
Filezugriffe – wer schreibt, der bleibt
Bevor wir uns mit den eigentlichen Filezugriffen beschäftigen, müssen wir uns vorab nochmal an die Grundprinzipien eines Computers erinnern. Ein Computer kann nur binäre Zahlen verarbeiten!
Es gibt auf der untersten Ebene nichts anderes als Einsen und Nullen. Aus diesem Grund liegt unter jedem Filezugriff erstmal nur die Anforderung, diese Einsen und Nullen von der Festplatte
in den Speicher zu befördern. Da diese in Bytes organisiert sind, spricht man hier oft von einem Bytestream, wobei dies aus Sicht eines Filezugriffs zu allgemein ist. Ein Filezugriff erfolgt
über einen sogenannten Filestream, was eine spezielle Form eines Bytestreams ist. Wenn dies so ist wirft sich die Frage auf, welche anderen Bytestreams es denn gibt? Nun – neben Datenströmen
vom Filesystem gibt es noch welche direkt von Speicher, von Netzwerken oder Datenbanken. Insofern ist in objektorientierten Sprachen eine Filestream Klasse eine Erweiterung der Bytestream
Klasse. Diese Idee vereinfacht es oft, die Verarbeitung zu vereinheitlichen. Frei nach dem Motto – „wo der Bytestream herkommt ist mir egal, ich verarbeite alle Bytes“. Dies geht zwar nur zu
einem gewissen Grad – wenn wir aber in einer verarbeitenden Klasse uns möglichst auf die Methoden der Bytestream Klasse reduzieren, können wir die Quelle des Bytestroms relativ einfach
austauschen. In C als nicht objektorientierte Sprache funktioniert das so zwar nicht, aber die Grundidee bleibt erstmal die gleiche.

Files byteweise lesen
Was wir nun speziell bei Fileströmen nicht außer Acht lassen dürfen ist die Tatsache, dass jedes File erstmal in einem Filesystem eingebettet ist. Dieses verwaltet die Datei und ordnet ihr
Attribute wie bspw. Namen zu, welche wir aus Programmsicht wieder auslesen müssen. Neben diesen allgemeinen Informationen lesen wir oft in einem zweiten Schritt die eigentlichen Daten – in der
einfachsten Form als Bytestrom und interpretieren ihn anschließend. Hier unterscheidet man zwischen Binärdateien und Textdateien, wobei aus Sicht des Filesystems das erstmal egal ist – es
handelt sich immer erstmal „nur“ um Binärdaten, die einfach unterschiedlich interpretiert werden:
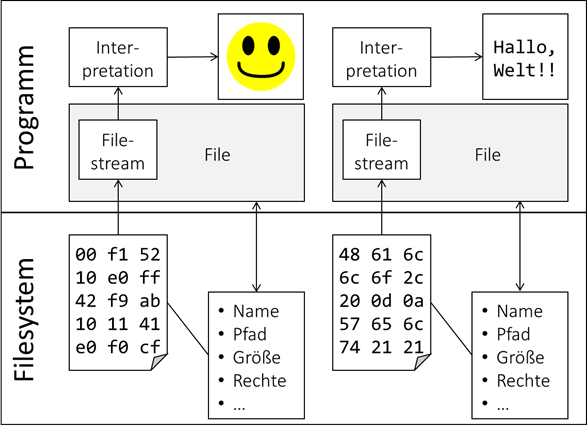
Abb.: 1: Grundkonzept von Filezugriffen
Versuchen wir mal an die Bytes ranzukommen. Hierzu benötigen wir einen Reader. Beginnen wir diesmal mit C#. Wir schreiben eine Ausgabefunktionalität, welche den Filenamen (mit Pfadangabe)
benötigt. Da wir bei sehr großen Files im Regelfall nicht alle Bytes ausgeben wollen, limitieren wir die Ausgabe einfach mit einem weiteren Parameter:
Listing 1: Bytereader in C#
Kurze Erklärung der Codezeilen: Das Objekt welches den Lesevorgang unterstützt ist der
FileStream. Diesen erzeugen wir mit Hilfe der
File Klasse, indem wir ein File öffnen. Unter
FileMode finden wir noch andere Optionen, welche das File verändern oder auch neu erzeugen können. Die einzelnen Bytes lesen wir mit
ReadByte() aus, wobei diese Methode überraschenderweise einen
int Wert zurückgibt und kein
byte. Dies liegt daran, dass wenn das Ende des Files erreicht wurde, die Methode -1 zurückgibt. Der Rückgabewert muss also 256 mögliche Bytewerte plus die -1
abbilden können, wodurch der Datentyp
byte ausscheidet. Die Ausgabe des Bytes formatieren wir in ein Hexadezimalformat, da es für die Bytedarstellung so üblich ist. Der Öffne- und Lesevorgang kann diverse Exceptions hervorrufen, weshalb
ich hier der Einfachheit halber alle Exceptions über einen Kamm schere. Dies ist nicht besonders elegant – für unsere Zwecke aber erstmal ausreichend. Wichtig ist, dass wir in einem
finally Block den Filestrom schließen. Dies würde mit
Close(), oder wie hier gezeigt mit
Dispose() gehen, was im Wesentlichen das Gleiche ist.
Den Code können wir nun im Hauptprogramm mit folgendem Statement aufrufen:
Listing 2: Aufruf des C# Bytereaders
Kurze Erklärung der Codezeilen: Bei der Pfadangabe müssen wir für Windows Systeme den Backslash doppelt hinterlegen. Dies wird später nochmal bei der Escape Notwendigkeit erklärt. Ich
gehe hier einfach davon aus, dass unter dem
C:\temp Verzeichnis die Datei
MyBitmap.bmp befindet. Hier kann jede beliebige Datei (die aktuell nicht von einem anderen Programm geöffnet ist) eingetragen werden.
Bei der Ausführung sehen wir dann die ersten 100 Bytes unserer Datei. Hier kommen wir gleich zu einem neuen Syntaxelement dieser Sprache, nämlich
using. Wenn man sich den Code in
Listing 1 ansieht erkennt man, dass relativ wenige Codezeilen für die eigentlich für uns relevante Funktionalität geschrieben wurden. Das meiste wird für die
try/catch Blöcke und dem Schließen des Streams benötigt. Wenn wir keinen Wert auf eine Ausgabe der Exceptioninformationen legen (also auf den
catch Block verzichten können), dann bietet uns
using eine verkürzte Möglichkeit dieses Codes an, indem das Ressourcenmanagement automatisiert wird. Im Wesentlichen kümmert sich C# dann automatisch um das Schließen des Streams.
Listing 3: Nutung von using im C# Bytreader
Kurze Erklärung der Codezeilen:
using kümmert sich um das automatische Schließen des Filestroms. Wir haben zwar keine trenngenaue Ausgabe einer möglichen Fehlersituation, da kein
catch() mehr vorhanden ist – für die meisten Fälle dürfte dies aber ausreichend sein.
Wir können an dieser Stelle wieder die Parallelen zwischen C# und Java sehen, indem wir uns die Umsetzung einer Fileausgabe in Java betrachten:
Listing 4: Bytereader in Java
Kurze Erklärung der Codezeilen: Die Unterschiede zu C# sind minimal. Java hält die Funktionalität für das Öffnen eines Files nicht in statischen Methoden, sondern kapselt sie in
einem Objekt der Klasse
File. Der Konstruktor
FileInputStream() akzeptiert dieses File, wobei er auch direkt einen
String mit dem Filenamen
fName verarbeiten würde, wodurch das
File Objekt entfallen könnte. Ansonsten ist Java etwas stringenter beim Abfangen von Exceptions. So muss bspw. auch beim Schließen mit einer
IOException gerechnet werden
Auch Java bietet eine Kurzform ohne
catch() an, wobei die
IOException des Schreibbefehls über
throws an den Aufrufer weitergereicht und dort abgefangen werden muss, da diese streng genommen nichts mit dem Öffnen und Schließen des Streams zu tun hat:
Listing 5: Automatisches Ressourcenmanagement in Java
Buffer, anstatt klein, klein
Nun gibt es jedoch beim Filezugriff noch einen Punkt zu beachten. Wenn wir große Mengen an Daten verarbeiten ist es beim Lesen und vor allem auch beim Schreiben sinnvoll, die Anzahl der
Zugriffe auf das Filesystem zu reduzieren. Unser Code erfüllt bis jetzt diese Anforderung nicht, da wir für jedes einzelne Byte die
read() Methode aufrufen. Fast alle Programmiersprachen haben hierfür eigene Methoden, welche ein
(byte-) Array und die Anzahl der zu lesenden Bytes erwartet. In dieses Array werden dann die Bytes eingetragen. Meist kann man noch einen Offset angeben, wo der Lesevorgang begonnen werden
soll. Da man nicht immer zu 100% sicher sein kann, dass das File auch so viele Bytes aufweist wie man mit der Anzahl angegeben hat, liefern sie im Regelfall die Anzahl der tatsächlich
gelesenen Bytes als Rückgabe. Somit kann man Files in Blöcke aufteilen und diese Blöcke auf einmal einlesen. Diese Methoden gibt es oft synchron und asynchron. Synchron bedeutet, dass die
Abarbeitung des Codes solange wartet, bis die Daten eingelesen wurden. Da bei größeren Datenmengen dies durchaus Zeit in Anspruch nehmen kann, gibt es noch die asynchronen Lesemethoden,
welche einen parallelen Thread nutzen, so dass das Lesen lediglich angestoßen wird und das Programm dann weiterarbeiten kann. Eine Callback Methode meldet sich dann, sobald alles eingelesen
wurde. Bei dem Thema Multithreading werden wir auf das Konzept der parallelen Verarbeitung nochmal zu sprechen kommen. Für jetzt reicht erstmal der synchrone Zugriff.
Listing 6: Optimierter Bytereader in Java
Kurze Erklärung der Codezeilen: Da wir eine klar definierte Anzahl an Bytes lesen wollen, können wir das myBuffer Array mit einer festen Größe erzeugen. In
readBytes legen wir die tatsächlich gelesene Anzahl an Bytes ab. Dies ist dann sinnvoll, wenn das File weniger Bytes hat, als in
noOfBytes gefordert wird. Das Lesen beginnen wir mit dem Offset 0 – wir wollen das File von Anfang an lesen. Nach dem Lesevorgang geben wir die gelesenen Bytes aus.
In C# finden wir eine Vergleichbare Methode in
FileStream.Read(), bzw. wenn wir alle Bytes lesen wollen auch in
File.ReadAllBytes(). Der Vollständigkeit zeige ich hier mögliche Umsetzungen für die restlichen Sprachen auf, wobei ich auf C++ verzichte, da hier der C Code 1:1 auch läuft. Beginnen wir mit C:
Listing 7: Bytereader in C
Kurze Erklärung der Codezeilen: In C werden die Fileleseoperationen mit
fopen(),
fread() und
fclose() erledigt. Hierbei wird das File durch
fopen() geöffnet und ein Zeiger hierauf zurückgegeben.
fread() erwartet ein Array als
myBuffer, welches den Inhalt aufnimmt. Da C keinen Datentyp
byte kennt, verwenden wir
unsigned char, was gleichbedeutend ist. Die Funktion erwartet noch die Größe eines zu lesenden Elements (also ein Byte) und die Anzahl der maximal zu lesenden Bytes – und natürlich den
Zeiger auf das File. Als Rückgabewert erhalten wir dann wieder die Anzahl der tatsächlich gelesenen Bytes. Da wir den
myBuffer über
malloc() dimensioniert haben, müssen wir mit
free() den Speicherplatz wieder freigeben. Weiterhin dürfen wir auch hier das Schließen des Files nicht vergessen. Die Ausgabe wurde über
printf() realisiert und hierbei die C-interne Funktionalität der Hex-Ausgabe über
%02x (also zweistellige Hexadezimaldarstellung) formatiert. Das Errorhandling habe ich mir hier gespart. Wer Fehler prüfen möchte, kann die Funktion
ferror() nutzen.
Die Skriptsprachen bringen an dieser Stelle außer ein paar Syntaxvarianten kaum neuen Erkenntnisse. Die JavaScript Umsetzung ist mit der C Lösung vergleichbar:
Listing 8: Bytereader in JavaScript
Kurze Erklärung der Codezeilen: Die Funktionalitäten für das Filesystem befinden sich in der
fs Bibliothek. Dort liegen auch die Funktionen zum Lesen, Umbenennen, Löschen etc. Die Vorgehensweise für das Lesen ist erstmal nichts neues. Da JavaScript jedoch dynamisch typisiert ist,
können wir kein Bytearray (bzw. wie in C ein
unsigned char Array) verwenden, sondern müssen ein speziell für diese Daten vorbereitetes Objekt verwenden – den
Buffer. Dieser wird mit der benötigten Größe allokiert (sprich „erzeugt“). Danach wird das File geöffnet. In JavaScript kann man hierfür die
open() Methode aus der
fs Bibiothek verwenden. Diese Methode benötigt wieder den Filenamen und die Information, dass gelesen wird
(„r“ steht hier für read). Der dritte Parameter ist eine sogenannte „Callback Funktion“ für die Verarbeitung, sprich dem Lesen des Files. Ähnlich wie bei den Lambda Ausdrücken in Java tragen
wir hier die Funktion ein, welche nach der Ausführung von
open() aufgerufen wird. Sollte der Parameter
err leer sein, so wurde die Datei geöffnet, ansonsten wird die Fehlermeldung ausgegeben. Im Erfolgsfall lesen wir wieder die notwendige Anzahl an Bytes in den
myBuffer und merken uns, wie viele Bytes tatsächlich gelesen wurden. Diese geben wir anschließend als Hexwert (also Basis 16) aus
In Python finden wir eine an unsere Aufgabenstellung sehr gut angepasste Methode:
Listing 9: Bytereader in Python
Kurze Erklärung der Codezeilen:
„rb“ steht wie in C für „read binary“. Der
read() Befehl erwartet lediglich die Anzahl der Bytes und liefert ein „iterierbares“ Objekt – also eine Datenmenge, welche mit einer Zählschleife ausgelesen werden kann. Dieses Objekt kann entweder als Parameter
eines Konstruktors für eine
list verwendet werden – also einem arrayähnlichem Konstrukt, oder wie im oberen Code einfach einer
foreach Schleife übergeben werden, in der wir jedes Element in die Variable
myByte schreiben. Mit
print(hex(myByte)) geben wir die Bytes als Hexadezimalwerte aus. Wie bei den anderen Sprachen auch, muss ich das geöffnete File am Ende schließen. Das Errorhandling sollte an dieser Stelle selbsterklärend sein.
Fehlt nun noch die PHP Lösung, welche hier etwas umständlicher wirkt. Dies liegt daran, dass PHP für die Webkommunikation erstellt wurde und das Verarbeiten von Binärfiles hier die absolute Ausnahme darstellt:
Listing 10: Bytereader in PHP
Kurze Erklärung der Codezeilen: Da die PHP Lesefunktion
fread() nicht die Anzahl der gelesenen Bytes sondern den Fileinhalt als
String zurückgibt, müssen wir die einzelnen Bytes aus dem String mittels
ord() extrahieren. Wir werden weiter unten nochmal den Unterschied zwischen Text und Bytes klären. Soviel sei hier gesagt – wir greifen uns mit Hilfe der Zählschleife die einzelnen gelesenen Zeichen ab und wandeln sie mit
ord() in eine Bytezahl um, die wir wiederum mit
dechex() in einen Hexwert konvertieren. Die Option
„rb“ der
fopen() Funktion steuert hier nicht die Interpretation der Daten als Byte, sondern im Wesentlichen den Umgang mit dem Zeilentrenner, über den wir auch weiter unten nochmal sprechen werden.
Wir halten also nochmal fest:
- Beim Lesen von Files versuchen wir die Anzahl der einzelnen Filezugriffe möglichst zu reduzieren.
- Wenn wir mit Files arbeiten, sind immer Fehlersituationen möglich, die abgefangen werden sollten.
- Die unterste Ebene des Files sind Bytedaten, welche wir mit fertigen Funktionen bzw. Methoden auslesen können – meist in ein Array.
- Diese Bytes sind erstmal nichts weiter als Daten, welche noch zu interpretieren sind.
Files byteweise schreiben
Beim Schreiben sieht dies nun genauso aus. Wenn wir also ein File schreiben wollen welches von anderen Programmen zu interpretieren ist, müssen wir also erstmal wissen, welche Codierung hinter dem zu
schreibenden File liegt. Das macht die Sache erstmal schwierig… Die Codierung hinter einem
mp3 oder einem
jpg File ist vermutlich für 99% aller Programmierer erstmal undurchdringbar! Für die meisten
Dateitypen gibt es aber erfreulicherweise bereits fertige Bibliotheken, welche die Codierung für uns erledigen. Man findet diese Bibliotheken normalerweise recht schnell mit ein paar Suchanfragen im Netz.
Trotzdem möchte ich an dieser Stelle nun ein Programm für die Erzeugung von einfarbigen Bitmaps von Grund auf selbst herleiten, damit wir einen ungefähren Eindruck von den Notwendigkeiten der Binärdateien
erhalten. Fast alle Programmiersprachen bieten komfortable Bibliotheken für die Bilderzeugung an und beschränken sich vor allem nicht auf Bitmaps, sondern auf höherwertige Formate wie bspw.
png oder
jpg.
Bitmaps sind aber die denkbar einfachsten Konstrukte in der Welt der Binärdateien und somit für unsere Zwecke genau das Richtige. Am Anfang steht nun erstmal die Analyse, wie eine Bitmapdatei aufgebaut ist.
Für diese Info kann ich den Wikipediaartikel(1) dazu empfehlen. Hier die wichtigsten Informationen in aller Kürze.
(1) https://de.wikipedia.org/wiki/Windows_Bitmap
Eine Bitmapdatei ist eine Rastergrafik, welche jedes Pixel mit dem Farbcode RGB (also Rot, Grün und Blau) zu je acht Bit darstellt. Aus diesem Grunde sprechen wir von einer Farbtiefe von 24 Bit.
Die Datei besitzt einen Header für strukturelle Informationen und den Body, welcher die RGB Werte beinhaltet. Der Header wiederum ist in einzelne Bereiche aufgeteilt und führt die Informationen im Little Endian Format.
| Offset: | Inhalt: | Bedeutung: | Beispielwert (Hex): |
|---|---|---|---|
| 0 | Kennung „BM“ | ASCII Werte für die Zeichen B und M | 42 4d |
| 2 | Dateigröße | Anzahl der Bytes der Datei | B6 00 00 00 |
| 4 | Reserviert | Reservierter Bereich, immer 0 | 00 00 00 00 |
| 10 | Offset Bilddaten | Position, wo die Bilddaten beginnen (meist 5410) | 36 00 00 00 |
| 14 | Größe Infoheader | Größe dynamischer Header (meist 4010) | 28 00 00 00 |
| 18 | Bildbreite | Anzahl horizontaler Pixel | 0A 00 00 00 |
| 22 | Bildhöhe | Anzahl vertikaler Pixel | 04 00 00 00 |
| 26 | Reserviert | Immer 1 | 01 00 |
| 28 | Farbtiefe | Farbtiefe der Pixel (meist 2410) | 18 00 |
| 30 | Komprimierung | Info über Kompression (bei uns 0) | 00 00 00 00 |
| 34 | Bildgröße | Anzahl Bytes für Bilddaten | 80 00 00 00 |
| 38 | Horz. Auflösung | Horizontale Auflösung (meist 0) | 00 00 00 00 |
| 42 | Vert. Auflösung | Vertikale Auflösung (meist 0) | 00 00 00 00 |
| 46 | Farbtabelle | Anzahl Farbtabelleneinträge (bei uns 0) | 00 00 00 00 |
| 50 | Farbanzahl | Bei Farbtabellennutzung Anzahl der Farben (hier 0) | 00 00 00 00 |
| 54... | Bilddaten | RGB (bzw. GBR) Werte. Die Anzahl der Bytes pro Bildzeile muss ein Vielfaches von 4 sein. Rest wird mit 0 aufgefüllt. | FF BA FF FF BA FF FF BA FF 00 00 00 … |
Tabelle 1: Aufbau Bitmap Datei
Da ich den Code für alle unsere Programmiersprachen – und somit auch C – zur Verfügung stelle, werde ich auf objektorientierte Ansätze möglichst verzichten. Dies betrifft vor allem das Errorhandling,
welches ich ohne Exceptions umsetzen werde. Die C++ Implementierung werde ich mir ebenfalls sparen, da die C Lösung hier wieder 1:1 zu übernehmen ist. Herleiten werde ich die Umsetzung an dieser Stelle
mit C#. Beginnen wir mit dem eigentlichen Inhalt unseres Bitmaps – den Bitmap Pixeldaten. Wir wollen ein einfarbiges Bitmap mit einer festen Größe erstellen. Die Daten sollen in einem Bytearray vorliegen,
wie sie ab Offset 54 benötigt werden. Dieses Array soll vorerst zweidimensional vorliegen. Das erleichtert die Möglichkeit einzelne Pixel später exakt anzusprechen. Die Parameter der Methode zum Schreiben
eines einfarbigen Bitmaps sind somit die Höhe, die Breite und die Farbe. Letztere soll als eine Ganzzahl vorliegen, wobei Rot die Bits 16 bis 23, Grün die Bits 8 bis 15 und Blau die Bits 0 bis 7 belegen.
Diese werden mittels Bitshift und einer Bitmaske 0xff in einzelne Bytevariablen extrahiert:
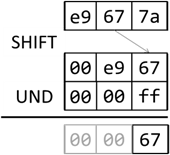
Abb.: 2: Extraktion des Grünwertes in einzelnes Byte
Ein weiterer Punkt ist die Ermittlung der notwendigen Anzahl für die 0 Werte für das Auffüllen der Zeilen auf eine Byteanzahl als Vielfaches von 4. Hierzu ermitteln wir erstmal, wie weit die Zeilenanzahl
von einem Vielfachen von 4 „entfernt“ ist. Wenn wir bspw. 5 Pixel in einer Zeile haben, benötigen wir 5 * 3 = 15 Bytes für eine Bildzeile. Mit Hilfe des Modulooperators 15 Modulo 4 = 3 finden wir heraus,
dass wir 3 Werte über der 12 liegen. Da wir aber auffüllen wollen, müssen wir 4 – 3 = 1 rechnen. Das ist die fehlende Anzahl bis 16. Nun müssen wir den Sonderfall berücksichtigen, dass wir bereits ein Vielfaches
von 4 ohne Auffüllen haben (bspw. 16 Pixel = 16 * 3 = 48 Modulo 4 = 0). Wir verhindern, dass hier vier 0-Werte aufgefüllt werden (da 4 – 0 ja 4 ergibt), was der Abstand zum nächsten Vielfachen von 4, also 20 wäre.
Lösen können wir das, indem wir das Ergebnis aus 48 Modulo 4 nochmal Modulo 4 rechnen, wodurch die Werte 1, 2 und 3 1:1 übernommen werden, die 4 aber zu 0 wird. Wem das zu kompliziert erscheint, sollte einfach
mal die Rechnung mit 4, 5, 6, 7 und 8 Pixel händisch durchrechnen – dann müsste es klarer werden.
Listing 11: Erzeugen eines einfarbigen Bodies einer Bitmap Datei
Kurze Erklärung der Codezeilen: Zuerst werden die RGB Werte aus der
color Variable extrahiert. Die
noOfZero Berechnung entspricht dem oben beschriebenen Algorithmus. Die Größe des
body Arrays berechnet sich auf Basis der Breite * 3 (wegen 3 Bytes pro Pixel) plus die errechneten Füllwerte mit 0 und der Höhe. Die beiden Schleifen gehen die Zeilen
(r für Rows) bzw. Spalten
(c für Columns) durch und setzen jeweils die RGB Werte. Nach jeder Zeile werden mit einer eigenen Schleife die
0x00 Werte gefüllt. Dies ist streng genommen nicht notwendig, da die Initialisierung mit 0 in C# automatisch erfolgt. Damit der Code aber einfacher in die anderen
Programmiersprachen portierbar ist, belasse ich diesen Teil.
Nun haben wir die eigentlichen Daten festgelegt. Als nächstes benötigen wir den Header des Bitmaps. Da wir die Daten im Little Endian Format ablegen müssen, bauen wir uns eine Hilfsmethode, welche dies für uns erledigt:
Listing 12: Übertrag im little Endian Format
Kurze Erklärung der Codezeilen: Wir benötigen als Parameter den eigentlichen Wert, welcher übernommen werden muss als Variable
value. Weiterhin übergeben wir das Zielarray
allBytes, in das wir die Information ablegen müssen und schließlich noch den
offset, wo dies geschehen soll. Nun schneiden wir die rechten 8 Bits heraus und übergeben sie in das Array. Danach schieben wir um 8 Bits nach rechts, um die nächsten Bits zu übergeben. Das erfolgt,
solange wir noch Werte ungleich 0 in der
value Variable haben. Das Errorhandling beschränkt sich darauf, dass wir prüfen, ob wir nicht außerhalb des Arraybereiches schreiben. Wenn dies der Fall ist geben wir
false zurück, ansonsten
true.
Nun können wir die eigentlichen Daten schreiben. Dazu müssen wir den Header zusammensetzen und die Daten anhängen:
Listing 13: Zusammensetzen der Bitmap Daten
Kurze Erklärung der Codezeilen: Die Headerinformationen werden als Template in ein
head Array vorab belegt. Sämtliche vorab festlegbaren Informationen werden hier eingetragen. Danach wird geprüft, ob die Daten des zweidimensionalen Arrays überhaupt verarbeitbar sind –
was im Wesentlichen dann ein Problem ist, wenn eine der beiden Dimensionen 0 ist. Nun können wir die Byteanzahl ermitteln. Da C# uns die Daten in einem Array in Matrixform ermöglicht,
müssen wir hier nur die Länge ermitteln. Bei Java muss hier eine Berechnung erfolgen. Nun ermitteln wir die Filegröße als Summe des Headers und Bodys. Alle dynamisch zu setzenden Größen
platzieren wir nun mit Hilfe unserer
setBytesLittleEnd() Methode in das Headerarray. Sollte hier ein Fehler passieren (also die Methode ein
false zurückliefern), geben wir einfach
null zurück, was somit die Indikation eines Fehlers für den Aufrufer von
prepareBmp() ist. Da C# hier ein Warning generiert um den Programmierer darauf hinzuweisen, dass diese
null-Rückgabe ein Problem erzeugen könnte, schreiben wir ein
! („null forgiving operator“ oder „null-toleranter Operator) hinter der
null, um dem Compiler mitzuteilen, dass wir dies im Blick haben.
Nun erzeugen wir das eigentliche Datenarray und belegen es sequenziell zuerst mit den Header und anschließend den Bodydaten.
Jetzt erfolgt das eigentliche Schreiben der Daten. Dies ist in C# sehr einfach mit einer einzigen Methode machbar. Insofern setzen wir alles gleich in einer Aufrufstruktur zusammen:
Listing 14: Aufrufstruktur zur Erzeugung eines Bitmaps
Kurze Erklärung der Codezeilen: Die Höhe und Breite benötigen wir sowohl für
genBmpData() als auch für
prepareBmp(), weshalb wir die Werte in Variablen halten um die Konsistenz zu garantieren. Wenn
data korrekt erzeugt wurde – sprich
data nicht
null ist, können wir die Bytes mit Hilfe der Methode
File.WriteAllBytes() schreiben und eine entsprechende Erfolgsmeldung ausgeben.
Wenn wir nun die Datei
NewBitmapCsharp.bmp mit einem Grafikprogramm öffnen, sehen wir ein Rechteck in der Farbe „dark salmon“. In Java würde der Code im Wesentlichen identisch aussehen – mit zwei Ausnahmen.
Zum einen würden wir in Java nicht auf das Array in Matrixform zugreifen können, sondern mit einem Array von Arrays arbeiten. Hierdurch sieht das Body Array wie folgt aus:
Listing 15: Body Array in Java
Dadurch ändert sich auch der Umgang mit dem Array:
Listing 16: Ermittlung der Gültigkeit des body Arrays und Bytebestimmung
Kurze Erklärung der Codezeilen: Hier ist es natürlich wichtig, zuerst die 0. Dimension mit
.length zu prüfen. Erst wenn wir mindestens eine Zeile haben, können wir die Spalten der 0. Zeile – also die 1. Dimension – prüfen.
Java bietet uns – wie C# auch – diverse Möglichkeiten, Daten auf das Filesystem zu schreiben. Ich möchte hier nun Java nutzen, um eine Methode wie
WriteAllBytes() selbst umzusetzen. Der Vorteil dieser Methodik wäre, dass wir das Errorhandling selbst kontrollieren können. Ob dies den Aufwand rechtfertigt muss mal wieder jeder für sich selbst
entscheiden. Wir nutzen hier die die rudimentärste Art mit Files umzugehen, da wir hier am flexibelsten sind und vor allem den Bezug zu den eigentlichen Strukturen auf dem Rechner am besten sehen.
Sehen wir uns erst den Code an, um dann nochmal Schritt für Schritt durchzugehen:
Listing 17: Java Methode zum Schreiben von Bytedaten in ein File
Kurze Erklärung der Codezeilen: Die Java Implementierung ist funktional bis auf das Errorhandling identisch mit der C# Methode
File.WriteAllBytes(). Zuerst erzeugen wir das File, welches die Kommunikation mit dem Filesystem aufbaut. Hier können wir auch prüfen, ob das File eventuell bereits existiert.
Wenn ja, dann informieren wir den User lediglich, dass wir es jetzt überschreiben. An dieser Stelle könnten wir nun problemlos eine Abfrage hinterlegen, damit der User selbst
darüber entscheiden kann – der Einfachheit halber habe ich dies weggelassen. Nun erzeugen wir den
FileOutputStream, der dafür verantwortlich ist die Bytedaten auf das Filesystem zu schreiben. Die Information wo dies geschehen soll, erhält der Stream vom Fileobjekt. Der boolean Parameter
false zeigt an, dass wir das File überschreiben. Würde er auf
true stehen, so würde der neue Inhalt am Ende des Files angehängt werden, was in unserem Fall natürlich nicht sinnvoll ist. Nun können wir das Bytearray in einem Durchgang schreiben. Das
flush() Kommando soll den Schreibpuffer des
FileOutputStream leeren, indem das Schreiben erzwungen wird. Dies ist an dieser Stelle eigentlich nicht notwendig, da beim Schließen dies ohnehin geschieht – ich habe ihn jedoch eingebaut,
dass man sieht, wie man dies zwischen zwei Bytearrays erledigen könnte. Der
FileOutputStream würde übrigens auch die Daten Byte für Byte schreiben können (also wirklich
fos.write(oneByte); – wobei dies, wie bereits beim Lesen von Files erwähnt, aus Performancegesichtspunkten zu vermeiden ist. Jede einzelne Kommunikation mit dem Filesystem kostet ja
Ressourcen. Java zwingt mich, die
IOException abzufangen, welche bei Fehlern während des Schreibvorganges auftreten könnten. Stellen wir uns vor, wir würden auf einen USB- Stick schreiben und diesen während des
Schreibvorganges abziehen, dann würde diese Exception auftreten. Im
finally() Block schließen wir den Strom wieder – allerdings nur, wenn er auch tatsächlich existiert. Wenn bspw. der Pfad nicht existieren würde, dann wäre
fos auf
null, was wir natürlich vorher abprüfen müssen.
Die hier gezeigte Methodik würde in C# ähnlich umsetzbar sein. Wie wir sehen, ist die Umsetzung im
Listing 17durchaus umständlicher als die Lösung mit
File.WriteAllBytes(). Wir können hier aber eher erkennen, wie die Mechanik hinter den Kulissen aussieht. Wer in Java übrigens eine ähnliche Lösung wie
File.WriteAllBytes() sucht, wird bei
Files.write(String fileName, byte[] data); in der
java.nio.file.*; Bibliothek fündig.
Wenn wir das Ganze in C umsetzen wollen, so müssen wir entweder ein Struct definieren, welche alle Daten beinhaltet, oder die Größenberechnungen zentral über allgemeine Variablen verwalten.
Der Grund liegt darin, dass wir die Arraygrößen nicht direkt von den Arrays abfragen können. Ich habe mich hier für die einfachere Variante der zentralen Variablen entschieden. Da die eigentlichen
Funktionalitäten sich nicht grundlegend unterscheiden, zeige ich an dieser Stelle nur das Hauptprogramm mit dem eigentlichen Filehandling (der Rest kann dann unter
https://github.com/maikaicher/book1 gefunden werden):
Listing 18: Erzeugung von Bitmaps in C
Kurze Erklärung der Codezeilen: C kennt weder
byte, noch zweidimensionale Arrays. Insofern verwenden wir wieder
unsigned char (was genau einem Byte entspricht) und das Ganze als eindimensionales Array bzw. Pointer, so wie wir es in
Kapitel 7 erläutert haben. Der Zugriff auf das
body Array erfolgt somit über
body[r * rowWidth + c]. Die Größenangaben werden nun außerhalb ermittelt und über die Parameterliste übergeben. C organisiert den Filezugriff über einen
FILE Pointer, den wir mit
fopen() öffnen. Hier geben wir
„w“ für Write und
„b“ für Binary an – dies ist insbesondere bei Windows wichtig, da der Schreibprozess sonst als „Text“ interpretiert wird und nach jedem Byte
„0xa“ ein „0xd“ gehängt wird – C versucht also ein Linefeed nach jedem Carriage Return zu ergänzen (Details zu CR und LF folgen weiter unten). Nun können wir mit Hilfe der
fwrite() Funktion die Daten schreiben.
fwrite() erwartet den Pointer auf das Array, die Größe des zu schreibenden Elementes (in unserem Fall die Größe des Gesamtinhaltes) und die Anzahl der Elemente (bei uns ist dies nur eines).
Am Schluss müssen die beiden Arrays, welche in
genBmpData() und
prepareBmp() allokiert wurden, wieder freigegeben und das File geschlossen werden.
Sehen wir uns nun die Skriptsprachen an. Wie so oft bei dynamisch typisierten Programmiersprachen, müssen wir bei solchen „Spezialfällen“ wie das Schreiben von Bytes einige Vorkehrungen treffen.
Die einzelnen Sprachen gehen hier zwar unterschiedliche Wege – allen gemein ist, dass durch die fehlende Typisierung bei der Deklaration jeweils ein Weg gefunden werden muss, die Daten als Binärdaten
zu interpretieren. Beginnen wir mit JavaScript. Die einzelnen Methoden können zwar weitestgehend aus Java übernommen werden – natürlich mit Ausnahme der Variablendeklaration und somit der Festlegung der
Datentypen und der Typecasts. Wichtig ist nun, dass wir in JavaScript die zu schreibenden Daten nun nicht mehr in ein Bytearray schreiben können, sondern ein Buffer Objekt benötigen, welches für solche
Schreibzugriffe notwendig ist und die Daten tatsächlich als Bytes interpretiert. Die Erzeugung des
data Arrays sieht somit in JavaScript wie folgt aus:
Listing 19: Erzeugung eines Byte-Buffers für das Schreiben von Bytes in JavaScript
Das Hauptprogramm mit dem Schreibzugriff ergibt sich zu:
Listing 20: Schreibzugriff in JavaScript
Kurze Erklärung der Codezeilen: Wir verwenden hier die kombinierte Methode zum Öffnen und Schreiben von Files inklusive eines Errorhandlers. Neben dem Filenamen benötigt die
Funktion natürlich auch die Daten – hier wieder als
Buffer. Als weiteren Parameter wird die Codierung benötigt – welche wir mit
binary angeben. Wir schreiben also 1:1 die Binärdaten. Der dritte Parameter ist das bereits bekannte Konstrukt der „Callback Funktion“ für die Verarbeitung des „Ergebnisses“. Nach der Ausführung von
writeFile() wird diese aufgerufen und ist hier lediglich für das Errorhandling zuständig. Sollte der Parameter
err leer sein, so wurde die Datei geschrieben, ansonsten wir die Fehlermeldung ausgegeben.
Als nächstes gehen wir kurz auf die Python Lösung ein. Da Python sich aus Sicht des Arrayhandlings etwas von den anderen Programmiersprachen unterscheidet, zeige ich hier kurz die Implementierung der Funktion
genBmpData():
Listing 21: Vorbereitung der Pixeldaten in Python
Kurze Erklärung der Codezeilen: Wie immer ist der Python Code aufgrund des Verzichts auf viele Strukturzeichen recht kompakt. Das
body Array wird als zweidimensionales Array mit fester Zeilenanzahl, jedoch ohne Spalten erzeugt. Man könnte hier zwar auch die Spalten gleich mit erzeugen lassen
(body = [[for c in range(3 * width + noOfZero)] for r in range(height)]), ich wollte aber eine einfachere Möglichkeit mit
append() aufzeigen, welche vor allem bei der Übernahme von
head und
body in das data Array der Funktion
prepareBmp() (entsprechend der Java Implementierung aus
Listing 13) einfacher sein wird. Die Idee bei der Nutzung von
append ist, dass wenn man ein Array ohnehin Stück für Stück aufbaut, kann man die neuen Elemente einfach hinten anhängen. Durch die dynamische Erweiterbarkeit von Arrays in den Skriptsprachen ist dies mitunter sinnvoll.
Das Hauptprogramm ist nur noch bezüglich des Filehandlings interessant:
Listing 22: Schreibzugriff in Python
Kurze Erklärung der Codezeilen: Die Python Lösung für die Filezugriffe zeigt wieder bekannte Konzepte. Das Zahlenarray muss mit
bytes() in ein
bytes Objekt umgewandelt werden, welches immutable ist und nur noch Bytewerte beinhaltet. In JavaScript war dies der
Buffer. Danach wird das File zum Schreiben
(„w“) von Binärdaten
(„b“) geöffnet, die Bytes geschrieben und dann wieder geschlossen.
PHP erlaubt uns natürlich ebenfalls Daten in ein Binärfile zu schreiben, wobei ich auch hier auf die Detaillierung von
genBmpData() und
prepareBmp() verzichte:
Listing 23: Schreiben von Binärdaten in PHP
Kurze Erklärung der Codezeilen: Der obere Bereich ist wieder vergleichbar mit den vorausgegangenen Lösungen – insofern spare ich mir auch hier die Darstellung der Unterprogramme.
Das Schreiben erfolgt in PHP mittels
fwrite(), wobei hier ein in Byte konvertierter String benötigt wird – anders als in Python oder JavaScript, wo dies durch ein eigenes Bufferobjekt erfolgte. Die Umwandlung in die
Bytedarstellung erledigen wir mittels
pack(). Dadurch werden die Zahlen in eine Bytedarstellung umgewandelt und mit dem Punktoperator in die Variable
$binData zusammengefügt. Dort befindet sich also der gesamte Inhalt der Datei in Binärformat als eine lange Zahlenkette – nur eben als Stringinformation. Nun öffnen wir ein File mittels
fopen() und schreiben mit diese lange Zahlenkette auf das Filesystem. Am Ende wird das File nun geschlossen. Die Herangehensweise ist also vergleichbar mit Python. Wie in Java und C# gibt
es hier übrigens auch eine Möglichkeit, das Öffnen, Schreiben und Schließen in einer zusammengefassten Funktion in einem Schritt zu erledigen:
file_put_contents("C:\\temp\\MyBitmap.bmp", $binData);
Ein weiterer wichtiger Punkt gerade bei PHP ist die Begrenzung der Speichernutzung des Interpreters. Da PHP im Regelfall für Serveranwendungen genutzt wird, beschränkt man den Speicher, der pro
Skriptaufruf freigegeben wird. Da wir hier bei der Verarbeitung die Daten mehrfach im Speicher halten, sollten wir ggf. in der Datei
php.ini das Limit etwas hochdrehen:
memory_limit=512M. Lassen wir unser Programm laufen, erhalten wir wieder eine Bitmap, welche wir mit einem Grafikprogramm öffnen können.
Textfiles – Bytes mal anders gesehen
Im weitesten Sinne haben wir in PHP im
Listing 23 das selbst realisiert, was in JavaScript mit dem
Buffer umgesetzt wurde. Dies ermöglicht uns somit nachzuvollziehen, warum diese Umwandlung überhaupt notwendig ist, da wir nun in den Mechanismus eingreifen können. Hierzu nehmen wir die
pack() Funktion heraus, um anschließend das Ergebnis analysieren zu können:
Listing 24: Anpassung des PHP Programms
Bevor wir das Programm starten, passen wir die Länge und Breite des Bitmaps auf jeweils 3 an, damit das File nicht zu groß für unsere weitere Analyse ist. Versuchen wir nun die Datei
MyBitmap.bmp mit einem Grafikprogramm zu öffnen, wird uns dies nicht gelingen. Die Codierung ist nicht mehr korrekt. Probieren wir es hingegen mit einem Texteditor wie Notepad, so sehen wir eine lange Ziffernkolonne:
Einige Zahlen dürften uns bekannt vorkommen. Die 66 ist in Hexadezimal die 4216. Die 77 ist 4D16, also genau die Zahlen, welche wir in unseren Header eingetragen haben
(vgl. hier das Programm
prepareBmp() bzw.
Tabelle 1). Auf den ersten Blick scheint eigentlich alles richtig zu sein – aber leider nur auf den ersten Blick. Wenn wir das File
MyBitmap.bmp nun mit unseren Bytereader öffnen und die ersten 10 Bytes ausgeben, sehen wir eine Überraschung:
Diese Zahlen haben nun überhaupt nichts mit den ursprünglichen Zahlen zu tun. Erst ein Blick auf die ASCII Tabelle in
Kapitel 23 gibt uns hier Aufschluss. Dort sehen wir, dass der Code 0x36 für das Zeichen 6, 0x37 für das Zeichen 7, 0x39 für die 9 und die 0x30 für das Zeichen 0 steht – die ersten Bytes stehen also für die
Zeichen „667790“. Wir haben also mit der Anpassung aus
Listing 24 dafür gesorgt, dass die Daten als Text und nicht als Bytes abgelegt wurden. Dies bedeutet aber, dass ein Textfile ebenfalls ein normales Binärfile ist, welches jedoch eine feste Interpretation
der Bytes entsprechend des Zeichensatzes darstellt, was wir in
Abbildung 1 ja schon skizziert haben. Da wir in der Praxis sehr häufig mit Textfiles arbeiten müssen, nehmen uns die einzelnen Schreib/Lesefunktionen unserer Programmiersprachen diese Interpretation häufig
ab, bzw. mehr noch – das Verarbeiten von Textdaten wird eigentlich als der Standardfall angesehen, so wie wir es gerade bei PHP feststellen mussten.
Um dies nun näher zu untersuchen, schreiben wir mit einem beliebigen Texteditor (in Windows können wir hierfür
notepad.exe verwenden) folgenden Text und speichern ihn im File
Hello.txt ab:
0#
Wenn wir nun dieses File mit einem unserer Bytereader (bspw.
ByteReader.java) lesen und ausgeben, dann erhalten wir folgende Ausgabe (ich habe der Übersicht halber die Zeilenumbrüche durch | ersetzt):
Nun ist das für uns erstmal nicht interpretierbar. Wenn wir uns aber die Mühe machen, jeden Hexadezimalwert in der ASCII Tabelle zu suchen und durch das zugehörige Zeichen zu ersetzen, kommt wieder unser Text heraus:
Die einzigen Zeichen, mit denen wir erstmal nichts anfangen können, haben den Hexwert
d16 und
a16, die wir in der ASCII Tabelle als „Line Feed“ und „Carriage Return“ wiederfinden. Wer unter einem Unix System oder auf iOS diese Übung nachvollzieht wird vermutlich nur „Line Feed“ finden und kein „Carriage Return“.
Um diese „Zeichen“ nun zu verstehen, müssen wir nochmal in die Vergangenheit gehen und uns eine klassische, mechanische Schreibmaschine ansehen:

Abb.: 3: Mechanische Schreibmaschine
Die Funktionsweise war, dass das Blatt auf eine Walze in einem Wagen (engl. Carriage) festgemacht war. Mit jedem Tastendruck wurde der Buchstabe auf das Papier gedruckt und der Wagen ist einen Zeichenabstand nach links gefahren.
Ist man am Ende der Zeile angekommen, musste man zwei Dinge tun. Zuerst musste man die Walze nach oben drehen, so dass das Papier ebenfalls nach oben transportiert wurde – man ist also in die nächste Zeile gesprungen („Line Feed“).
Danach hat man den gesamten Wagen wieder nach rechts zurückgeschoben („Carriage Return“), so dass man wieder am Anfang der neuen Zeile angekommen ist. Mit der Einführung der elektronischen Datenübertragung mittels „Fernschreiber“
musste man nun die einzelnen Tasten fernsteuern – sprich für jede Aktion (also für jede Taste der Schreibmaschine) jeweils einen Zahlencode festlegen und somit auch für die Aktionen Line Feed und Carriage Return. In Windows hat man
diese beiden Befehle für einen Zeilenumbruch weiterhin verwendet. Die Unix Betriebssysteme verwenden jedoch nur den Line Feed Befehl für einen Zeilenumbruch, genauso wie die aktuellen iOS Rechner. Dies ist insofern wichtig zu wissen,
als dass bei einer Übertragung von Textfiles von Windows auf ein anderes Betriebssystem und umgekehrt die Zeilenumbrüche mitunter angepasst werden müssen. Es existieren Texteditoren, welche dies automatisch erledigen können, wie bspw.
Notepad++. FTP Clients, welche für den Filetransport genutzt werden, können im sogenannten „ASCII“ Modus diesen Konflikt auflösen. Da der Zeilenumbruch also bei verschiedenen Betriebssystemen unterschiedlich gehandhabt wird, sehen die
meisten Sprachen Konstrukte zum Schreiben von Files vor, welche zeilenweise schreiben. Man gibt also einen String an, welcher dann im Textfile zu einer Zeile geschrieben wird. Der Zeilenumbruch wird dann automatisch gesetzt. Danach
folgt die nächste Zeile. Mitunter können auch Arrays von Strings übergeben werden, welche dann zeilenweise abgelegt werden.
Der Zeilenumbruch führt uns nun zu einem weiteren Problem der elektronischen Verarbeitung von Text. Gehen wir davon aus, dass wir den zweiteiligen Text von oben in Java in einem String eintragen wollen. Hierbei könnten wir auf folgende Idee kommen:
Listing 25: Versuch einer zweizeiligen Stringkonstante in Java
Wenn wir diesen Code versuchen zu kompilieren, werden wir eine Fehlermeldung erhalten:
Java geht also davon aus, dass nach dem Ausrufungszeichen der String mit einem doppelten Hochkomma abgeschlossen werden muss. Können wir also in Java (und in fast allen anderen Programmiersprachen) keinen Zeilenumbruch in eine
Stringkonstante eintragen? Nun, hier muss es eine Lösung geben! Genau für solche Fälle gibt es Escapezeichen. Das wohl am meisten verbreitete Escapezeichen ist der Backlsash
\. Die Idee hinter einem Escapezeichen ist, dass das
darauf folgende Zeichen nicht 1:1 verwendet, sondern interpretiert wird. Der Zeilenumbruch ist in der Regel
\n. Unser Listing muss also wie folgt aussehen:
Listing 26: Zweizeilige Stringkonstante in Java
Java unterstützt die folgenden Escapezeichen:
| Zeichen: | Bedeutung: |
|---|---|
| \t | Tabulator |
| \b | Backspace |
| \n | Neue Zeile („Line Feed“) |
| \r | Wagenrücklauf („Carriage Return“) |
| \f | Formfeed – also Seitenvorschub |
| \' | Hochkomma |
| \" | Doppeltes Hochkomma |
| \\ | Backslash |
Tabelle 2: Escapezeichen in Java
For allem der letzte Punkt ist wichtig. Wenn wir in einem Text den Backslash abbilden wollen, müssen wir hierfür auch eine Escapesequenz definieren, da sonst der Backslash selbst zum Escape führt.
Der Pfad String
myPath = "C:\temp\newFile.txt"; würde bei der Ausgabe sonst wie folgt aussehen:
\t würde als Tabulator und
\n als Zeilenumbruch interpretiert werden. Korrekt müsste der Pfad also wie folgt hinterlegt werden:
String myPath = "C:\\temp\\newFile.txt";
Die einzelnen Sprachen haben meist einen unterschiedlichen Umfang an Escapezeichen – hierzu konsultiert man am besten die einschlägigen Manuals. Wichtig ist an dieser Stelle noch, dass wenn nach dem
Backslash ein nicht definiertes Zeichen folgt, es im Regelfall zu einem Fehler führt. Der String
"Hallo\welt"; würde in Java also zu einem Kompilerfehler führen, da
\w nicht definiert ist. Interessant ist vielleicht, dass man nicht alle Steuerzeichen des ASCII Bereiches (also die ersten 32 Zeichen) mit einer Escapesequenz versehen hat. Manche Sprachen – wie bspw.
C# – erlauben jedoch die Angabe von Zahlen, um über den Zeichencode das Zeichen anzugeben. In C# ist dies die Ziffernfolge nach
\x. So liefert bspw.
\x0a und
\n das gleiche Ergebnis. In Java müsste man dies über den Zahlenwert eines einzelnen Characters erledigen und diesen in den String einfügen. Weiterhin ist zu bemerken, dass es in manchen Sprachen die
Möglichkeit gibt, die Strings ohne die Escapezeichen auszuwerten – sprich man gibt sie „literal“ an. Hier ein kurzes Beispiel in C#, wo wir mit einem führenden
@ Zeichen die literale Interpretation forcieren:
Listing 27: Literale Stringinterpretation in C#
Die Ausgabe dieses Codes ist:
Zeichensätze – es kommt darauf an was man erwartet
Wir können also mit diesem Wissen nun alle möglichen Zeichen in unsere Strings einbauen und über einen Schreibzugriff diese in Files ablegen.
Ein wichtiger Punkt fehlt uns an dieser Stelle jedoch noch. Wir haben in
Kapitel 6 festgestellt, dass wir mit den 8 Bit pro Zeichen nur 256 verschiedene Zeichen darstellen können, weshalb es unterschiedliche Zeichensätze für unterschiedliche Zielgruppen gibt – sprich unterschiedliche
Zuordnungen von Zeichen zu den einzelnen Zahlencodes. Nutzen wir mal C#, um einen Text mit einer festgelegten Codierung zu schreiben:
Listing 28: Schreiben eines Textfiles in C#
Wenn wir dieses File nun mit einem Texteditor öffnen, sehen wir den zu erwartenden Text:
Ändern wir nun unseren geschriebenen Text ab und fügen einen Umlaut hinzu:
Listing 29: Schreiben eines Textfiles mit Umlaut in C#
Unser Texteditor kann also das „ö“ nicht interpretieren. Wenn wir mit unserem Bytereader das File lesen, sehen wir für das „ö“ folgenden Hexcode:
3f. Dies ist aber exakt der Code für das Fragezeichen ?. Dies ist insofern sinnvoll, als dass ASCII nur 128 Zeichen kennt und das „ö“ gar nicht vorgesehen ist. C# platziert also für alle unbekannten
Zeichen das Fragezeichen. Nun versuchen wir einen Zeichensatz, welcher die Umlaute beinhalten müsste – Latin1:
Listing 30: Schreiben eines Textfiles mit Umlaut in C#
Nun ist die Ausgabe korrekt:
Wenn wir die Bytes wieder auslesen sehen wir, dass das „ö“ als
F616 abgelegt wurde – also außerhalb des ASCII Bereiches, was nicht überraschend ist. F616 ist ja mit dezimal 246 auch außerhalb der ersten 128 Zeichen.
Die zusätzlich für Latin1 benötigten Zeichen wurden also auf die Zeichen von 128 bis 255 gelegt. Soweit scheint nun alles gut zu sein – aber eben nur fast. Wenn wir das File mit einem anderen Editor, wie bspw.
Notepad++ öffnen, erhalten wir wieder etwas Seltsames (zumindest, wenn der Zeichensatz auf UTF-8 eingestellt ist).
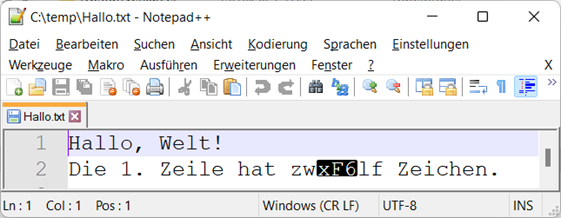
Abb.: 4: Fehldarstellung Umlaut in Notepad++
Es scheint dem Programm Probleme zu bereiten ein Zeichen außerhalb des ASCII Bereiches anzuzeigen. Dieses Verhalten beobachten wir bei allen Texteditoren, welche versuchen, das File im UTF-8 Format zu
öffnen. Notepad++ zeigt dies übrigens in der Fußzeile an(2). Die wichtige Erkenntnis hier ist, dass wir – sofern wir uns außerhalb des ASCII Bereiches bewegen – den Text mit genau
dem Zeichensatz öffnen müssen, mit dem wir ihn auch geschrieben haben. Passen wir unser Programm nun nochmal an und codieren mit UTF-8:
(2) Die meisten Editoren versuchen irgendwie den richtigen Zeichensatz aus dem Kontext zu „erraten“ – auch Notepad.exe und Notepad++,
wobei wir bei letzerem den Zeichensatz über das Kodierungsmenü oder einem Doppelklick auf den Zeichensatz in der Fußleiste einfach einstellen können.
Listing 31: Schreiben eines Textfiles mit Umlaut in C# - UTF-8 codiert
Nun haben wir auch in Notepad++ die korrekte Darstellung:
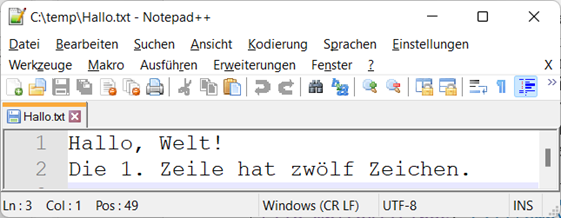
Abb.: 5: Richtige Darstellung des Umlauts in Notepad++
Wenn wir nun in Notepad++ die Kodierung auf ANSI umstellen, dann sehen wir folgendes:
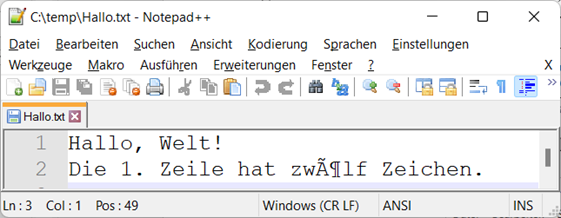
Abb.: 6: Fehlinterpretation UTF-8 als ANSI
Interessanterweise zeigt uns Notepad++ nun zwei Zeichen anstatt dem einen „ö“ an. Wenn wir uns die Bytes ansehen, wird dies auch bestätigt. „ö“ wird mit den Bytes
C316 und B616 dargestellt, was in ANSI eben die beiden Zeichen à und ¶ sind. Dies lässt darüber hinaus einen recht interessanten Blick auf das Konzept von
UTF-8 zu. Die ASCII Zeichen (also Zeichen 0 bis 127) können 1:1 in UTF-8 abgebildet werden. Der Rechner erkennt dies an der führenden 0 im Bitmuster. Sobald dieses Bit auf 1 ist, muss mindestens das nächste Bit
interpretiert werden. Die folgende Tabelle(3) zeigt das Konzept auf:
(3) Aus RFC 3629
| Anz. Bytes: | Bitmuster der Bytes (x = frei belegbar):: | Anzahl theoretisch möglicher Zeichen: | |||
|---|---|---|---|---|---|
| Byte 0: | Byte 1: | Byte 2: | Byte 3: | ||
| 1 | 0xxxxxxx | 27 = 128 | |||
| 2 | 110xxxxx | 10xxxxxx | 211 = 2.048 | ||
| 3 | 1110xxxx | 10xxxxxx | 10xxxxxx | 216 = 65.536 | |
| 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 221 = 2.097.152 |
Tabelle 3: Bitbelegung bei UTF-8
Man mag jetzt fragen, warum die ersten Bits ab Byte 1 jeweils mit 10 belegt sind. Der Hintergrund ist, dass man mit diesem Bitmuster alle Folgebytes sofort erkennen kann und darüberhinaus, dass die Sequenz
00000000 vermieden wird (diese wird mitunter als das Ende einer Übertragung oder als NULL Terminierer von Strings interpretiert). Weiterhin erklärt dies, warum nicht jede Bytekombination mit führenden Bits,
welche bspw. durch Latin1 erzeugt wird, als UTF-8 interpretiert wird, sondern mitunter Fehlercodes ausgibt, wie wir in Abbildung 4 gesehen haben.
Grundsätzlich ist die Empfehlung, Texte immer in UTF-8 zu schreiben, es sei denn ein triftiger Grund spricht dagegen, wie bspw., dass ein Empfänger kein UTF-8 „versteht“. Da wir in unseren Texten ohnehin die
meisten Zeichen im ASCII Bereich wiederfinden, fällt der erhöhte Speicherbedarf aufgrund der Folgebytes nicht weiter ins Gewicht. Ein weiterer Begriff, welche bei UTF-8 öfter auftaucht ist „BOM“, was für
Byte Order Mark steht und im Wesentlichen für die Angabe der Byte Reihenfolge (also Big vs. Little Endian) verschiedener UTF-codierungen eingesetzt wird und im Regelfall weggelassen weggelassen werden kann
(die Reihenfolge steht bei UTF-8 ohnehin fest und für den Fileaustausch wird fast ausschließlich UTF-8 verwendet).
Es gibt jedoch (einige wenige) Programme, welche anhand der Anfangssequenz 0xEF, 0xBB, 0xBF erst mal davon ausgehen, dass es sich um ein UTF-8 codiertes File handelt - also eine Art Erkennungssequenz für UTF-8.
Sehen wir uns nun die UTF8-Codierung in einer Programmiersprache an, in der man sehr viel allgemeiner an das Codierungsthema herangehen kann – nämlich Java. Die Idee von Java war ja, dass man auf allen
Systemen entwickeln und das Ergebnis auf allen Systemen ausführen kann. Deshalb muss man an einigen Stellen sehr genau wissen, was man macht, da Java nicht auf ein System hin optimiert sein kann. Wir werden hierzu
mal den kompletten Weg von Strings nach Bytes und wieder zurück ansehen, wie er in
Abbildung 1 dargestellt wurde. Beginnen wir mit dem Schreiben von Strings in ein File. Hierzu verwenden wir drei Objekte, den bereits bekannten
FileOutputStream, um die Bytes am Ende zu Schreiben. Diese holt er sich von dem
OutputStreamWriter, der den Text über die UTF-8 Zeichentabelle codieren soll. Zum effizienteren Schreiben erzeugen wir den Zeichenstrom übern einen
BufferedWriter, der den Text dann zeilenweise schreibt und dabei die Filezugriffe optimiert. Wenn wir den Code schreiben, dann sollte (nur für dieses Beispiel) der VSCode Editor auf UTF-8 eingestellt sein.
Dies sieht man im unteren Bereich und kann dort ggf. auch umstellen:
Listing 32: Einzelschritte beim Schreiben von Textdaten in Java
Kurze Erklärung der Codezeilen: Wie oben erwähnt übernimmt der
BufferedWriter die Aufgabe des Schreibens auf Stringebene und darüberhinaus noch das Setzen des Zeilenumbruchs, der
OutputStreamWriter die Codierung und der
FileOutputStream die Kommunikation mit dem Filesystem. Den
OutputStreamWriter können wir mit einem Parameter auf die gewünschte Codierung einstellen – in unserem Fall UTF-8. In der Schleife wird dann lediglich Zeile für Zeile mit einem
Zeilenumbruch in das File geschrieben. Das Ganze wird mit einem automatischen Ressourcenmanagement erledigt, so dass wir uns das
catch und
finally sparen können.
Den Aufruf im Hauptprogramm lösen wir wie folgt:
Listing 33: Aufruf der Schreibfunktion in Java
Nun kompilieren wir das Programm „von Hand“, da ich sicherstellen möchte, dass bei allen Lesern das gleiche Ergebnis herauskommt. Das Problem für die Nachvollziehbarkeit dieses Beispiels liegt darin, dass Java sich im Regelfall
beim Betriebssystem darüber „informiert“, welcher Zeichensatz genommen werden soll. Dieses Verhalten umgehen wir aber, so dass bei allen – egal welches Betriebssystem genutzt wird - das Gleiche herauskommt. Hierzu gehen wir im
VSCode Terminal auf das passende Verzeichnis und kompilieren mit dem Befehl:
Danach starten wir das Programm mit:

Abb.: 7: Compilerbefehl für Javac mit Encoding
Wenn wir nun das vom Programm erstellte Textfile als UTF-8 Text mit einem Editor öffnen, erleben wir wieder mal eine Überraschung:
Mehr noch – wenn wir ihn nun in Notepad++ mit ANSI öffnen, wird es noch merkwürdiger:
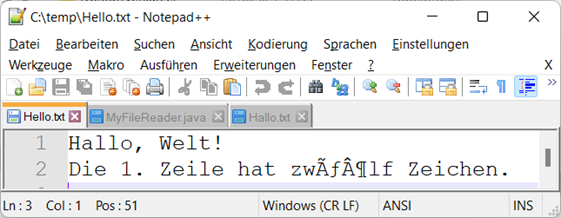
Abb.: 8: Fehlinterpretation des UTF-8 geschriebenen Textes
Wir haben nun aus dem „ö“ vier Zeichen (ö) gemacht, obwohl wir das Textfile im richtigen Format geschrieben haben. Was ist hier nun geschehen? Das Problem liegt an dieser Stelle bereits in der Interpretation des
Sourcecodes durch den Java Compiler. Dieser liest das Sourcefile auch bereits mit einer Interpretation durch eine Zeichensatztabelle ein - genau das haben wir ja beim Kompiliervorgang eingestellt.
Wenn das jedoch nicht explizit vorgegeben ist, „erkundigt“ er sich beim Betriebssystem. Dieses gibt ihm jetzt bspw. das ISO8859-1 Format (also ein Format mit nur einem Byte pro Zeichen) vor und der Compiler liest die beiden
Bytes des Zeichens „ö“ aus dem UTF-8 codierten Sourcefile und „glaubt“, es handelt sich um „ö“. Diese beiden Zeichen werden nun vom
OutputStreamWriter als zwei UTF-8 Zeichen mit je zwei Bytes (also vier in Summe) codiert, was unser Texteditor im UTF-8 Format auch korrekt angegeben hat. Durch die Ansicht im ANSI Format wurden dann wieder
die vier Bytes mit einem entsprechenden Zeichen ausgegeben.
Die Frage ist nun, wie wir mit solchen Situationen umgehen. Hier gibt es zwei Antworten. Die erste ist – im Sourcecode haben Zeichen außerhalb ASCII nichts verloren! Wir sollten immer die Nutzung von nicht
ASCII Zeichen in unserem Sourcecode vermeiden. Klartextinformationen, welche bspw. Umlaute enthalten und für die Userführung bei der Textanzeige genutzt werden müssen, sollten immer in ein eigenes Textfile
ausgelagert werden, welches zur Laufzeit vom Programm gelesen wird. Dies hat zwei Vorteile. Erstens gehen wir damit der oben genannten Problematik aus dem Weg. Zweitens können wir somit sehr schnell unser
Programm auf eine andere Sprache ändern – es muss lediglich das Textfile mit den Sprachbausteinen ausgetauscht werden (sofern die Sprachbausteine sinnvoll grammatikalisch geschnitten sind).
Die zweite Antwort auf den Umgang mit der Codierungsproblematik im Sourecode ist, dass wir dem Compiler ja mitteilen können, dass der Sourcecode im UTF-8 Format vorliegt:
Diese Option würde ich aber nur dann empfehlen, wenn Option 1 aus irgendeinem Grund nicht tragbar ist. Sehen wir uns nun den umgekehrten Weg an – wie wir ein Textfile aus dem Bytestrom wieder lesen:
Listing 34: Lesen eines Bytestroms als Text in Java
Kurze Erklärung der Codezeilen: Das Vorgehen ist mit dem Text schreiben durchaus vergleichbar. Aus „Reader“ werden „Writer“ und aus „Output“ wird „Input“. Der
BufferedReader liest das File nun Zeile für Zeile aus und gibt es auf der Konsole aus. Wenn der Reader am Ende des Files angekommen ist, liefert
readLine() null zurück, womit wir die Leseschleife abbrechen können.
In der Praxis verwenden wir jedoch nicht den hier gezeigten Weg über einen eigenen Bytestrom aus dem
FileInputStream bzw.
FileOutputStream, sondern vielmehr Methoden, welche diese Mechanik schon intern umgesetzt haben. Java würde aus der Bibliothek
java.nio.* die Methode
Files.newBufferedReader() vorsehen:
Listing 35: Lesen eines UTF8 codierten Files mit einer integrierten Funktionalität aus java.nio.*
Gleiches finden wir übrigens für das Schreiben eines Files:
Listing 36: Schreiben eines UTF8 codierten Files mit einer integrierten Funktionalität aus java.nio.*
C# wiederum liefert hier eine noch einfachere Lösung – zumindest, wenn man für‘s Erste wenig Wert auf das Errorhandling legt:
Listing 37: Schreiben eines UTF8 codierten Files mit einer integrierten Funktionalität in C#
Und wenig überraschend auch ein Pendant für das Schreiben:
Listing 38: Lesen eines UTF8 codierten Files mit einer integrierten Funktionalität in C#
In C ist die Sache naturgemäß etwas umständlicher zu realisieren. Wichtig zu verstehen ist, dass C in seinem ursprünglichen Ansatz einzelne Zeichen „nur“ mit einem Byte abbildet, weshalb die Umsetzung von
UTF-8 Zeichensätzen relativ Aufwendig, bzw. für einen Programmieranfänger fast nicht zu bewältigen ist. C nutzt einfach die Codepage, welche vom System vorgegeben wird und bleibt dabei. C++ bietet hier zwar
mit der Einführung des Datentyps
wchar_t (wide char)x etwas mehr „Comfort“, jedoch im Vergleich zu Java und C# liegen hier noch Welten dazwischen. Insofern beschränke ich mich hier lediglich darauf, in C normale ASCII Texte zu verarbeiten
und rate denjenigen, welche in C oder C++ internationalen Code schreiben müssen, sich dieses Thema in aller Ruhe anzueignen. Beginnen wir also mit einem einfachen Textreader:
Listing 39: Einfacher Textreader in C
Kurze Erklärung der Codezeilen:
fopen() öffnet das File im Lesemodus
(„r“). Die für den Buffer maximalen Bytes sollten als Konstante definiert werden, da wir sie sowohl für die Erzeugung des Buffers, als auch für die
fgets() Funktion benötigen. Die Tatsache, dass C die Arraylänge nicht ohne weiteres bestimmen kann, macht dies wieder nötig. Da wir vorab nicht wissen, wie lang der Text im File sein wird, müssen wir über eine
Schleife den Lesevorgang solange wiederholen, bis
fgets() ein
false (bzw. 0) zurückliefert, was das Ende des Files indiziert.
Das Pendant zum Schreiben von Text sieht in C wie folgt aus:
Listing 40: Einfaches Programm zum Schreiben von Strings in C
Kurze Erklärung der Codezeilen: Nach dem Öffnen des Files im Schreibmodus
(„w“) wird lediglich der String geschrieben. Zeilenumbrüche müssen hier als
„\n“ codiert enthalten sein – wir setzen die Zeielnumbrüche also nicht beim Schreiben wie in Java, wo wir den
content als Stringarray erhalten haben. Da in C ein String ohnehin nur ein Array von
char ist, ist es nicht wirklich sinnvoll content als Stringarray umzusetzen.
JavaScript und PHP sind in puncto Schreibzugriffe eher unwichtig, da wir diese Sprachen meist im Webbereich nutzen und hier Daten weniger im Filesytem als mehr auf Datenbanken geschrieben werden.
Trotzdem zeige ich hier kurze Codebeispiele für den Zugriff, jedoch ohne groß auf die Details einzugehen. Beginnen wir mit JavaScript, wo wir die Filezugriffe nur innerhalb
node.js sinnvoll nutzen können. Browserseitige Skripte sind ohnehin nicht der richtige Ort um Filezugriffe umzusetzen:
Listing 41: Lese- und Schreibfunktionen für Text in JavaScript
PHP erlaubt keine Konfiguration von
fwrite() und
fread() bezüglich des Encodings. Da PHP ohnehin „nur“ für den Webbereich genutzt wird, stellt man das Encoding zentral im Header ein. Für die interne Verarbeitung nutzt PHP die lokalen Charset Einstellungen.
Speziellere Anforderungen erfordern eigene Module, wie
iconv(4). Das Errorhandling habe ich hier kurzerhand weggelassen – eine Prüfung auf Existenz von
$fp wäre eine gängige Möglichkeit das Öffnen zu validieren:
(4) https://www.php.net/manual/de/book.iconv.php
Listing 42: Einfaches Lesen und Schreiben von Text in PHP
Python bietet naturgemäß mehr Möglichkeiten für das Filehandling an, als PHP oder auch JavaScript. Die folgenden Beispiele verzichten wieder auf das Errorhandling. Wer es trotzdem einbauen möchte, muss für
open() mindestens den Error
OSError abfangen(5).
(5) Weitere Details unter https://docs.python.org/3/library/functions.html#open
Listing 43: Einfaches Lesen und Schreiben von Text in Python
Bei einigen Systemen müssen wir die Ausgabe von
stdout erstmal auf UTF-8 umstellen. Dies ist nur dann notwendig, wenn Python in der Konsolenausgabe nicht UTF-8 verwendet. Ansonsten sollte der Code selbster-klärend sein.

CC Lizenz (BY NC SA)