing 9: Klassischer Rückwärtszähler (iterativ)
Kurze Erklärung der Codezeilen: Die Zählschleifen werden wir in einem späteren Kapitel ansehen. So viel sei hier schon gesagt,
wir initialisieren die Zählvariable
i mit dem Wert
„lauf“ und ziehen so lange 1 von
i ab (also
i--), solange
i größer oder gleich 0 ist.
Die Ausgabe ist wieder 1:1 wie in der rekursiven Lösung. Und ehrlich gesagt – irgendwie sieht die klassische Lösung
auf den ersten Blick auch einfacher aus. Rekursive Lösungen können also oftmals durch Schleifen ersetzt werden und
anders herum. Sehen wir uns aber mal folgenden Code für die Fakultätsberechnung an
(Fakultät von bspw. 5 ist 5*4*3*2*1 = 120):
Listing 10: Fakultät über Schleife
Kurze Erklärung der Codezeilen: Wir übergeben den Wert, bspw. 5. Dann wird eine Ergebnisvariable
ergebnis erstellt, in die schon mal die 1 geschrieben wird. Nun erfolgt die Schleife, welche bei 2 anfängt, da die
1 ja schon in
ergebnis steht. Die Schleife läuft so lange durch, solange
i kleiner gleich dem
wert ist – also für den Fall 5 läuft die Schleife für
i = 2, 3, 4 und 5 durch. In jedem Durchlauf wird
i zum
ergebnis hinzumultipliziert. Schließlich wird das Ergebnis zurückgeliefert.
Die Ausgabe bei Aufruf
„facultyIterative(5)“ ist schließlich die 120. Versuchen wir den Code mal als Rekursion:
Listing 11: Fakultät rekursiv
Kurze Erklärung der Codezeilen: Wir prüfen, ob der Wert die 1 erreicht hat und wenn ja, wird die 1 zurückgegeben.
Beim ersten Aufruf ist dies nicht der Fall, da wir mit 5 aufgerufen haben. Danach ruft sich die Funktion wieder auf,
diesmal mit der 4 usw., bis die 1 erreicht ist. Wenn dies der Fall ist, wird die 1 zurückgegeben, mit dem vorletzten
Wert, der 2 multipliziert, das Ergebnis wird zurückgegeben, mit dem vorvorletzten Wert, der 3 multipliziert und so
weiter.
Das Ergebnis ist wieder die 120. Sehen wir uns das Ganze nochmal grafisch an, um die Konsequenzen eines solchen
Konstruktes zu sehen:
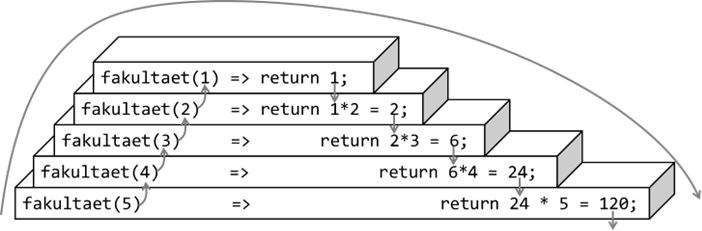
Abb.: 3: Einzelrechnungen bei rekursiver Fakultätsermittlung
Wir fangen also mit unserem Aufruf unten links an, gehen hoch bis 1 und dann wird der Stapel nach unten wieder
abgebaut. Dieser Stapel ist auch vergleichbar mit der Speicherbelegung im Stack, da die Aufrufe aufeinander aufbauen.
Bleibt die Frage, was besser ist. Grundsätzlich kann man sagen, dass rekursive Aufrufe nicht sehr effizient mit den
Ressourcen umgehen. Wenn wir beispielsweise den Code aus
Listing 8 mit dem Wert 100.000 aufrufen, wird ein Stack overflow Error auftreten, sofern wir Java nicht mehr Speicher
geben. Wenn wir also mit einem vertretbaren Aufwand eine iterative Lösung finden, sollten wir diese auch umsetzen.
Wir werden bei den Sortieralgorithmen aber ein Verfahren(5)
kennenlernen, welches sich sehr leicht rekursiv umsetzen lässt, iterativ jedoch sehr komplex wird. Weiterhin würden
die Puristen von funktionalen Programmieransätzen die Rekursion einer Schleife vorziehen, da wir bei Rekursionen ohne
Seiteneffekte auskommen – was wir später im Kapitel für funktionale Ansätze nochmal genauer ansehen werden. Ein
letzter Hinweis noch zu rekursiven Verfahren. Wenn wir es schaffen, den rekursiven Aufruf als letzten Befehl in der
Funktion zu realisieren, sprechen wir von einer „Endrekursion(6)“. Dies bedeutet, dass der Computer die internen
Ressourcen der aufrufenden Funktion bereits beim rekursiven Aufruf frei geben kann – sie werden ja nicht mehr benötigt.
Dadurch kann der Ressourcenbedarf erheblich reduziert werden. Diese Optimierung wird aber nicht von allen Compilern
unterstützt, bzw. findet man diese Optimierung hauptsächlich bei Compilern für funktionale Programmiersprachen wie bspw.
Haskell.
(5) Das „Quicksort“ Verfahren
(6) Englisch „tail recursion“
(6) Englisch „tail recursion“

CC Lizenz (BY NC SA)