
Alles unter Kontrolle mit den Kontrollstrukturen
Bis jetzt haben wir uns um technische Grundlagen gekümmert – zugegebenermaßen nicht das spannendste Thema. Trotzdem
war es wichtig, die Details hinter den Kulissen kennen zu lernen. Den nächsten Schritt in Richtung Programmieren haben
wir eigentlich implizit schon gemacht, indem wir uns schon mit Verzweigungen und Schleifen beschäftigt haben. Das war
in den vorausgegangenen Kapiteln unumgänglich, da wir das Verhalten der einzelnen Elemente untersuchen mussten.
In diesem Kapitel möchte ich aber auf die einzelnen Kontrollstrukturen tiefer eingehen, damit wir sie nicht nur
anwenden können, sondern auch verstehen, warum sie so aussehen, wie sie eben aussehen. Unter Kontrollstrukturen verstehen
wir die Elemente, welche die Abarbeitung unseres Codes koordinieren und somit auch die Grundlage für unsere in Code
gegossene Algorithmen bilden. Hierbei werde ich auch eine neue Notation für Algorithmen vorstellen, welche sich sehr
viel näher an der eigentlichen Programmierung orientiert als der Programm Ablauf Plan „PAP“, den wir in
Kapitel 3
kennengelernt haben. Definiert wurde dieser Diagrammtyp Anfang der Siebziger von den beiden Herren Nassi und
Shneidermann, weshalb das Diagramm als
„Nassi-Shneidermann-Diagramm“
bezeichnet wird. Der kürzere und prägnantere Ausdruck
„Struktogramm“ ist jedoch gebräuchlicher.

Sequenz
Beginnen wir mit der einfachsten Struktur, der Sequenz – auch wenn es trivial ist. Unter der Sequenz verstehen wir die
simple Abarbeitung von einem Befehl nach dem anderen. Im PAP würden wir einfach die Elemente untereinander setzen und
mit Pfeilen verbinden. Sehen wir uns den Algorithmus für die Umfangberechnung eines Quadrats an:
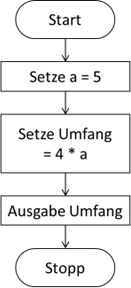
Abb.: 1: Umfangberechnung eines Rechtecks als PAP
Auch wenn es trivial ist, hier der Code am Beispiel von Java:
Listing 1: Umfangberechnung eines Rechtecks in Java
Was uns im Vergleich zum PAP auffällt, ist dass wir keinen Code für Start und Stopp haben, wobei wir das zur Not in
die geschweiften Klammern der
main-Methode hineininterpretieren könnten. Was aber definitiv fehlt, sind die Pfeile. Unser Rechner arbeitet die
einzelnen Befehle von oben nach unten ab. Unser PAP-Diagramm könnten wir auch von links nach rechts, rechts nach links
oder sogar von unten nach oben zeichnen, solange die Pfeile die richtige Richtung vorgeben, ist alles nachvollziehbar.
Ob das nun sinnvoll ist oder nicht, sei mal dahingestellt – alles was möglich ist wird früher oder später auch irgendwo
so mal gemacht. Wenn wir unser Diagramm jetzt aber dem Code angleichen müssten, dann würde es so aussehen:

Abb.: 2: Umfangberechnung eines Rechtecks als Struktogramm
Wir lassen also alles nicht Notwendige weg und erhalten damit die Sequenzdarstellung in Struktogrammform.
Verzweigung
Soweit die triviale Struktur der „Sequenz“. Wie sieht es denn mit einer Verzweigung aus? Die hatte ja in der
PAP-Darstellung einen „gewissen Charme“:
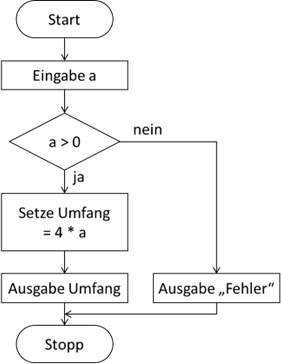
Abb.: 3: Verzweigung in PAP
Die Verarbeitung ist auf jeden Fall für jeden, auch ohne IT-Vorkenntnisse gut zu verstehen. Dies ist der Grund, warum
das „Flussdiagramm“ auch in vielen anderen Bereichen eingesetzt wird. Aber sehen wir uns wieder den Code in Java für
diesen Algorithmus an:
Umfangberechnung eines Rechtecks in Java mit Verzweigung
Kurze Erklärung der Codezeilen: Die Option einer Eingabe über die Konsole, wie wir sie in C programmieren können, gibt
es in Java auch, womit wir neben der
JOptionPane eine zweite Möglichkeit für Nutzereingaben kennenlernen. Damit dies jedoch funktioniert, müssen wir den Code
in der Konsole starten, da der CodeRunner in der Standardeinstellung keine Konsoleneingabe zulässt. Hierfür müssen wir
javac UmfangQuadrat.java eingeben um den Code manuell zu kompilieren und anschließend
java UmfangQuadrat für die Ausführung. Der Scanner erlaubt es uns nun, bei der Übernahme der
Eingabe diese gleich im richtigen Datentyp zu übernehmen – in unserem Fall
double. Nach der Nutzung müssen wir ihn mit
scanner.close(); auch wieder schließen, damit er keine Systemressourcen unnötig belegt. Die eigentliche Verzweigung wird in
Java über das Schlüsselwort
„if“ eingeleitet, gefolgt von der Bedingung in Klammern. Die Bedingung muss ein
boolean Wert sein. Die geschweiften Klammern leiten den Block ein, der bei einer wahren Aussage abgearbeitet wird. Wenn
wir bei einer falschen Aussage auch einen Verarbeitungsblock haben wollen, so benötigen wir das Schlüsselwort
else, wieder gefolgt von einem geschweiften Klammernpaar.
Das Besondere an der Verzweigung ist nun, dass der
„true“ und der
„false“ Zweig je ein zusammenhängender Codeblock ist, welcher direkt an der Bedingung hängt. Dadurch, dass Java das
Semikolon für den Befehlsabschluss benötigt, könnte man den Code auch wie folgt formatieren (auch wenn dies absolut
unüblich wäre):
Listing 3: Umformatierte if-Abfrage in Java
Die Struktogrammnotation der Verzweigung orientiert sich genau an dieser Darstellung:
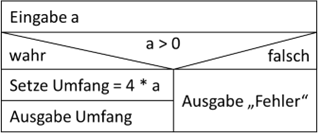
Abb.: 4: Umfangberechnung eines Rechtecks mit Verzweigung als Struktogramm
Es ist übrigens nicht wichtig, ob „wahr/falsch“, „true/false“, „ja/nein“ oder „1/0“ in den Dreiecken steht und ob der
Wahrzweig links oder rechts notiert wird. Da weiterhin im Code der sogenannte „Elsezweig“ (also im Struktogramm
„Falschzweig“) auch weggelassen werden kann, dies aber in der Grafik nicht möglich ist, würde man in solch einem Fall
den Zweig unterhalb „falsch“ einfach leer lassen oder das Fehlen von Anweisungen mit einem Querstrich nochmal
untermauern. Man erkennt nun, dass sich die Struktogramme sehr stark an den syntaktischen Ideen von Code orientieren.
Für den Laien sieht ein Struktogramm zwar komplizierter aus als ein vergleichbarer PAP, der Programmierer wird aber
bei der Umsetzung von Strutktogrammen weniger Probleme vorfinden, da das Struktogramm ihm sozusagen auf „halben Weg
entgegenkommt“.
Gehen wir aber noch auf ein paar Details ein. Die Aussage, dass innerhalb der Bedingung ein boolescher Ausdruck stehen
muss, ist hier nochmal hervorzuheben. Wir können den Java Code somit auch wie folgt umbauen:
Listing 4: Umfangberechnung eines Rechtecks in Java mit Verzweigung und boolean Variable
Der Vorteil dieses Ansatzes ist, dass wir dem Ergebnis der Prüfung einen Namen geben können. Wenn wir die Variablen
geeignet benennen, so wird der Code einfacher lesbar – vor allem, wenn wir kompliziertere Strukturen programmieren.
Natürlich würde man bei einem solch einfachen Algorithmus nicht auf die Idee kommen, die Prüfung in einer
boolean Variablen auszulagern, aber das Prinzip sollte klar sein. Nun haben wir aber in
Kapitel 6 gesehen, dass es Programmiersprachen gibt,
bei denen die 0 wie
false und 1 wie
true gewertet wird. Insofern können wir in diesen Sprachen auch folgende Logik ausführen:
Listing 5: int als Bedingung in C
Kurze Erklärung der Codezeilen:
i wird als int Variable erzeugt und mit einem Wert – hier 0 belegt. In der Verzweigung wird nur auf i geprüft. Jeder
Wert außer 0 würde somit den Text „i ist ungleich 0“ ausgeben lassen.
Dieses Verhalten würden die Sprachen C, C++, Python, JavaScript und PHP an den Tag legen. Gerade bei den Skriptsprachen
gibt es aber noch eine weitere Besonderheit. Objektvariablen, welche
„null“ sind, würden ebenfalls als
„false“ gewertet und alle anderen als
„true“. Sehen wir uns das in PHP an, wo dieses Konzept häufiger verwendet wird:
Listing 6: "null" Prüfung in PHP
Die Ausgabe würde lauten:
Wenn wir in dem Code die erste Zeile durch
$ar = null; ersetzen, würde die Ausgabe auf „ar nicht vorhanden“ springen. Dieses Verhalten können wir bei PHP,
JavaScript und Python beobachten. An dieser Stelle möchte ich aber noch auf eine weitere Besonderheit von Python
hinweisen. Python kennt den Zustand
„null“ nicht, wodurch man nicht
ar = null schreiben kann. Man hat stattdessen das
„None“ Objekt eingeführt, was zwar die gleiche Bedeutung wie
„null“ hat, aber eben ein „Objekt“ mit Eigenschaften ist. Trotzdem würde ein
if None: als
false gewertet werden.
Eine ebenfalls häufig in den Bedingungen von Verzweigungen auftretenden Elemente sind Methodenaufrufe, welche natürlich
auch
boolean Werte ausgeben müssen. Treiben wir unseren simplen Code nun endgültig auf die Spitze und probieren es aus:
Listing 7: Umfangberechnung eines Rechtecks in Java mit Verzweigung und Methodenaufruf
Auch hier gilt natürlich, dass ich mit „Kanonen auf Spatzen“ schieße – aber wie immer geht es um das Wesentliche.
Bevor wir uns nun den Syntax in anderen Sprachen ansehen, noch ein kleiner Vorgriff auf das Kapitel über die
Operatoren. Erfahrene Programmierer neigen dazu, möglichst viel in eine Zeile zu packen. Das hat oftmals
„ästhetische“ Gründe, manchmal aber liegt der Grund auch in der verbesserten Performance, da die Werte während der
Ausführung seltener vom System geladen werden müssen. Sehen wir uns eine neue „Eskalationsstufe“ unseres kleinen
Programms an:
Listing 8: Umfangberechnung eines Rechtecks in Java mit Verzweigung und kombinierter Zuweisung/Vergleich
Kurze Erklärung der Codezeilen: Wir haben also die Zuweisung von
a aus dem Scanner eingeklammert und direkt in den Vergleich mit 0 gesetzt. Dadurch haben wir uns den zweimaligen Zugriff
auf
a gespart. Das Schließen des Scanners müssen wir natürlich jetzt nach der gesamten Verzweigung platzieren, da wir ihn sonst
vor dem eigentlichen Scanvorgang schließen würden – was selbstverständlich zu einem Fehler führen würde.
Solche Konstrukte sehen wir in Verzweigungen zwar seltener, aber bei Schleifen, welche ebenfalls
boolean Bedingungen aufweisen, wird es relativ häufig so codiert. Entscheidend ist die Klammer um die Zuweisung. Java
verarbeitet die Klammer zuerst und „ersetzt“ den gesamten Klammerausdruck durch den übergebenen Wert, wodurch der Vergleich
möglich wird. Sehen wir uns die anderen Programmiersprachen an. Die gute Nachricht: in fast allen anderen Programmiersprachen
funktioniert der Code genauso wie in Java. Das liegt primär daran, dass sich (fast) alle modernen Programmiersprachen
diesbezüglich in irgend-einer Form an C orientiert haben. Insofern werde ich in diesem Kapitel nur auf die Programmiersprachen
eingehen, welche andere Syntaxregeln aufweisen als die Mehrheit der hier reflektieren Sprachen.
Python wird in diesem Kapitel immer die große Ausnahme sein, da die Python Entwickler sich die Simplifizierung des Codes
auf die Fahnen geschrieben haben und somit von den „alten“ Standards aus C abweichen mussten. Beispielsweise unterstützt
Python die kombinierte Zuweisung und den gleichzeitigen Vergleich innerhalb der Bedingung nicht. Insofern sind wir hier
gezwungen, die Variablenzuweisung in einer eigenen Codezeile durchzuführen. Das liegt mitunter daran, dass Python der
Zeile und somit dem Zeilenumbruch eine semantische Bedeutung zugeordnet hat. Dies ist in den anderen Programmiersprachen
nicht so – hier wird es durch das Semikolon erreicht. Sehen wir also die Python Lösung an:
Listing 9: Umfangberechnung eines Rechtecks in Python
Kurze Erklärung der Codezeilen: Wie bei Java auch, müssen wir den Code in der Konsole mittels
python BranchTest.py manuell starten, damit die Eingabe möglich ist. Die Eingaberoutine für die Konsole ist in Python
input(). Da diese einen Parameter für die Userinformation benötigt, schreiben wir hier kurzerhand „Eingabe:“ hinein. Der
Rückgabetyp von
input ist ähnlich wie die
JOptionPane in Java ein
String, weshalb wir ihn mit
float() in eine Gleitkommazahl umwandeln müssen. Wie weiter oben schon erwähnt, verzichtet Python auf die Klammern, da
die zusammengehörigen Blöcke über Einrückungen definiert werden. Die Bedingung kann wie in Java auch ein Programmaufruf
sein. Ebenfalls ist eine
boolean Variable möglich, aber auch ein Zahlenwert würde funktionieren, und somit eine
int Variable. Hier würde 0
„false“ bedeuten und alle anderen Zahlenwerte
„true“, so wie es in C bzw. C++ auch möglich wäre.
Die Tatsache, dass in Python die 0 bzw. 0.0 als
„false“ und alle anderen Zahlen (inklusive der Gleitkommawerte) als
„true“ gewertet werden, gilt für alle drei hier beschriebenen Skriptsrapchen Python, JavaScript und PHP, eben wie in
C und C++. Gehen wir nochmal kurz den Syntax der Verzweigung durch:
| Notation: | Beispiel: |
|---|---|
| Struktogramm: „Bedingung“ ist eine „geschlossene Frage“. Sie kann nur mit „ja“ oder „nein“ bzw. „wahr“ oder „falsch“ beantwortet werden. In den Aktionsblöcken für „wahr“ bzw. „falsch“ können wieder beliebig verschachtelte Struktogrammelemente eingetragen werden, bzw. leer gelassen werden, sofern sie nicht benötigt werden. |
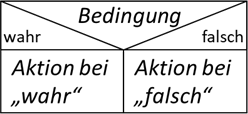 |
| Java, C#, C, C++, JavaScript, PHP: “Bedingung” muss vom Typ “boolean“ bzw. bei den Skriptsprachen, C und C++ auch eine Zahl sein. Der Falschzweig (also Elsezweig) ist optional und darf somit komplett entfallen. Die geschweiften Klammern dürfen entfallen, wenn im Wahr- bzw. Falschzweig nur ein Befehl steht. Es wird aber ausdrücklich empfohlen, auf die Klammern nicht zu verzichten. Die Einrückungen sind optional und helfen nur der allgemeinen Lesbarkeit. |
 |
| Python: Wie bereits erwähnt, verzichtet Python auf Klammern, weshalb die Einrückung hier zwingend vorgeschrieben sind. Im Regelfall wird um 4 Spaces eingerückt. Wichtig ist, dass die Anzahl bei den zusammenhängenden Blöcken identisch ist. |
 |
Tabelle 1: Gegenüberstellung Syntax Verzweigung und Kontrollstruktur Element
Wenn wir uns an das Zahlenrätselbeispiel von
Kapitel 3 erinnern, hatten wir hier zwei verschachtelte Verzweigungen. Sehen wir uns das Struktogramm für diesen Teil des Algorithmus mal an:
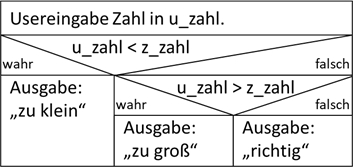
Abb.: 5: Verschachtelte Verzweigung
Eine Möglichkeit, diesen Code umzusetzen wäre entsprechend des Struktogramms wie folgt gewesen:
Listing 10: Verschachtelte Verzweigung in JavaScript
Wir haben also „streng nach Vorschrift“ gehandelt und die Prüfung
u_zahl > z_zahl als Unterstruktur in den Falschzweig eingetragen. Das macht den Code leider nicht sehr übersichtlich.
Gehen wir ein noch extremeres Beispiel an, die Tageszeitdefinition für Sommer:
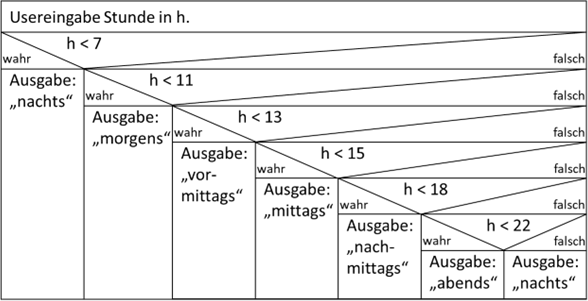
Abb.: 6: Tageszeitdefinition als Struktogramm
Diese Funktionalität als JavaScript Funktion würde wie folgt aussehen:
Listing 11: Verschachtelte Verzweigung in JavaScript
An den schier nicht enden wollenden schließenden Klammern sieht man zwei Dinge. Erstens, ohne saubere Einrückungen würden wir den Code sicher
nicht fehlerfrei schreiben können. Zweitens ist diese Konstruktion als solches nicht wirklich programmiererfreundlich. Da solche Konstrukte
(wie sie im Struktogramm aber angegeben sind) häufiger benötigt werden, gibt es in den einzelnen Programmiersprachen eine übersichtlichere
Lösung, das sogenannte
„else if“:
Listing 12: Verschachtelte Verzweigung in JavaScript mit else if
Wir ziehen einfach das if des nächsten Blocks zu dem
„else“. Dadurch ersparen wir uns das Klammernpaar für das
„else“ und können somit auch auf die Einrückungen verzichten. Dieser Notation des
„else if“ funktioniert wieder in C, C++, C#, Java, JavaScript und PHP. Python stellt wieder die Ausnahme dar. Hier wird das
„else if“ zusammengeschrumpft auf
„elif“.
Mehrfachauswahl
Man kann nun ebenfalls behaupten, dass die verschachtelte Struktur in
Abbildung 6 bereits eine gewisse Unübersichtlichkeit vorgibt. Da aber eine Prüfung einer Variable
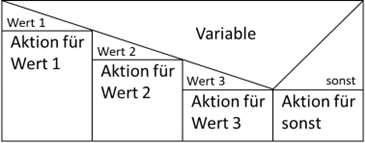
bezüglich mehrerer Werte relativ häufig vorkommt, wurde für die Struktogrammnotation ein weiteres Konstrukt definiert, die „Mehrfachauswahl“.
Diese ist genau auf solche Fälle zugeschnitten:
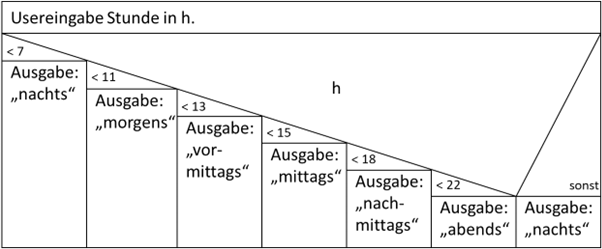
Abb.: 7: Mehrfachauswahl als Struktogramm
Wir finden also die auszuwertende Variable
„h“ im Dreieck, wodurch hier also kein boolean Ausdruck mehr steht. Die einzelnen Werte(bereiche) stehen nun anstatt „wahr/falsch“ und ganz
rechts haben wir einen (optionalen) Defaultwert. Dieses Konstrukt findet sich auch in den meisten Programmiersprachen wieder, wobei es hier
gilt, einige Einschränkungen zu beachten. Sehen wir uns die Entsprechung
„switch / case“ in JavaScript an:
Listing 13: Switch Case Range in JavaScript
Kurze Erklärung der Codezeilen: Das Statement heißt in fast allen Programmiersprachen
„switch/case“. In Sprachen wie Python, C, C++ und Java ist es allerdings nicht möglich, Ausdrücke wie
h < 15 einzutragen. Es sind in diesen Sprachen nur eindeutige Vergleiche mit
== möglich. Wir werden weiter unten ein Beispiel hierfür sehen. In JavaScript, C# und PHP ist jedoch eine Bereichsauswahl möglich.
Wenn eine solche in JavaScript umgesetzt wird, so wird als Switch Parameter
„true“ verwendet:
switch(true). Nach den
„case“ Schlüsselwörtern folgt die Prüfung der Variablen
h und nach dem Doppelpunkt steht der auszuführende Code.
case (h < 15): ist also eine Sprungmarke, auf die der Interpreter springt, wenn die Bedingung erfüllt ist. Da hier aufgrund überschneidender
Bedingungen mehrere Sprungmarken valide sein, wird die erste gültige verwendet – die Reihenfolge der Angaben ist also wichtig. Man kann dies
allerdings auch vermeiden, wenn man bspw.
(13 <= h && h < 15) angibt. Die Verarbeitung wird bis zum
„break“ fortgesetzt.
default markiert dann „alle anderen Werte“ und steht im Regelfall am Ende, weshalb hier auf das
break verzichtet werden kann.
Der Code funktioniert also 1:1 so, wie die
else if Anweisungen in
Listing 12. Diverse Performancemessungen haben allerdings ergeben, dass der Switch/Case mit
Bereichsvergleichen im Vergleich zu else if langsamer ist. PHP würde übrigens vom Code her genauso wie JavaScript aussehen. Anders sieht es bei
C# aus. Hier hat man den „Switch Case Range“ etwas anders umgesetzt:
Listing 14: Switch Case Range in C#
Hier fallen zwei Dinge auf. Zum einen steht in den Klammern nach
„switch“ nun nicht mehr
„true“ wie in JavaScript, sondern sehr viel sinnvoller die auszuwertende Variable. Dies ist insofern besser, als dass es näher an der Struktogrammnotation
angelehnt ist und vor allem auch die Idee, eine Variable auszuwerten, besser zu sehen ist. In JavaScript kann ich beliebige Variablen nach den
case Einträgen abprüfen. In C# ist das nun nicht mehr vorgesehen, wenngleich trotzdem noch über Umwege möglich. Die Verarbeitung erfolgt dergestalt, dass in
jedem
case Block der Wert von der
switch Variablen – in unserem Fall
„h“ in die dort deklarierte Variable übernommen wird – hier eben
„n“. Diese wird dann über den Vergleich geprüft, wobei dieser auch wie in JavaScript mit
&& auf mehrere Vergleiche erweitert werden kann. Das zweite, was auffällt ist, dass wir beim
default auch einen
break benötigen.
Nun habe ich weiter oben gesagt, dass
switch/case in fast allen Programmiersprachen existiert. Also muss es auch in Java, C & co. ebenfalls eine derartige Umsetzung geben – nur eben nicht mit Bereichsvergleichen.
Sehen wir uns hierfür folgenden beispielhaften Code in C an:
Listing 15: Switch Case in C
Dies ist eigentlich der Standardfall für
switch/case. Es wird eine Variable in
switch ausgewertet und mit eindeutigen Werten verglichen. In C darf diese Variable darüber hinaus nur ein Datentyp für ganzzahlige Werte sein. Nach dem
case dürfen auch nur Konstantwerte stehen, keine Variablen. Dieser Code funktioniert so 1:1 auch in C++, Java, JavaScript und PHP. In C# prinzipiell auch, lediglich das
„break“ wird dort auch für den
default Fall gefordert.
Python geht hier einen anderen Weg. Switch ist Stand Ende 2021 zwar angekündigt, aber eben nicht mehr. Man kann sich mit assoziativen Arrays behelfen und einigen anderen Konstrukten,
aber die eigentliche Switch/Case/Break Anweisung ist nicht darstellbar. Python bietet aber seit der Version 3.10 als „ähnliches“ Konstrukt den
match an. Dieser kann zwar sehr viel mehr als ein „normaler“ switch/case, da wir hier auch strukturierte Matches realisieren können, was bei zusammengesetzten Datentypen recht
praktisch sein kann – ich möchte mich aber hier auf die Funktionalität der Mehrfachauswahl basierend auf einem Variablenwert konzentrieren. Folgender Python Code würde dem
Listing 15 entsprechen:
Listing 16: Mehrfachauswahl als "match" in Python
Die
„default“ Sprungmarke wird hier als Unterstich
„_“ festgelegt. Weiterhin benötigt das
match/case Statement keinen
„break“ – die Ausführung bei einem
„match“ wird von der Sprungmarke bis zum nächsten
case durchgeführt. Das spart zwar Schreibaufwand, kann aber für andere Anwendungsfälle problematisch sein. Dieses
break, welches bei den meisten Programmiersprachen gefordert wird, ist zwar manchmal „nervig“ da es zwingend erforderlich ist, bietet uns aber die Möglichkeit für ein recht
praktisches Programmierpattern. Konstruieren wir uns hierfür mal ein Beispiel. Wir gehen davon aus, für eine Smartphone Spieleapp soll auf den einzelnen Geräten eine Datenbank
erstellt werden, in denen die Highscores des Spielers für die einzelnen Level ablegbar sind. Das Ganze wird in der Funktion
„createPlayerDB()“ der App programmiert und per Store an die User verteilt. Nach einer Zeit wird die Datenbank erweitert, da man noch die Spielzeiten tracken möchte. Dies wird
über die Funktion
„addPlyrTimeToDB()“ erledigt. Man hat also eine Version 2 der Datenbank, welche man an die Kunden ausliefern muss. Nach einer weiteren Phase möchte man die dritte Version der
Datenbank verteilen, in der noch Daten von online Spielepartnern mit aufgenommen werden sollen. Dies soll mit
„addOlPlyrToDB()“ erledigt werden. Das Problem ist aber, wir wissen nicht, ob bei der Verteilung der Version 3 jeder bereits die Version 2 oder die Version 1 in seiner App hat – bzw.
ist es sogahr wahrscheinlich, dass alle möglichen Situationen vorkommen. Dies bedeutet, wir müssen die Version der Datenbank erstmal erfragen und können dann entscheiden, welche
Aufrufe wir benötigen:
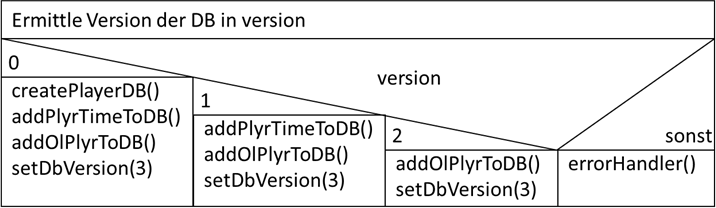
Abb.: 8: Versionierungsermittlung mittels Mehrfachauswahl
Der Code für die App für die Erstellung der Version 3 der Datenbank müsste bspw. in Java wie folgt aussehen:
Listing 17: Versionierungsermittlung in Java
Wie wir bereits gesehen haben, müssen die Aufrufe relativ redundant geschrieben werden. Das Problem lässt sich aber durch das Weglassen der
„break“ Statements relativ leicht umgehen:
Listing 18: Vereinfachte Versionierungsermittlung in Java
Kurze Erklärung der Codezeilen: Das
switch Statement wertet die Version aus. Wenn in der aktuell vorgefundenen Datenbank die Version 0 vorherrscht – also wenn sie gar nicht gefunden wurde, so springt der Interpreter in die
Sprungmarke
case 0:. Es wird
createPlayerDB() aufgerufen und somit die Version 1 erstellt. Jetzt folgt aber kein
break, sprich das
switch Statement wird weiter ausgeführt. Also wird danach der Code unter
case 1: ausgeführt – es wird
addPlyrTimeToDB() aufgerufen, wodurch die DB jetzt die Verison 2 hat. Danach fehlt wieder das
break und die Version 3 wird durch den Aufruf von
addOlPlyrToDB() erstellt. Danach muss das
break kommen, damit das Errorhandling für eine unerwartete Version in dieser Situation nicht aufgerufen wird. Sollte die ausgerollte Software allerdings eine andere DB
Version als 0 vorfinden – bspw. die Version 2, so wird der Code für
case 0: und
case 1: übersprungen.
Der Charme dieser Lösung ist (neben der Tatsache, dass es weniger Code ist), dass wir für die Version 4 die Einträge von Version 0 bis 3 nicht anfassen müssen. Es muss lediglich der
„case 4:“ vor dem
break eingefügt werden und man ist fertig. Dies ist aber nur möglich, weil wir im „Normalfall“ das
break in Java einsetzen müssen. Dieses Verhalten kann man jedoch nicht ohne weiteres im Struktogramm notieren.
| Notation: | Beispiel: |
|---|---|
| Struktogramm: „Mehrfachauswahl“ wertet die Variable aus und prüft, ob „Wert 1“, „Wert 2“ oder „Wert 3“ dort zu finden ist, wobei dies auch Wertebereiche sein dürfen. Die entsprechenden Aktionen unter den Werten werden ausgeführt. Bei Wertebereichen werden potentielle Überschneidungen von links nach rechts priorisiert. Findet sich kein passender Wert, so wird der „sonst“ Zweig verarbeitet. |
 |
| Java, C#, C, C++, JavaScript, PHP: Bei C# ist „break“ nach „default“ Pflicht. Bei den anderen Sprachen kann dies entfallen, sofern default am Ende steht. JavaScript, PHP und C# erlauben auch die Prüfung auf Wertebereiche. Hierzu wird in JavaScript und PHP im switch() anstatt „Variable“ einfach „true“ eingetragen und zwischen „case“ und „:“ ein boolescher Ausdruck (bspw. Vergleich) eingetragen. In C# bleibt die Variable im switch(), stattdessen wird pro case eine Variable deklariert, welche wiederum über einen booleschen Ausdruck verglichen wird (bspw. int n when n > 10). Sollten für C, C++ und Java pro case ein Wertebereich gefordert sein, so muss dies über else if gelöst werden. In C und C++ muss die Variable ein ganzzahliger Datentyp sein. |
 |
| Python: Python kennt kein switch/case. Stattdessen wird „match“ verwendet. |
 |
Tabelle 2: Gegenüberstellung Syntax Mehrfachauswahl und Kontrollstruktur Element
Einen Abschließenden Kommentar noch zu Java. Mit der Version 12 wurden weitere Möglichkeiten für das
switch/case Statement eingeführt. Hier wurde bspw. eine Schreibweise für den Verzicht auf
„break“ realisiert (indem man anstatt dem Doppelpunkt den „->“ Operator einträgt) und noch weitere Funktionalitäten eingebaut. Wie in allen
anderen Sprachen auch muss man immer damit rechnen, dass die Funktionalitäten mit neueren Versionen verändert bzw. erweitert werden. Insofern
ist ein Blick in die Onlinedokumentation immer ratsam, bzw. sollte man bei neuen Versionen der Sprachen sich kurz über die Neuerungen informieren.
Fuß/kopfgesteuerte Schleife
Die nächste wichtige Gruppe der Kontrollstrukturen sind die Wiederholungsschleifen. Wir haben in vorigen Listings auch schon Beispiele gesehen – aber auch
hier wollen wir uns möglichst strukturiert an das Thema annähern. Schleifen benötigen im Regelfall zwei Dinge. Eine Bedingung, welche darüber entscheidet,
ob wiederholt werden soll oder nicht und einen Bereich, der als Wiederholung ausgeführt werden soll. Man spricht hier von einer „Wiederholbedingung“ und
einem „Schleifenrumpf“. Hier gibt es zwei wesentliche Repräsentanten von Schleifen zu unterscheiden. Die kopf- und die fußgesteuerte Schleife. Sehen wir
uns beide Schleifen im Vergleich mal als PAP an:
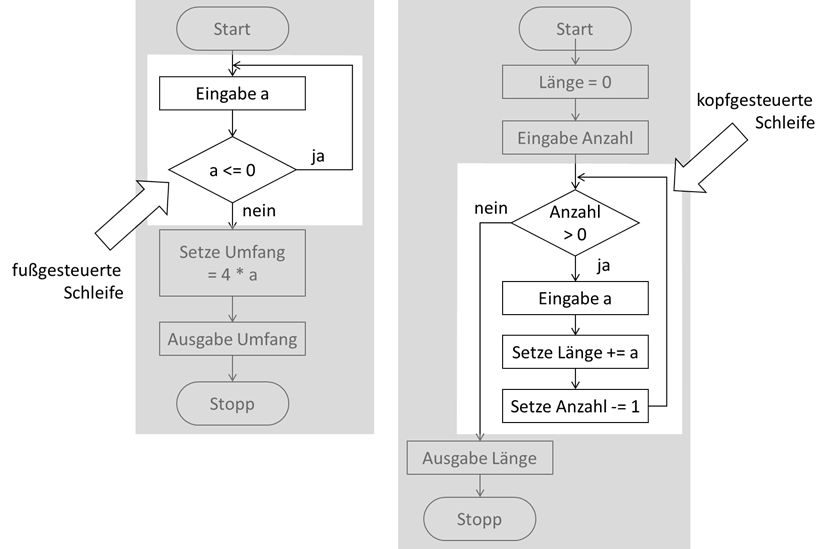
Abb.: 9: Kopf- vs. fußgesteuerte Schleife als PAP
Im linken Algorithmus wollen wir den User zwingen, Werte größer 0 einzugeben. Im rechten Algorithmus wollen wir dem User ermöglichen, eine Gesamtlänge
aus einzelnen eingegebenen Teillängen aufzusummieren, wobei er vorher die Anzahl der Teillängen eingeben muss.
Man sieht an den Beispielen auch, wo die Namen herkommen. Das „Steuerelement“ ist die Verzweigung. Bei der fußgesteuerten Schleife liegt sie unterhalb
des Verarbeitungsblocks und bei der kopfgesteuerten Schleife oberhalb. Dies bedeutet, dass bei der fußgesteuerten Schleife der Verarbeitungsblock mindestens
einmal durchlaufen wird. Bei der kopfgesteuerten kann es auch passieren, dass sie keinmal durchlaufen wird. Dies führt uns auch zu der Aussage,
wann welche der beiden Schleifen zu verwenden ist:
Die fußgesteuerte Schleife wird oft dann verwendet, wenn wir prüfen, ob die im Schleifenrumpf durchgeführte Aktion erfolgreich war oder nicht.
In unserem Fall wird mit der fußgesteuerten Schleife ein Errorhandling durchgeführt. Wenn der User etwas eingibt, was für die Umfangberechnung nicht
sinnvoll ist, wird die Eingabe wiederholt. Ich kann die Eingabe aber nur prüfen, wenn ich sie vorher auch sicher durchgeführt habe.
Die kopfgesteuerte Schleife wird oft dann verwendet, wenn wir prüfen, ob die im Schleifenrumpf durchzuführende Aktion überhaupt sinnvoll ist.
In unserem Fall wollen wir eine Gesamtlänge basierend auf Teillängen aufaddieren. Der User gibt an, wie viele Teillängen existieren. Sollte die Eingabe
0 oder gar kleiner 0 sein, so ist es nicht sinnvoll, irgendwelche Teillängen aufzuaddieren. Wenn aber eine Zahl > 0 eingegeben wird, dann wird pro
Teillänge eine Eingabe gemacht und danach die Anzahl um 1 reduziert, bis alle Teillängen eingegeben wurden.
Sehen wir uns die beiden in PAP formulierten Algorithmen erstmal als Kontrollstrukturen an:
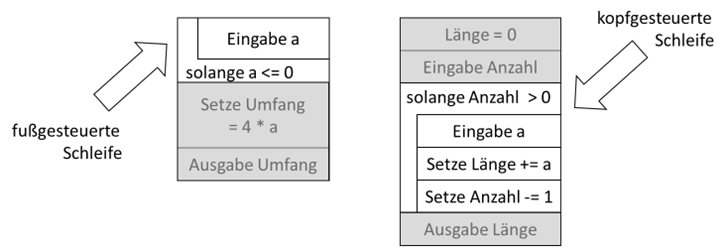
Abb.: 10: Kopf- vs. fußgesteuerte Schleife als Struktogramm
Bei den Schleifen sieht man die Kompaktheit des Struktogramms noch mehr als bei den Verzweigungen. Weiterhin erkennen wir, dass die eigentlichen
Schleifen als eine Einheit auszumachen sind – im Gegenteil zur PAP Notation, wo die Schleifen aus kleineren Elementen zusammensetzt werden
müssen(1). Gehen wir den Algorithmus mit einer kopfgesteuerten Schleife in einer C# Realisierung durch:
(1) Es gibt auch PAP „Sondersymbole“ für Schleifen, welche aber eher selten genutzt werden
Listing 21: Beispiel für break und continue in JavaScript
Kurze Erklärung der Codezeilen: Die Schleifenbedingung prüft, ob die Variable
i größer 0 ist. Da sie initial mit 10 belegt wird, verarbeitet der Interpreter den Schleifenrumpf. Gleich am Anfang wird mit
i-- der Wert von
i um 1 reduziert. Danach wird geprüft, ob
i modulo 2 gleich 1 ist – sprich ob die ganzzahlige Division mit 2 einen Restwert hat, was für alle ungeraden Zahlen gilt. Wenn
i also eine ungerade Zahl ist, wird
continue aufgerufen und die Schleife wird wieder von vorne verarbeitet. Ist
i gerade – bspw. im zweiten Durchlauf mit 8 – wird die nächste Prüfung auf
== 4 durchgeführt. Wenn
i == 4 ist, so wird die Schleife mit
break beendet. Wenn nicht, schreibt der Interpreter den Wert von
i auf die Konsole und die Schleife wird wiederholt. Im zweiten Durchlauf wird also
i == 8 sein, wodurch weder
continue noch
break greift. Im nächsten Durchlauf mit 7 greift wieder
continue. 6 wird wieder ausgegeben, 5 durch
continue übersprungen. Sobald
i == 4 ist, wird die Schleife mit
break beendet, weshalb die Bedingung in
while() nie greifen wird.
Wird der Code ausgeführt, sehen wir auf der Konsole die erwartete Ausgabe:
Manche Programmierer verzichten aufgrund der Nutzung von
break komplett auf die Bedingung in
while(), indem sie
while(true) schreiben und über eine
if Abfrage das
break aufrufen. Man kann durchaus Zweifel haben, ob dies der Übersichtlichkeit dient, wobei diese Entscheidung jeder selbst treffen muss – es sei
denn man ist Python Programmierer - aber davon später mehr. Wichtig ist auch das Verständnis des
break/continue Verhalten bei ineinander verschachtelten Schleifen. Sollten mehrere Schleifen ineinander verschachtelt sein, so wird mit
break die innere Schleife gestoppt. Lediglich Java bietet eine Möglichkeit mit „benannten“ Schleifen klar zu definieren, welche von mehreren
verschachtelten Schleifen unterbrochen werden soll. Es sei hier aber davor gewarnt, die Abbruch- bzw. Weiterlaufbedingungen von verschachtelten
Schleifen zu kompliziert zu machen. Eine saubere Abarbeitung jeder Schleife ist im Zweifelsfall einfacher nachvollziehbar als mehrere mögliche
Abbruchpunkte innerhalb der Schleifen.
In Struktogrammen kann man das
break übrigens einfach modellieren,
continue jedoch nur über Um-wege. Sehen wir uns das Struktogramm für den oben genannten Code an:
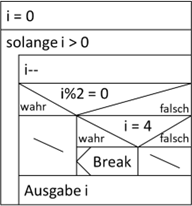
Abb.: 11: Break und Continue als Kontrollstruktur
continue muss also über eine Verzweigung mit leerem
„true“ Zweig bis zum Ende der Schleife umgesetzt werden. Das ist insofern nicht so schlimm, als dass
continue nicht sehr häufig benötigt wird. Hier nun nochmal die allgemeinen Regeln für die kopfgesteuerte Wiederholungsschleife
| Notation: | Beispiel: |
|---|---|
| Struktogramm: Die „Bedingung“ ist ein boolean Wert und bestimmt, ob die Wiederholung ausgeführt wird. Es ist oft sinnvoll, in der Bedingung noch das Wort „solange“ zu hinterlegen, also bspw. „solange a < 0“, um den Charakter der „Wiederholbedingung“ herauszustreichen. Der Aktionsbereich kann wieder aus beliebig verschachtelten Struktogrammelementen aufgebaut werden. |
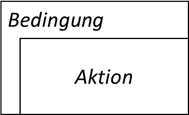 |
| Java, C#, C, C++, JavaScript, PHP: Der boolean Ausdruck, welcher den Eintritt in die Schleife steuert, befindet sich nach dem Schlüsselwort „while“ in runden Klammern. Wie bei der Verzweigung darf hier alles stehen, was am Ende einen „true“ oder „false“ Wert annimmt. |
 |
| Python: Durch das konsequente Einrücken für den Rumpf verzichtet Python wieder auf alle Klammern. |
 |
Tabelle 3: Gegenüberstellung Syntax kopfgesteuerte Wiederholungsschleife und Kontrollstruktur Element
Sehen wir uns nun die fußgesteuerte Schleife wieder in C# an:
Listing 22: Fußgesteuerte Schleife in C#
Kurze Erklärung der Codezeilen: Die Variable a wird zwar innerhalb des Schleifenrumpfes initialisiert, jedoch muss sie nach der Schleife weiterverarbeitet werden. Deshalb darf sie nicht innerhalb des
Schleifenrumpfes deklariert werden, da der Gültigkeitsbereich dieser Variablen in diesem Fall auf den Schleifenrumpf begrenzt wäre. Also beginnt der Code mit der Deklaration von a vor der Schleife.
Die fußgesteuerte Schleife wird mit
do eingeleitet, gefolgt vom Schleifernrumpf. Die Wiederholbedingung ist sinnvollerweise unterhalb des Rumpfes und benötigt wieder das Schlüsselwort
while, gefolgt vom
boolean Ausdruck für die Wiederholbedingung. Da die fußgesteuerte Schleife nicht wie die kopfgesteuerte mit einer geschweiften Klammer beendet wird, wird hier ein Semikolon für den Abschluss des Befehls benötigt.
Der Syntax einer fußgesteuerten Schleife ist wieder bei den üblichen Verdächtigen, C, C++, C#, Java, JavaScript und PHP identisch – Python wartet jedoch mit einer überraschenden Ausnahme auf: Python kennt
keine fußgesteuerte Schleife! Wir müssen in Python die fußgesteuerte Schleife nun tatsächlich mit Hilfe einer
while True: Schleife und einem
break Aufruf modellieren:
Listing 23: Modellierung fußgesteuerte Schleife mit kopfgesteuerter Schleife in Python
Kurze Erklärung der Codezeilen: In Python muss der
„True“ Wert großgeschrieben werden. Die
while Schleife läuft laut Wiederholbedingung „unendlich“. Die Prüfung auf Abbruch erfolgt erst am Schluss, wodurch sie zur fußgesteuerten Schleife wird.
Man sieht hier, dass das Konzept, auf die geschweiften Klammern zu verzichten, nicht immer zur Übersicht beiträgt. Es ist relativ schwer zu erkennen, dass die Verzweigung – welche ja auch wieder
eine Einrückung für den Rumpf benötigt – am Ende der Einrückung für die Schleife liegt. Trotzdem ist bei Python vom Schreibaufwand her am wenigsten zu tun.
| Notation: | Beispiel: |
|---|---|
| Struktogramm: Die „Bedingung“ ist ein ist auch hier ein boolean Wert und bestimmt, ob die Wiederholung ausgeführt wird. Wie bei der kopfgesteuerten Schleife ist es auch hier sinnvoll, in der Bedingung das Wort „solange“ zu hinterlegen. |
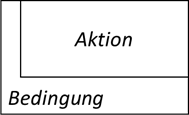 |
| Java, C#, C, C++, JavaScript, PHP: Eingeleitet wird die Schleife mit „do“. Der boolean Ausdruck, welcher die Wiederholung der Schleife steuert, befindet sich wieder nach dem Schlüsselwort „while“ in runden Klammern. Auch hier darf alles stehen, was am Ende einen „true“ oder „false“ Wert annimmt. |
 |
| Python: Python kennt keinen eigenen Syntax für fußgesteuerte Schleifen. |
Tabelle 4: Gegenüberstellung Syntax fußgesteuerte Wiederholungsschleife und Kontrollstruktur Element
Jetzt gilt es noch, eine wichtige Sache zu beachten. Die Verarbeitung im Schleifenrumpf sollte im Regelfall dazu führen, dass die Schleife auch wirklich zu einem Ende kommt – die Schleife muss „terminieren“.
Wenn wir im Rumpf also keine Veränderung von den in der Bedingung verarbeiteten Informationen vornehmen, so haben wir eine „Endlosschleife“ programmiert. Also wenn wir beispielsweise in der Bedingung eine Variable
a auf
< 0 prüfen, diese aber innerhalb der Schleife nicht verändern, kann die Schleife nicht beendet werden. Nun gibt es Situationen, wo man genau so etwas haben möchte. Bei Microcontrollern findet man mitunter eine
Schleife, bei der in der Wiederholungsbedingung
„true“ steht – also eine bewusste Programmierung einer Endlosschleife, ohne wie in
Listing 23 ein
break einzubauen. Microcontroller sind jedoch im Regelfall nur für eine einzige Aufgabe im Einsatz – sagen wir einen Messwert abzugreifen und diesen regelmäßig per WLAN an einen Empfänger zu senden. Da der
Microcontroller das ohne Unterbrechung und immer machen soll, würde man hier eine Endlosschleife wollen. Im „nicht Microcontroller“ Bereich gibt es aber auch Ausnahmen von der Forderung, dass der Schleifenrumpf
die Bedingungsvariablen beeinflussen sollte. Die eine ist, wenn wir wie oben mit einem
„break“ die Schleife unterbrechen. Die andere Situation wäre, wenn wir nicht nur mit einem Thread (also „singlethreaded“), sondern mit mehreren Threads (also „multithreaded“) arbeiten. Dann kann es vorkommen,
dass ein Thread eine Schleife eines anderen Threads unterbricht. Da wir das Thema „Multithreading“ später noch aufnehmen werden, verschiebe ich dieses Teilthema auf das entsprechende Kapitel.
Neben den oben beschriebenen klassischen Wiederholschleifen mit dem Schlüsselwort
„while“, gibt es noch Programmiersprachen, welche
„until“ erlauben (bspw. Visual Basic). Hier dreht sich einfach die Bedingung um. Während wir bei
„while“ eine positive Wiederholbedingung haben (also „wiederhole, solange die Bedingung wahr ist“), finden wir bei
„until“ eine positive Abbruchbedingung (also „breche ab, wenn die Bedingung wahr ist“). Durch eine Negation der
while Bedingung können wir aber problemlos aus einer Wiederholbedingung eine Abbruchbedingung erstellen. Die Syntaxregeln für die Negation – und weiteren Operatoren – werden wir im Anschluss an dieses Kapitel klären.
Zählschleife
Während die kopf- und fußgesteuerten Schleifen dann eingesetzt werden, wenn wir nicht vorab wissen, wie oft sie durchlaufen werden sollen, nutzt man die Zählschleifen genau dann, wenn wir dies wissen. Eine Zählschleife
benötigt hierfür im Regelfall vier Dinge:
- Eine Variable, in welcher der Zählstand abgelegt wird – die „Zählvariable“, meist „i“ wegen Integer genannt.
- Einen Wert, mit dem der Zähler beginnt – also der Initialisierungswert der Zählvariable.
- Einen Wert, bis zu dem der Zähler zählen soll – bzw. meist bis zu dem der Zähler gerade nicht mehr zählen soll.
- Die Wertanpassung – also um welchen Wert soll die Zählvariable pro Durchlauf verändert werden.
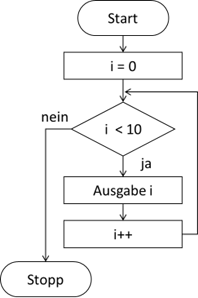
Abb.: 12: Zähler in PAP
Die PAP Repräsentation ist jetzt zugegebenermaßen wieder relativ „umständlich“, zeigt uns aber recht schön die innere Abarbeitung jeder Zählschleife. Zuerst wird die Variable deklariert und initialisiert.
Danach erfolgt die Prüfung, ob die Schleife durchlaufen werden soll – wir sprechen also von einer kopfgesteuerten Schleife. Im positiven Fall wird der Rumpf verarbeitet. Das letzte, was im Rumpf durchgeführt
wird, ist die Wertanpassung. In unserem Fall die Erhöhung um 1. Danach fängt die Schleife von neuem an, die Prüfung erfolgt wieder. Wenn wir jetzt „naiv“ an die Sache herangehen, könnten wir das Struktogrammelement
für eine kopfgesteuerte Schleife für eine Zählschleife verwenden:
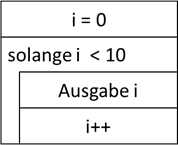
Abb.: 13: Zählschleife aus kopfgesteuerter Schleife aufgebaut
Eigentlich würde man also kein eigenes Symbol für eine Zählschleife benötigen. Allerdings gibt es bei der Umsetzung dieses Ansatzes im Code ein zwar kleines, aber unschönes Problem. Die Variable „i“ muss außerhalb der Schleife
deklariert werden. Dies bedeutet, dass der Speicherplatz für diese Variable nach der eigentlichen Nutzung im Kontext der Schleife nicht freigegeben wird. Es gibt aber keine Möglichkeit, die Variable innerhalb der Schleife zu deklarieren,
da sie nach jedem Wiederholungslauf neu deklariert werden würde. Würden wir bspw. nach der Wiederholbedingung und oberhalb „Ausgabe i“ die Variable deklarieren (und somit zwingend auch initialisieren), würde die Zählinformation vom
letzten Durchlauf verloren gehen. Also hat man sich entschlossen, ein eigenes Codekonstrukt für Zählschleifen zu definieren, in dem die Deklaration als Teil der Schleife möglich ist, ohne in jedem Durchlauf die Deklaration durchzuführen.
Da diese Schleifen sehr häufig verwendet werden, kann man sie auch als Struktogrammelement finden:
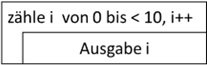
Abb.: 14: Zählschleife als Struktogramm
Dieses Struktogrammelement wird mitunter auch „Iteration“ genannt. Man erkennt an diesem Symbol die wichtigsten Eigenschaften einer Zählschleife. Erstmal, dass i nur innerhalb der Schleifenstruktur vorkommt, da es im Schleifenkopf
definiert und initialisiert wird. Dann sehen wir noch den Endwert 10 – wobei es zwar nicht zwingend gefordert, aber sinnvoll ist mit einem „<“ Zeichen klarzumachen, dass 10 nicht mehr erreicht wird. Die Schrittweite kann entweder
durch einen Operator (hier ++ für „Erhöhung um jeweils 1“) oder einem Klartext wie „erhöhe um 1“ festgelegt werden. Gerade wenn die Schrittweite nicht 1 ist, muss dies verständlich hinterlegt sein. Weiterhin erkennen wir, dass es
sich bei der Zählschleife um eine kopfgesteuerte Schleife handelt. Das haben wir ja bereits im PAP so festgelegt. Warum dies sinnvoll ist, können wir an folgendem Beispiel sehen:
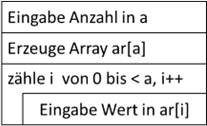
Abb.: 15: Schleife für Arrayauswertung
Wir geben also die Anzahl der gewünschten Arrayeinträge ein. Danach wird das Array erzeugt und Schritt für Schritt mit Werten belegt. Wenn wir aber aus irgendeinem Grund keinen einzigen Wert im Array benötigen, so würden wir ein
Array der Länge 0 erzeugen – was durchaus möglich ist. Wenn wir jetzt aber eine fußgesteuerte Schleife hätten, würden wir ja mindestens einmal durch die Schleife laufen müssen. Das würde bei einem Array der Länge 0 aber zu einem
„IndexOutOfBounds“ Fehler führen. Wir müssen bei einer Zählschleife also immer die Möglichkeit offen haben, sie gar nicht zu durchlaufen, was nur bei der kopfgesteuerten, nicht aber bei der fußgesteuerten Struktur möglich ist.
Sehen wir uns ein C# Beispiel für den Algorithmus der Abbildung 15 an:
Listing 24: Arraybelegung mit Zählschleife in C#
Kurze Erklärung der Codezeilen: Die Belegung von
a als Zahl aus einer Usereingabe ist an dieser Stelle nichts Neues. „neu“ ist allerdings die dynamische Erzeugung eines leeren Arrays basierend auf einer Usereingabe. Bis jetzt waren in der eckigen Klammern der Arrayerzeugung immer
konstante Zahlen. Wie wir sehen, sind aber auch Variableninhalte möglich. Wichtig ist hier allerdings, dass in einem sauberen Programm vorher abgefangen werden muss, dass der User bspw. keine negativen Zahlen eingibt. Da der Code hier
allerdings nur zu Demonstrationszwecken genutzt wird, habe ich auf das Errorhandling verzichtet. Die eigentliche Zählschleife deckt sich im Wesentlichen mit der Kontrollstrukturdarstellung. Das einleitende Schlüsselwort ist bei fast
allen Programmiersprachen
„for“, weshalb man die Zählschleife oft auch „for-Schleife“ nennt. Innerhalb des runden Klammernpaares erfolgt die Deklaration, Initialisierung, Weiterlaufbedingung und Wertanpassung.
Und genau an dieser Stelle sollten wir nochmal einen Blick auf den PAP aus
Abb.: 12 werfen. Wir sehen hier, wann was erledigt wird – und das gilt 1:1 so auch für die for-Schleife. Zuerst wird deklariert und initialisiert. Danach wird geprüft, ob die Wiederholbedingung
erfüllt wird. Schließlich wird der Rumpf ausgeführt und am Schluss erst erfolgt die Wertanpassung. Obwohl in der Notation also die Wertanpassung oben steht, wird sie unten durchgeführt. Im ersten Durchlauf finden wir in der Variablen
i also die 0. Im Steuerbereich in den runden Klammern finden wir dann die drei Blöcke, welche im PAP auch für die Steuerung verantwortlich sind:
- Deklaration und Initialisierung, bspw.: int i = 0
- Wiederholungsprüfung, bspw.: i < 10
- Wertanpassung, bspw.: i++
Diese drei Codeelemente sind per Semikolon voneinander getrennt. Streng genommen können wir die Zählschleife auch so programmieren, dass der erste und dritte Bereich leer gelassen wird und die Schleife so umsetzen, als wäre sie eine
kopfgesteuerte Wiederholungsschleife:
Listing 25: Zählschleife mit leeren Steuerbereichen
Das ist jetzt zwar eher „sinnlos“, eine Zählschleife als
„while“ Schleife zu nutzen, um wiederum eine Zählschleife zu programmieren – es zeigt aber, dass im inneren einer Zählschleife eigentlich eine
while – Schleife mit Zusatzoptionen steckt und es zeigt, dass wir im Zweifelsfall die Zählvariable auch außerhalb deklarieren können, wenn es denn unbedingt erforderlich ist.
Der Syntax von C# deckt sich wieder mit den Syntaxregeln von C, C++, Java, JavaScript und PHP. Python ist wie immer die Ausnahme, weshalb ich später gesondert darauf eingehen werde. Wenn wir das
Listing 24 nochmal ansehen, gibt es ein Detail, was in anderen Situationen Probleme bereiten würde. In diesem Listing wissen wir vorab, wie groß das Array ist, da wir die Länge ja in der Variablen
a abgelegt haben. Wenn wir dies aber nicht wissen – bzw. keine Variable mit der Arraylänge haben, so müssen wir die Arraygröße in der Bedingung bestimmen. Es ist grundsätzlich sinnvoll, immer innerhalb der Wiederholbedingung die Größe direkt
zu bestimmen, da streng genommen der Wert der Variablen
a nicht konstant ist und geändert werden kann. Dies ist zwar nur bei multithreaded Applikationen ein Problem, aber man sollte sich die Prüfung innerhalb der Schleife angewöhnen – zumindest in den kompilierten
Programmiersprachen(2) - immer direkt die Länge abzufragen (wie bspw.
ar.Legnth() in C#):
(2) In interpretierten Sprachen kann es bei sehr großen Arrays zu Performanceeinbußen kommen. Hier muss man treadsafety und Performance gegeneinander abwägen.
Listing 26: Arraybelegung mit Zählschleife in C# mit dynamischer Längenermittlung
Die Längenbestimmung ist allerdings in den verschiedenen Programmiersprachen unterschiedlich. Hier ein Beispiel eines
int Arrays
iArr:
| Sprache: | Methodik: |
|---|---|
| C | sizeof(iArr)/sizeof(iArr[0]) bzw. sizeof(iArr)/sizeof(int) |
| C++ | sizeof(iArr)/sizeof(iArr[0]) bzw. sizeof(iArr)/sizeof(int) |
| C# | iArr.Length |
| Java | iArr.length |
| JavaScript | iArr.length |
| PHP | sizeof($iArr) |
| Python | len(iArr) |
Tabelle 5: Ermittlung von Arraygrößen
Bei zwei Methoden müssen wir aber noch etwas tiefer eingehen. In Python ist der Standardweg angegeben. Allerdings gibt es in Python eine sehr oft genutzte Bibliothek für mathematische Operationen – vor
allem für den Bereich der neuronalen Netze bzw. Künstlicher Intelligenz („KI“), nämlich „numpy“. Hier wird die Anzahl der Arrayeinträge über
iArr.size ermittelt – wobei für zweidimensionale Arrays hier wirklich „Anzahl“ gemeint ist (sprich bei einem zweidimensionalen Array der Größe 2x4 erhalten wir 8). Die Information 2 und 4 würden wir über
iArr.shape erhalten, was wiederum ein Array mit den Einträgen 2 und 4 zurückgibt. Der zweite zu erwähnende Punkt bei
Tabelle 5 ist C (bzw. C++). Hier muss die Arraygröße über
„sizeof()“ ermittelt werden. Da
sizeof() aber „nur“ den Speicherbedarf zurückgibt, müssen wir somit in solchen Fällen den Speicherbedarf des Gesamtarrays durch den Speicherbedarf eines einzelnen Eintrages dividieren. Da wir diesen im
Zweifelsfall zum Zeitpunkt des Kompilierens nicht wissen, müssen wir den Speicherbedarf des ersten Eintrages auf Indexposition 0 ermitteln. Dadurch laufen wir aber bei einer möglichen Arraygröße 0 wieder in einen
IndexOutOfBound Fehler. Dieses Problem haben wir bei den objektorientierten Ansätzen von C#, Java bzw. JavaScript nicht.
In den bisherigen Listings haben wir schreibend auf Arrays zugegriffen. Für das Auslesen gibt es wiederum zwei Möglichkeiten. Für die erste können wir den klassischen Weg über die Zählschleife gehen, indem wir den
Zähler über alle Indexmöglichkeiten des Arrays laufen lassen und über
ar[i] auf die einzelnen Werte zugreifen. Sehen wir uns den Code an, welcher das Array aus
Listing 26 ausgeben würde:
Listing 27: Array mittels Zählschleife auslesen in C#
Nun gibt es, gerade für das Auslesen eines Arrays, noch eine zusätzliche Schleifenart, die
„for each“ Schleife. Der Gedanke hier ist, dass man häufiger auf alle Elemente eines Arrays sequenziell zugreifen möchte und dies möglichst kurz und prägnant programmieren möchte:
Listing 28: Array mittels foreach auslesen in C#
Kurze Erklärung der Codezeilen: Im Array ar befinden sich laut Deklaration aus
Listing 26 Strings. Die Schleife deklariert nun eine Stringvariable
s, in der bei jedem Durchlauf die einzelnen Werte des Arrays hineinkopiert werden. Diese Variable nennen wir auch „Iterationsvariable“, da die Werte des Arrays in jeder Iteration dort hineinkopiert werden.
Hier müssen wir wieder mal über den Begriff „hineinkopieren“ sprechen. In C# werden hier die Inhalte der Variablen kopiert – ähnlich wie bei einem Funktionsaufruf. Das bedeutet, dass einfache Datentypen eine Kopie des Wertes erhalten und
zusammengesetzte Datentypen eine Kopie der Referenz. Sehen wir uns das wieder mit einem einfachen Beispiel an. Wir erzeugen zuerst ein int Array – also ein Array mit einfachen Datentypen, untersuchen es und machen dann das gleiche mit einem
Array von Objekten – also einem Array von zusammengesetzten Datentypen. Dort untersuchen wir das Verhalten wieder auf gleiche Weise. Im Prinzip ist es die gleiche Vorgehensweise wie in
Kapitel 8 bei der Untersuchung auf „call by value“ vs. „call by reference“. Da C keine
foreach Schleife kennt, beginnen wir diesmal mit C++:
Listing 29: Untersuchung des Übergabeverhaltens von foreach Schleifen in C++
Kurze Erklärung der Codezeilen: In C++ ist der Syntax für die „foreach“ Schleife etwas anders. Sie wird mit
„for“ wie eine Zählschleife eingeleitet. Danach wird in den runden Klammern lediglich ein Ausdruck hinterlegt, wobei die Iterationsvariable vor dem Doppelpunkt deklariert wird und nach dem Doppelpunkt die Variable steht,
in der die Datensammlung – in unserem Fall das Array – festgelegt wird. Was wir nun machen ist, die Iterationsvariable
i jeweils um eins erhöhen. Danach wird eine weitere Schleife erzeugt, in der wir alle Werte zur Kontrolle ausgeben.
Wenn wir das Programm laufen lassen, sehen wir:
Dies bedeutet also, dass
i jeweils eine Kopie des Wertes je Arrayeintrag erhalten hat, da die Erhöhung nicht im Array gelandet ist. Da wir in C++ auch mit Adressen von einfachen Datentypen arbeiten, müssen wir nicht den Umweg über Objekte gehen, wie in Java oder C#.
Insofern modifizieren wir unser Listing nur minimal, so dass wir die Adressen übergeben:
Listing 30: Untersuchung des Übergabeverhaltens von foreach Schleifen in C++ mit Adressübergabe
Kurze Erklärung der Codezeilen: Die einzige Änderung unseres Codes besteht jetzt im
& vor dem
i in der Deklaration der ersten Schleife. Dadurch veranlassen wir C++ nicht eine Kopie des Arrays zu verarbeiten, sondern mit Adressen des Arrays zu arbeiten – wir haben also einen „call by reference“ erzwungen.
Wenn wir das Programm laufen lassen, sehen wir:
Die in der ersten Schleife angepassten Werte finden wir also beim späteren Auslesen des Arrays wieder – alle Werte sind um 1 größer geworden.
Da PHP die gleiche Verhaltensweise an den Tag legt, hier gleich das vergleichbare Listing in PHP:
Listing 31: Untersuchung des Übergabeverhaltens von foreach Schleifen in PHP mit Adressübergabe
Kurze Erklärung der Codezeilen: Wie in C++ erzwingen wir die Adressübergabe mit dem
& Zeichen. Der Syntax in PHP ist jetzt wieder etwas anders – man schreibt in die Klammer nach
foreach zuerst die Liste, gefolgt von
as und dann kommt die Iterationsvariable, welche pro Iteration die Werte erhält.
Die Ausgabe ist wie in C++ 2, 3 und 4. Wenn wir das
& herausnehmen, würden wir wieder 1, 2 und 3 erhalten. C++ und PHP sind jedoch die einzigen hier besprochenen Sprachen, bei denen man die Werte bei Arrays von primitiven Datentypen ändern kann,
da wir nur hier einen Zugriff auf die Adressen von diesen Variablentypen haben. Sehen wir uns das Ganze am Beispiel von Java an:
Listing 32: Untersuchung des Übergabeverhaltens von foreach Schleifen in Java bei Arrays von int
Der Java Code ist vergleichbar mit dem C++ Code für den „call by value“ Zugriff, insofern nichts Neues und es überrascht auch das Ausgabeverhalten nicht, da Java erwartungsgemäß
„call by value“ bei der Übergabe der Arraywerte in
i umsetzt.
Da Java kein explizites „call by reference” unterstützt, gibt es für Java auch keine Möglichkeit bei einer foreach Schleife schreibend auf die einzelnen Datenwerte eines Arrays von
primitiven Datentypen zuzugreifen. Wenn dies notwendig ist, müssen wir hier immer über eine normale for-Schleife gehen. Wie sieht es dann bei Zugriffen auf ein Array von zusammengesetzten
Datentypen aus? Hier greifen wir wieder auf ein Array von Arrays zurück:
Listing 33: Untersuchung des Übergabeverhaltens von foreach Schleifen in Java bei Arrays von Objekten (hier Arrays)
Wie bei den Funktionsaufrufen auch, behandelt Java bei der
foreach Schleife den Wert einer Objektvariablen als Referenz auf das eigentliche Objekt. Das heißt, in
i kopiert Java die Referenz auf das entsprechende Array, auf das wir dann mit
i[0]++ zugreifen. Dadurch wird das eigentliche Objekt verändert und wir erhalten somit als Ausgabe:
Dies ist im Prinzip das gleiche Verhalten wie bei den Funktionsaufrufen. Bei C# gibt es wiederum eine Überraschung, wenn wir den schreibenden Zugriff auf die Iterationsvariablen
i versuchen:
Listing 34: Untersuchung des Übergabeverhaltens von foreach Schleifen in C# bei Arrays von int
C# akzeptiert diesen Code nicht mit dem Hinweis: „i ist "foreach-Iterationsvariable". Eine Zuweisung ist daher nicht möglich.“. Es ist also nicht vorgesehen eine Iterationsvariable
schreibend zu verändern. Sehen wir uns das bei einem Array von Arrays an – hier würden wir ja die Iterationsvariable ja nicht verändern, sondern das Objekt (also das Array), auf das die Iterationsvariable zeigt:
Listing 35: Untersuchung des Übergabeverhaltens von foreach Schleifen in C# bei Arrays von Objekten (hier Arrays)
Kurze Erklärung der Codezeilen: Da C# es nicht erlaubt, Arrays von Arrays mit einer vordefinierten Menge zu initialisieren, müssen wir hier wieder zuerst das äußere Array erzeugen und dann Schritt für Schritt die
Einträge mit den inneren Arrays füllen. Hier habe ich eine Kurzschreibweise für die Zuweisung gewählt, welche ein neues Array mit je zwei Zahlenwerten erzeugt und gleich dem äußeren Array zuweist (also bspw.
ar[0] = new int[] {1, 1};). Der Zugriff erfolgt wieder wie im Listing 33.
Der Code kompiliert und gibt bei Ausführung das gleiche wie der Java Code aus:
JavaScript und Python verhalten sich bezüglich des Übergabeverhaltens nun genauso wie Java, da die innere Mechanik der Referenzübergabe dort ähnlich gelöst ist. Da die Syntaxvariante von JavaScript sich aber erheblich von
Java unterscheidet, gehen wir hier kurz auf die Besonderheiten von foreach Schleifen in JavaScript ein:
Listing 36: Untersuchung des Übergabeverhaltens von foreach Schleifen in JavaScript bei Arrays von int
Kurze Erklärung der Codezeilen: In JavaScript ist die
foreach Schleife vergleichsweise kompliziert gelöst. Es fängt schon damit an, dass
foreach innerhalb des Array-Objektes implementiert wurde und kein eigenständiges Element ist. Weiterhin akzeptiert das
foreach keine Deklaration einer Iterationsvariable wie bspw. Java oder C#. Wir müssen hier für die Verarbeitung jedes einzelnen Elements des Arrays ein Unterprogramm aufrufen, welches wir extra für die
Verarbeitung erstellen müssen. Dieses Konzept entstammt dem funktionalen Programmierparadigma. Jedes Element wird auf die angegebene Funktion angewendet – sprich die Funktion erhält als Parameter den aktuellen
Arraywert. Für die Erhöhung der Werte habe ich
addValue(i) definiert und für die Ausgabe die
printValue(i). Die Parametervariable
„i“ übernimmt hier die Funktion der Iterationsvariablen. Da diese Unterprogramme per Definition nur diesen einen Parameter haben dürfen, wird beim Aufruf durch foreach auch kein Parameter benötigt – JavaScript „weiß“,
dass bei diesem Aufruf in dem Unterprogramm ein einziger Parameter sein muss und dieser wird pro Iteration mit den einzelnen Werten belegt.
Da wir hier wieder mit primitiven Datentypen arbeiten, ist die Ausgabe erwartungsgemäß 1, 2 und 3. Der Vollständigkeit halber füge ich hier noch den Ansatz für Arrays von Arrays hinzu:
Listing 37: Untersuchung des Übergabeverhaltens von foreach Schleifen in JavaScript bei Arrays von Objekten (hier Arrays)
Wie Java auch, liefert uns dieses Programm 2, 3 und 4. In einem späteren Kapitel werden wir uns noch mit dem Thema „Lambda-Ausdrücken“ beschäftigen, welche das Konstrukt aus Listing 37
etwas kompakter realisiert:
Da wir später auf die anonymen Funktionen und Lambdaausdrücke noch eingehen werden, verzichte ich hier auf eine detailliertere Erklärung. Wichtig ist lediglich, dass der Code aus den
vorausgegangenen beiden Listings identisch funktioniert.
Nun fehlt uns bei den „for-Schleifen“ noch Python. Hier wird vor allem bei der Zählschleife ein etwas anderer Weg gegangen als bei den bisherigen Sprachen. Python kennt keine einfache Zählschleife mehr,
sondern nutzt stattdessen den foreach Ansatz. Sehen wir uns das an einem einfachen Beispiel an:
Listing 39: Zählschleife simuliert mit Array
Wenn wir den Zähler durch ein Array „simulieren“, würden wir also das Verhalten einer Zählschleife erhalten. Da es jetzt natürlich viel zu umständlich ist, alle Werte immer in ein Array zu packen,
gibt es in Python die Funktion
„range()“, welche uns einen Zahlenbereich liefert. Probieren wir das Ganze nun mit Range:
Listing 40: Zählschleife in Python mit range
Die Ausgaben der beiden Programme sind identisch. Wir müssen also
„range“ verstehen, damit wir alle Möglichkeiten von Zählschleifen realisieren können. Hier die wichtigsten Varianten für Zählvorgaben:
| Zählvorgabe: | Syntax: | Ausgabe: |
|---|---|---|
| Zähler von 0 bis 9 | range(10) | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 |
| Zähler von 10 bis 15 | range(10, 15) | 10, 11, 12, 13, 14, 15 |
| Zähler von 0 bis 10 in Zweierschritten | range(0, 11, 2) | 0, 2, 4, 6, 8, 10 |
| Rückwärtstzähler von 10 bis 5 | range(10, 4, -1) | 10, 9, 8, 7, 6, 5 |
Tabelle 6: Verhalten von "range" in Python
Fehlt also nur noch eine Untersuchung des Verhaltens der foreach Übergabe. Beginnen wir mit der Übergabe von primitiven Datentypen:
Listing 41: Untersuchung des Übergabeverhaltens von foreach Schleifen in Python bei Arrays von int
Die Ausgabe ist für diesen Fall wie in Java bzw. JavaScript 1, 2 und 3 – also „call by value“ Verhalten. Bei Übergaben von Referenzen auf zusammengesetzte Datentypen gibt es auch keine weiteren Überraschungen:
Listing 42: Untersuchung des Übergabeverhaltens von foreach Schleifen in Python bei Arrays von Objekten (hier Arrays)
Wie bei JavaScript und Java ist hier auch 2, 3 und 4 zu beobachten, die Änderungen bleiben also erhalten, Python übergibt die Referenzen auf das Array in die Iterationsvariable
i.
| Notation: | Beispiel: |
|---|---|
| Struktogramm: Die Zählschleife benötigt eine Zählvariable „i“, einen Startwert „a“ und einen Endwert „b“, wobei im Regelfall dieser gerade nicht mehr erreicht wird. Dies kann mit einem Kleinerzeichen verdeutlich werden. Die Schrittweite c wird entweder mit dem Wort „Schrittweite“ angegeben, oder über einen Operator wie ++ für „Erhöhung um 1“, -- für „Verringerung um 1“ oder += c bzw. -= c für Erhöhung/Verringerung um einen Wert c. |
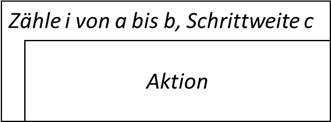 |
| Zählschleife in Java, C#, C, C++, JavaScript, PHP: Eingeleitet wird die Schleife mit „for“. In Klammern wird die Zählvariable deklariert und initialisiert, die Wiederholbedingung formuliert und am Ende die Wertanpassung. Bis auf die Wiederholbedingung, können syntaktisch die drei durch Semikolon getrennten Elemente leer bleiben. |
 |
| Python: Python realisiert die Zählschleife über eine foreach Schleife (auch wenn das Schlüsselwort „nur“ for ist). Die range Funktion liefert uns die möglichen Iterationswerte. |
 |
| Für foreach Schleifen gibt es kein eigenes Strukto-grammsymbol. In den folgenden Codebeispielen wird ein Array ar in die Iterationsvariable i eingelesen. | |
| Foreach Schleife in Java, und C++: Der Typ von i muss zu den Datentypen des Arrays passen – also bspw. int[] ar benötigt int i. In C++ kann i als Adresse angegeben werden, was durch ein & vor dem i erreicht wird, also bspw. for (int &i : ar). Dadurch wird ein „call by reference“ Verhalten erzwungen. |
 |
| Foreach Schleife in C#: Hier darf auf i nicht schreibend zugegriffen werden, sofern es sich um einen primitiven Datentyp handelt – was ohnehin nicht sinnvoll wäre. |
 |
| Foreach Schleife in PHP: Wie in C++ kann durch ein & vor dem $i ein „call by reference“ Verhalten erzwungen werden, auch wenn es sich um einen primitiven Datentyp handelt. |
 |
| Foreach Schleife in JavaScript: JavaScript hat die foreach Funktionalität als Methode des Array Objektes implementiert und erwartet einen Handler (bzw. „Callback), der den Rumpf der foreach Schleife darstellt. Dieser muss dann in der Implementierung einen Parameter (die Iterationsvariable) enthalten. Oft wird der Handler über eine Lambdafunktion realisiert. |
 |
| Foreach Schleife in Python: Python verzichtet wieder auf sämtliche Klammern und verhält sich ansonsten wie Java. |
 |
| Foreach Schleife in C: C kennt nativ keine foreach Schleife. |
Tabelle 7: Gegenüberstellung Syntax Zählschleife und Kontrollstruktur Element
Aufruf
Damit haben wir die wichtigsten Kontrollstrukturen abgehakt. Wenn man es genau nimmt, ist auch der Aufruf eines Unterprogramms eine Kontrollstruktur, da wir hiermit die Abarbeitungssequenz unterschiedlicher Befehlselemente definieren.
Die Aufrufe haben wir bereits in Kapitel 8 kennengelernt. Was uns lediglich noch fehlt ist das zugehörige Struktogrammsymbol:

Abb.: 16: Aufruf als Struktogrammsymbol

CC Lizenz (BY NC SA)