
Skriptsprachen – wenn Typen (scheinbar) unwichtig werden
Wir haben uns bis jetzt mit den wichtigsten kompilierten Programmiersprachen C, C++, C# und Java auseinandergesetzt und die
Skriptsprachen erstmal links liegen gelassen. Der Grund hierfür ist, dass wir uns um die innere Verarbeitung gekümmert haben,
was uns oft zu Speicherfragen geführt hat. Die meisten Skriptsprachen werden aber oft als „nicht typisiert“ bezeichnet, was
aussagen soll, dass sie aus Sicht des Programmierers vordergründig keine Datentypen kennen. Dies ist vorerst mal überraschend
(und eigentlich auch falsch), da am Ende des Tages der Rechner die Daten ja irgendwie im Speicher ablegen muss und dort
entscheiden muss, wie viel Platz für die Variablen benötigt werden. In Wirklichkeit kennen die Skriptsprachen sehr wohl
Datentypen, sie verbergen sie nur vor dem Programmierer. Insofern sollte man richtigerweise von „dynamischer Typisierung“
sprechen – die Typprüfung und Typfestlegung wird also nicht beim Kompilieren, sondern bei der Ausführung durchgeführt. Dies ist
für die Codeerstellung sehr praktisch und reduziert die Entwicklungszeit. Jedoch „zahlt“ man dies durch langsamere
Ausführungszeiten. Wenn wir mal davon ausgehen, dass wir keinen hoch performanten Code schreiben wollen, ist in den allermeisten
Fällen dieses „Verbergen“ der Datentypen auch sehr praktisch – in einigen wenigen Situationen jedoch ist es recht frustrierend,
da wir die interne Datenhaltung erahnen müssen, um für bestimmte Situationen Vorkehrungen für Fehlerbehandlungen vorzusehen.
Da wir aber jetzt durch die Erkenntnisse der kompilierten Programmiersprachen die internen Notwendigkeiten verstehen, können wir
diese Vorkehrungen auch besser umsetzen.

Die wichtigsten Skriptsprachen
Bevor ich in die wesentlichen Elemente von Skriptsprachen einsteige, noch ein paar allgemeine Worte vorweg. Da es sehr viele
unterschiedliche Skriptsprachen gibt, muss ich mich hier auf die wichtigsten konzentrieren. Die vermutlich am meisten genutzte
Skriptsprache ist JavaScript, gefolgt von PHP bzw. immer häufiger Python. Jede dieser drei Sprachen hat seinen primären
Anwendungsbereich.
JavaScript ist die defacto Skriptsprache für Web Frontends – sprich interaktive Webseiten. Jeder Browser kann JavaScript
interpretieren, was die extrem weite Verbreitung von JavaScript erklärt. Somit gibt es eine sehr breite Community an JavaScript
Entwicklern. Basierend auf diesem Erfolg hat man begonnen, mit node.js das
Backend – sprich, die Server – auch dazu zu bringen, JavaScript zu verstehen. Oftmals wird Typescript im gleichen Atemzug wie JavaScript
genannt, wobei TypeScript primär ein vermeintliches Manko von JavaScript adressieren soll – die fehlende Typisierung. Typescript wird
jedoch von einem Compiler einfach „nur“ zu JavaScript umgewandelt, welches dann am Ende ausgeführt wird. Dies birgt Vor- und Nachteile.
Vorteilhaft ist neben der Typisierung, dass man beim Compilevorgang die Zielversion von JavaScript einstellen kann und eine gewisse
Flexibilität bezüglich des Supports der Zielarchitekturen erreichen kann. Wenn bspw. die Software auf einem relativ alten Browser
laufen soll, stellt man den Compiler auf diese Version ein. Nachteilig ist, dass man einen weiteren Entwicklungsschritt berücksichtigen
muss. Eventuell wird man anstatt JavaScript auch ECMA Script
(European Computer Manufacturers Association)
oder kurz ES finden. Die ECMA versucht einen gemeinsamen Sprachkern zu definieren um zu verhindern, dass einzelne Browserhersteller
Funktionalitäten ins Leben rufen, welche von anderen wiederum nicht sauber interpretiert werden können, was dem offenen Gedanken des
Internets wiedersprechen würde. Ich werde mich hier auf verschiedene Konzepte von JavaScript konzentrieren, welche bis inklusive ES6
(also ECMA Script Version 6 – seit 2015) unterstützt werden.
PHP ist ebenfalls sehr verbreitet, da es eine sehr effektive Sprache für die serverseitige Programmierung von Webapplikationen ist –
und mit node.js, also JavaScript, eine mächtige Konkurrenz bekommen hat. PHP wurde explizit für den Anwendungsfall der serverseitigen
Webverarbeitung entwickelt. PHP ist zwar objektorientiert – die Ursprünge von PHP kommen nicht aus der Objektorientierung, welche erst
später hinzugefügt wurde. Dadurch finden wir in PHP oftmals nicht ganz stringent umgesetzte objektorientierte Ansätze.
Python steigt stetig in der Beliebtheit und ist mit dem Ziel entwickelt worden, möglichst sauberen und modernen Code zu forcieren, was
unter anderem die weite Verbreitung in Hochschulen erklärt. Python wurde auch in diversen Programmen für die Makroprogrammierung eingebaut,
bspw. Blender oder
OpenOffice. Derzeit ist Python für das maschinelle Lernen die
Programmiersprache der Wahl, da die wichtigsten Bibliotheken hierfür (Keras bzw. jetzt
TensorFlow) in Python geschrieben wurden – bzw. korrekterweise muss man sagen,
dass die Routinen in C/C++ geschrieben wurden und als Pythonmodul zur Verfügung stehen – sprich wir nutzen diese Bibliotheken in Python.
Dies ist auch einer der Stärken von Python – es ist relativ einfach möglich, eigene C/C++ Programme zu schreiben und sie innerhalb
Python zur Verfügung zu stellen(1), sprich wir können Python erweitern. Dies erklärt auch, warum Python
trotz der relativ schlechten Performance für so ressourcenintensive Themen wie KI (Künstliche Intelligenz) eingesetzt wird. Python
fungiert hier „nur“ als Rahmenwerk für den Aufruf externer Module. Ein weiterer Ort, an dem wir Python oft finden, ist der Raspberry PI
(bei dem „PI“ übrigens für Python Interpreter steht). Es ist relativ einfach im Raspberry PI die Systemressourcen und Funktionen mit
Hilfe von Python Skripten zu erreichen. Um vorab noch Unklarheiten bezüglich der Benamung auszuräumen. In den Onlinedokumentationen findet
man häufiger den Begriff „CPython“. Hierunter versteht man „die“ Pythonimplementierung – es ist also gleichbedeutend mit „Python“. Nun
hat man Python auch in anderen Programmiersrpachen realisiert – bspw. wurde Python in Java „nachgebaut“ – und man ahnt es bereits, dies
nennt man JPython. Die Referenzimplementierung wurde aber in C geschrieben, weshalb man standardmäßig immer von CPython ausgeht.
Fangen wir nun erstmal mit der guten Nachricht an. Genau wie bei den kompilierten Sprachen finden wir bei den Skriptsprachen viele
Konzepte wieder. Man muss nicht alles neu lernen. Die grundsätzlichen Konstrukte einer Programmiersprache finden wir in C, C++, C# und Java
genauso wie in JavaScript, PHP und Pyhton – nur eben mit Ausnahme der Typisierung. Insofern müssen wir uns lediglich mit kleineren
Detailfragen beschäftigen – wie werden Variablen deklariert und warum können beispielsweise Arrays dynamisch vergrößert werden und so weiter.
Da alle drei hier referenzierten Skriptsprachen objektorientiert genutzt werden können, werde ich die Detailfragen zu Objekten und Klassen
im Abschnitt zur Objektorientierung nachliefern. Weiterhin gilt es zu erwähnen, dass der fehlende Compiler die Arbeit als Programmierer
mit Skriptsrpachen an manchen Stellen eher erschwert als erleichtert. Wenn wir ohne einer speziell auf die relevante Skriptsprache angespasste
IDE arbeiten, dann werden Fehler oft erst zur Laufzeit bemerkt – was sehr unbefriedigend sein kann. Insofern wird empfohlen, auf jeden
Fall mit einer passenden IDE mit Code Highlightning(2) zu arbeiten, um zumindest strukturelle Syntaxfehler
bereits beim Schreiben der Software zu bemerken.
(2) Das automatische optische Hervorheben von unterschiedlichen Codefragmenten und Anzeigen möglicher Fehler
Beginnen wir mit dem Start der einzelnen Applikationen. Hier gilt es wieder den Anwendungsfall im Auge zu behalten. Wenn wir beispielsweise ein
PHP-Programm schreiben, dann wird es in aller Regel ein serverseitiges Skript zur Verarbeitung von http Anfragen sein. Dies bedeutet, dass
nicht wir das Programm direkt starten, sondern eine Webbrowser Anfrage dies für uns erledigt. Das heißt wiederum, dass wir einen Server benötigen,
der als Laufzeitumgebung für unser Skript fungiert. Für JavaScript wiederum haben wir in
Kapitel 3 gesehen, dass der Start unserer Routinen über Browserbuttons
oder einfach nur dem Laden einer Seite erfolgt. Für unsere Zwecke in diesem Buch reicht es am Anfang jedoch erstmal aus, die Skriptprogramme
manuell zu starten, also ohne den Kontext eines Browsers oder Servers. Dies ist zwar eine erhebliche Vereinfachung der Situation; für das
Kennenlernen der Verhaltensweisen unseres Computers jedoch absolut ausreichend.
JavaScript
Sehen wir uns das Hello World Programm mal in JavaScript an. Hierzu wollen wir es also nicht über einen Browser starten, sondern über
die node.js Laufzeitumgebung:
Listing 1: Hello World in JavaScript
Das vermutlich Auffälligste im Vergleich zu den kompilierten Programmiersprachen ist das Fehlen des Hauptprogramms. Der Interpreter arbeitet
das Skript einfach von der ersten Zeile beginnend ab, weshalb unser Hello World Programm auf eine einzige Codezeile zusammenschrumpft. Wir
sehen bereits einen Charme der Skriptsprachen – sie versuchen uns das Leben möglichst leicht zu machen. Man hat in interpretierten Sprachen
die Möglichkeit, das Skript einfach abzuarbeiten, warum also ein Hauptprogramm einfordern? Aber es gibt leider immer eine Kehrseite der Medaille.
Die Frage ist nämlich, können wir wie in den anderen Programmiersprachen nun keine Aufrufparameter hinterlegen? Nun, hierfür haben sich die
Programmierer der node.js Laufzeitumgebung eine Lösung überlegt. Es gibt fest definierte Objekte, welche von Haus aus existieren. Eines davon
ist das
process Objekt, in dem alle für den aktuellen Prozess relevanten Informationen zu finden sind – und somit auch die Aufrufparameter. Sehen wir
uns hierfür folgenden Code an:
Listing 2: Hello Parameter in JavaScript
Kurze Erklärung der Codezeilen: Die Ausgabe über
„console.log()“ erhält einen zusammengesetzten String, der aus „Hello “, einem Parameter und dann einem Ausrufezeichen besteht. Der Paramter
befindet sich im
process Objekt und dort in der Eigenschaft
„argv“. Dies ist ein Array, welches die Aufrufparameter enthält, wobei die Position 0 für den absoluten Pfad auf
node.exe – also der Laufzeitumgebung steht, die Position 1 für den absoluten Pfad auf das aktuelle Skript (in unserem Fall habe ich es
myHello.js genannt) und ab der Position 2 auf die Aufrufparameter abgreifbar sind.
Starten wir das Programm mit
„node myHello Mars“ in der Konsole und erhalten:
Ein Hinweis noch zum Semikolon am Ende jeder Zeile, da es hier mitunter verschiedene Ansichten dazu gibt, ob es notwendig ist oder nicht. JavaScript kann beim
Interpretieren die fehlenden Semikolons automatisch einbauen – hier wurde ein Automatismus etabliert, der dies erledigen soll. Im Zuge von Konsistenz und
Kompatibilität empfehle ich aber, die Semikolons immer selbst zu schreiben und dies nicht der ASI (Automatic Semicolon Insertion) zu überlassen.
Python
Sehen wir uns nun das HelloWorld Programm mal in Python an:
Listing 3: Hello Parameter in Python
Kurze Erklärung der Codezeilen: In Python finden wir die Aufrufparameter im Modul
„sys“, welches wir zuerst über einen Import bekannt machen müssen.
„sys“ besitzt das
„argv“ Array, in dem wir auf Position 0 den Skriptnamen finden und ab Position 1 die Parameter.
Was vielleicht auffällt ist das Fehlen der Semikolons am Ende jedes Statements. Die „Erfinder“ von Python versuchten, alles Unnötige aus der Sprache
herauszulösen. Das Semikolon dient in den anderen Sprachen ja als Trennzeichen zwischen einzelnen Statements. Nun macht fast jeder Programmierer aber nach dem
Semikolon einen Zeilenumbruch, damit das nächste Statement in der nächsten Zeile beginnt und der Code somit übersichtlicher wird. In Python ist dieser
optionale Zeilenumbruch nun Pflicht, weshalb das Semikolon obsolet geworden ist. Wir werden im Folgenden noch ähnliche Besonderheiten von Python sehen.
Starten wir nun unser kleines Python Programm mit „python myHello.py World“
Also auch hier wieder sehr ähnliche Konzepte in den einzelnen Programmiersprachen.
PHP
Nun fehlt uns jetzt noch PHP:
Listing 4: Hello Parameter in PHP
Kurze Erklärung der Codezeilen: PHP benötigt keinen Import für Grundfunktionen wie
echo – was eine Ausgabe ermöglicht. Wichtig ist aber die Einleitung von PHP Code mit
„<?php“ und die Endmarkierung mit
„?>“. Dies zeigt dem Interpreter die Stellen an, welche zu interpretieren sind. Alle anderen Stellen werden 1:1 „durchgereicht“, sprich
unverändert ausgegeben. Im Code sehen wir, dass die Ausgabefunktion echo keine Klammern benötigt, sondern alles im Folgenden bis zum Semikolon ausgibt.
Die Stringverkettung erfolgt in PHP nicht mit
„+“ wie in JavaScript, sondern mit dem Punkt. Ein weiterer Unterschied zu JavaScript und Python ist, dass Variablen in PHP immer mit einem vorangestellten
„$“ zu versehen sind, da sie sonst nicht als Variablen erkannt werden. Die Aufrufargumente sind in PHP nicht in einem Objekt versteckt, sondern in einem
global existierenden Array namens
„$argv“. An der 0. Position finden wir wieder den Namen der ausgeführten Datei (in unserem Fall wäre dies
„myHello.php“) und ab der 1. Position die Aufrufparameter.
Bevor wir auf die Markierungen nochmal eingehen, starten wir den Code mit „php myHello.php World“ und erhalten wieder:
Gehen wir nochmal auf die Besonderheit der Anfangs- und Endmarkierungen von PHP ein. Diese Sprache wurde speziell dafür entwickelt, Webinhalte serverseitig zu
verarbeiten. Nun versteht unser Browser streng genommen nur in HTML codierte Informationen. Also muss PHP auch HTML codierte Daten an den Browser senden.
Es wäre jetzt aber sehr aufwändig, die gesamte HTML Struktur über echo Befehle auszugeben. Viele andere Programmiersprachen wie bspw. Java würden so etwas zwar
fordern wenn sie serverseitig für Webinhalte genutzt werden – diese Programmiersprachen wurden aber nicht primär für den Zweck der HTML Datenerzeugung entwickelt,
sondern sind nachträglich auf diesen Einsatzzweck „getrimmt“ worden. Bei PHP hat man von Tag 1 an aber diesen Zweck „HTML“ im Fokus gehabt. Stellen wir uns nun
vor, wir haben folgende Webseite:
Listing 5: HTML Seite für Hallo Welt Ausgabe
Wir wollen aber das „Welt“ serverseitig austauschen – sagen wir in der Variablen
$currentLocation ist der Wohnort des Users gespeichert (wie auch immer dieser Wert da hingekommen ist). Wenn wir diese Seite jetzt als dynamische PHP Seite
erstellen wollen, dann würde sie wie folgt aussehen:
Listing 6: PHP Seite für Hallo „Variable“ Ausgabe
Wenn nun der Server dieses File verarbeitet, wird alles bis
„<?php“ 1:1 an den Client gesendet. Ab dieser Markierung wird der Code ausgeführt – sprich der Inhalt der Variablen
$currentLocation ausgegeben und nach
„?>“ wieder alles 1:1 ausgegeben. Für den Bau von Webseiten ist dieses Vorgehen also recht praktisch. Versuchen wir nun von diesem Verhalten für unser
„myHello.php“ Programm zu profitieren und bauen es etwas um:
Listing 7: Hello Parameter in PHP mit 1:1 - Durchreichung von Text
Starten wir wieder mit „php myHello.php World“, erhalten wir:
Variablen
Der nächste wichtige Punkt beim Verständnis von Programmiersprachen ist der Umgang mit Variablen, wie wir es bei den kompilierten Sprachen ja bereits untersucht haben.
Sehen wir uns folgenden Python Code hierfür mal an:
Listing 8: Variablennutzung in Python
Kurze Erklärung der Codezeilen: Da Python dynamisch typisiert ist, haben die Python Autoren die Kennung von Variablen für die Deklaration komplett entfernt.
Wir brauchen also vor
stringVar nichts schreiben. In JavaScript müsste hier
var oder
let stehen, in PHP ein Dollarzeichen. Wie alle dynamisch typisierten Sprachen, muss Python aus dem Kontext heraus entscheiden, um was für ein Datentyp es sich
handelt. In unserem Fall haben wir eine Stringkonstante "2" zugewiesen, also weiß Python, es muss sich um einen
String handeln. Bei
intVar wird eine ganze Zahl zugewiesen, also wird intern auch eine ganzzahlige Variable erstellt. Nun versuchen wir diese beiden Variablen zu vergleichen.
Dies würde in C immer zu „ungleich“ führen, bei Java und C# wäre der Vergleich nicht möglich – der Compiler würde den Code nicht kompilieren, da der Vergleich
von unterschiedlichen Datentypen wie
String und
int nicht vorgesehen ist. In dynamisch typisierten Sprachen muss so etwas aber gehen, da wir die Variablen beim Codieren ja noch nicht einem Typen zugeordnet
haben. Je nachdem, ob Python nun die beiden Werte als gleich oder ungleich interpretiert, würde die entsprechende Meldung ausgegeben.
Auch hier noch ein kurzer Hinweis auf die Python Besonderheiten. In den meisten Programmiersprachen gilt es als „guter Stil“, abgegrenzte Bereiche
(meist solche, die durch geschweifte Klammern abgegrenzt werden, wie bspw. Schleifenrümpfe) auch optisch einzurücken, um den Code lesbarer zu machen –
siehe hierzu bspw. die Schleifen im nächsten Kapitel. In Python geht man hier einen Schritt weiter, indem die Einrückung zwingend vorgeschrieben ist,
wodurch wiederum die geschweiften Klammern obsolet geworden sind. Da man theoretisch auch auf die Klammern nach
„if“ verzichten kann, muss nun ein Zeichen die
if Bedingung abschließen, weshalb hier der Doppelpunkt nach dem Vergleich und somit konsequenterweise auch nach dem
„else“ eingetragen wird.
Starten wir aber nun das Programm und sehen, wie Python die beiden Variablen interpretiert. Wir erhalten ein „ungleich“ auf dem Bildschirm. Python hat also
einen Vergleich durchgeführt und beide Werte als unterschiedlich erkannt – da Python unter einem String etwas anderes versteht als unter einer Zahl.
Ab der Version 3.6 hat Python eine Möglichkeit eingeführt, einen Typenhinweis an eine Variable zu hängen. So kann man den Code auch wie folgt schreiben:
Listing 9: Variablennutzung in Python mit Typenhinweis
Wir schreiben also nach der Variablen einen Doppelpunkt, gefolgt vom Datentyp. Diese Ergänzung hat allerdings nur informativen Charakter. Intern passiert genau
das gleiche wie ohne Typisierung. Wir können dies sehr einfach beweisen, indem wir einfach die Anführungsstriche bei „2“ entfernen und erhalten danach ein
„gleich“ auf dem Bildschirm. Dieses „flaggen“ von Variablen mit den empfohlenen Datentypen ist lediglich für nachträgliche Prüfungen des Codes wichtig.
Insofern werden wir an dieser Stelle nicht weiter darauf eingehen.
Kümmern wir uns nun um JavaScript. Wir schreiben also die gleiche Funktionalität in JavaScript:
Listing 10: Variablennutzung in JavaScript
Kurze Erklärung der Codezeilen: JavaScript ist von der Syntax her sehr nahe an Java und C angelehnt,
weshalb die
if Abfrage 1:1 wie in diesen Programmiersprachen aussieht. Die Variablendeklaration wird in
JavaScript auch benötigt, allerdings nicht mit einem Datentypen, sondern nur mit dem Schlüsselwort
var,
let oder
const, wobei
const eine Konstante definiert (der Wert kann also nicht mehr verändert werden).
let und
var deklarieren eine Variable, wobei
var die erneute Deklaration dieser Variablen im aktuellen Kontext erlaubt und
let dies verhindert. Es wäre also in unserem Codebeispiel möglich
var intVar = 3; am Ende zu schreiben, nicht aber
let stringVar = "2";
Wenn wir den Code nun ausführen, sehen wir erstmal eine Überraschung – wir erhalten ein „gleich“.
JavaScript scheint also nicht zwischen Strings und int zu unterscheiden? Die Antwort ist nun etwas
komplizierter. JavaScript ist dazu gebaut worden, viele Daten über den Webbrowser zu verarbeiten.
Die Eingaben in Textfeldern sind immer vom Datentyp
„String“. Wenn aber nun Zahlen eingegeben werden, wollte man den Entwicklern die Mühe sparen, die
Werte immer in
„int“ umzuwandeln – wir erinnern uns an die Notwendigkeit des Parsens von Strings in Java und Co.
Dieses Verhalten von JavaScript scheint nun aber dem Gedanken zu widersprechen, dass die Daten in
einem Computer grundsätzlich typisiert im Speicher abgelegt werden müssen. Die Klärung dieses
Widerspruches ist nun relativ einfach. In JavaScript wird bei einem Vergleich mit
„==“ automatisch eine Typkonvertierung gemacht, bevor verglichen wird. Man spricht hier von einer
„losen Gleichheit“. Nun gibt es aber Situationen, bei denen man durchaus den Unterschied zwischen
dem String „2“ und der Zahl 2 unterscheiden möchte. Dieser ist zwar seltener, aber denkbar.
Hierfür hat man in JavaScript die Prüfung auf „strikte Gleichheit“ eingeführt, was mit einem
dreifachen Istgleichzeichen notiert wird:
„===“. Probieren wir es aus:
Listing 11: Strikte Gleichheit in JavaScript
Führen wir diesen Code aus, erhalten wir ein „ungleich“ auf der Konsole. In PHP ist das Verhalten genauso
wie in JavaScript, sprich man unterscheidet die lose und die strikte Gleichheit (hier auch mit doppelten
und dreifachen Istgleichzeichen). In Python gibt es das nicht – hier müssen wir für eine lose
Gleichheitsprüfung selbst den String in eine Zahl umwandeln:
Listing 12: Variablennutzung in Python
Die Parsefunktion ist in Python
int(), wodurch wir hier wieder ein „gleich“ auf der Konsole finden. Ist das Vorgehen von JavaScript
und PHP nun sinnvoller, oder problematischer? Die Antwort liegt wieder im Auge des Betrachters –
bzw. daran, was man eigentlich erreichen will. Wie weiter oben schon mal erwähnt, sind bei einem
Großteil der Anwendungsfälle die „Annehmlichkeiten“ von Skriptsprachen sehr entgegenkommend für den
Programmierer. Die restlichen Fälle können dann eher Kopfzerbrechen bereiten und müssen mit
„Extralocken“ behandelt werden. Sehen wir uns nun folgenden JavaScript Code hierzu mal an:
Listing 13: Unterschiedliches Datentypverhalten in JavaScript
Obwohl laut Listing 10 die beiden Variablen bei einem losen
Vergleich identisch sind, erhalten wir beim
„+“ Operator unterschiedliche Ergebnisse, wie die Konsolenausgabe uns
Verrät:
Das Problem ist, dass in JavaScript der
„+“ Operator bei Strings eine Verkettung durchführt und bei Zahlen eine Addition. Auch wenn also die
Skripte uns die Entscheidungen über die Datentypen abnehmen – die tatsächlich genutzten Datentypen
sollten wir uns trotzdem immer vor Augen führen. Für Analysen bieten die einzelnen Skriptsprachen oft
einen Weg, den Datentypen festzustellen. In JavaScript wäre dies
„typeof“:
Listing 14: Ermittlung des Datentyps in JavaScript
Die Konsole verrät uns hier „number“. In PHP wäre diese Funktion
„gettype()“ und in Python
„type()“. Nun bleibt die Frage, wie bestimmen die Skriptsprachen eigentlich die Datentypen? Im
Prinzip haben wir diese Frage schon beantwortet – bei der Zuweisung wird geprüft, was eben zugewiesen
wird und der Datentyp des zugewiesenen Wertes wird auf die Variable übertragen. Das funktioniert
bei Strings sehr gut, bei Zahlen nur dann, wenn wir nicht bis zu den Grenzwerten stoßen. Bei
Gleitkommazahlen greift JavaScript auf
„double“ zurück – sprich eine 64 Bit Gleitkommazahl, wie es in Kapitel 6
beschrieben wurde. Intern wird dieser Datentyp zwar
„Number“ genannt, ist aber nichts anderes. Komplizierter wird es bei ganzen Zahlen. Hier gilt es drei
verschiedene Situationen zu unterscheiden:
- Zahlen im Bereich von int (also – 2.147.483.648 bis +2.147.483.647).
- Zahlen im Bereich der Mantissengenauigkeit einer double Zahl plus Vorzeichenbit (+/-253-1, was einen Wertebereich von -9.007.199.254.740.991 bis 9.007.199.254.740.991 ergibt).
- Zahlen außerhalb des Vorausgenannten.
Es gibt jetzt Operatoren, welche bei den einzelnen Wertebereichen unterschiedlich funktionieren.
Beginnen wir mit dem Integerbereich. Hier funktionieren erstmal alle mathematischen Operationen,
Vergleiche und die Bitshift Operationen, also das Verschieben der Bits nach links (sprich
abschneiden der rechten Bits) oder Verschieben nach rechts (sprich rechts Auffüllen mit 0). Sobald
ein Wert größer als der definierte Wertebereich
int ist, wird intern der Wert als Gleitkomma gespeichert, aber als Ganzzahlenwert ausgegeben. Dadurch
funktionieren noch alle mathematischen Vorgänge, nicht aber das Verschieben von Bits:
Listing 15: Verhalten von ganzzahligen Daten in JavaScript
Kurze Erklärung der Codezeilen: Wir initialisieren
intVar mit einem Wert innerhalb der
int Grenzen (hier der größte gerade Wert). Danach geben wir den Wert geteilt durch zwei aus.
Ein Bitshift nach rechts ist ebenfalls eine Division durch 2, weshalb wir also mit
„intVar>>=1“ die Division als Bitshift durchführen und den Wert gleich wieder in
intVar eintragen (das wird durch das
„=“ nach dem
„>>“ garantiert). Nun geben wir diesen Wert aus. Das Gleiche machen wir nun auch mit einem Wert, der
gerade außerhalb des
int Wertebereiches liegt.
Führen wir das Programm aus, sehen wir:
Die Division ist also der mathematische Prozess und gibt in beiden Fällen den richtigen Wert aus –
innerhalb und außerhalb der
int Grenzen. Die Bitshift Division liefert aber nur innerhalb der
int Grenzen einen korrekten Wert. Die nächste zu untersuchende Grenze ist 253-1.
Sehen wir uns hierfür folgenden Code an, in dem wir den maximal möglichen ganzzahligen Wert mit
+= 1 um eins erhöhen:
Listing 16: Überschreitung des sicheren ganzzahligen Bereiches in JavaScript
Die Ausgabe lautet wieder 9007199254740992. Die Addition um 1 war also außerhalb der Präzision der
darunterliegenden Gleitkommazahl. Ändern wir die Erhöhung auf 2 mit
+= 2 erhalten wir den korrekten Wert 9007199254740994. Über dem im Programm angegebenen
Initialisierungswert können wir also nicht mehr sicher mit Integerwerten rechnen. Da dies eine wichtige
Obergrenze ist, können wir in JavaScript diesen Wert vom System erhalten, indem wir den Konstantwert
„Number.MAX_SAFE_INTEGER“ auslesen. Hier versteckt sich auch der eigentliche Name des Zahlendatentyps von
JavaScript, nämlich
„Number“. Intern behandelt JavaScript also alle Zahlenwerte mit
„Number“, was nichts anderes ist als eine „Gleitkommazahl doppelter Präzision“, sprich
„double“. Man kann dies auch sehen, indem man eine Variable mit 0 initialisiert, mit -1 multipliziert um -0 zu
erhalten, was laut
Kapitel 6 in Java nur mit einem
float (bzw.
double) Datentyp möglich ist. Lediglich bei bitweisen Operationen wandelt JavaScript die Werte in 32 Bit
Ganzzahlenwerte um.
Um nun den Wertebereich außerhalb der „max save integer“ Grenzen abdecken zu können, wurde der Datentyp
„BIGINT“ eingeführt. Dieser hat einen (theoretisch) unendlichen Wertebereich, muss aber explizit als solches
erzeugt werden. Dies geht in JavaScript entweder mit dem Zusatz
„n“ nach der Zahl, oder man nutzt einen Konstruktor (womit wir also doch wieder bei einer Typisierung wären):
Listing 17: Erweiterung des sicheren ganzzahligen Bereiches in JavaScript
Kurze Erklärung der Codezeilen: Bei der Initialisierung mit einem
BigInt Konstantwert wird das
„n“ (ähnlich wie das
„l“ in Java bei
„long“) hinten angehängt. Wenn der Datentyp
„BigInt“ ist, dürfen mathematische Operationen nur innerhalb dieses Datentyps durchgeführt werden,
weshalb wir bei der Addition von 1 auch hier
„1n“ sprich
BigInt verwenden müssen. Bei der Nutzung des Konstruktors (für
bigIntVar2) ist das
„n“ nicht notwendig, da JavaScript hier weiß, dass höhere Werte als
MAX_SAVE_INTEGER kommen können und der Interpreter den Parameter ähnlich wie einen String parst.
Wir sehen bei der Ausgabe, dass die Rechnung hier korrekt durchgeführt wird.
Jetzt, da wir wissen, dass in JavaScript (mit Ausnahme
BigInt) jede Zahl als Gleitkommazahl verarbeitet wird, sollte die Ausgabe des folgenden Codes auch nicht
verwundern:
Listing 18: Datentypen bei mathematischen Operatoren in JavaScript
Das Ergebnis ist natürlich 0.5 – insofern keine Besonderheit. Versuchen wir den gleichen Code nun mal in Java:
Listing 19: Datentypen bei mathematischen Operationen in Java
Führen wir diesen Code aus, erhalten wir 0. Wir werden uns um dieses Phänomen nochmal intensiver bei den
Operatoren kümmern – so viel sei hier aber schon vorweggegriffen: In typisierten Programmiersprachen
ist bei der Verrechnung von zwei gleichen Datentypen das Ergebnis immer gleich diesem Datentyp. Integer
durch Integer ergibt also Integer – in unserem Fall also nicht 0.5 (was ja keine ganze Zahl ist),
sondern eben nur der Ganzzahlenanteil 0. Dieses Verhalten gibt es bei nicht typisierten
Programmiersprachen nicht – es kommt das „richtige“ Ergebnis 0.5 heraus. Dies gilt natürlich auch für
PHP und Python.
Wie verhält sich nun PHP bei den Zahlenwerten – sprich wie legt PHP ganzzahlige Datentypen ab. Hier ist
erstmal zu unterscheiden, ob wir die 32Bit oder 64Bit PHP-Installation nutzen, da hier die int Werte
entweder als
Int32, der klassischen Integer Interpretation, oder eben
Int64, der Long Integer Interpretation abgelegt werden. Geht unser Wert über diesen Bereich hinaus,
schwenkt PHP auf Gleitkommazahlen um:
Listing 20: Anpassung ganzer Zahlen bei Überlauf in PHP
Da auf meinem Referenzsystem eine 64Bit Installation ist, habe ich den Maximalwert auf
263-1 gelegt und um 1 erhöht.
Fehlt uns jetzt noch Python in unserer Sammlung. Hier geht man einen anderen Weg. Prüfen wir erstmal
das Verhalten von Python:
Listing 21: Datentypverhalten von Python
Kurze Erklärung der Codezeilen: Der Code ist nicht wesentlich anders als in PHP oder JavaScript. Aufmerksam
machen möchte ich hier kurz auf
„str()“. In Python werden, wie auch in JavaScript, Strings mit dem
+ Operator verkettet, wobei JavaScript in der Lage ist, eine Zahl beim Verketten als String zu interpretieren.
Dies macht mitunter bei Kombinationen wie
„console.log("Summe: " + numVar1 + numVar2)“ Probleme. Die Frage ist schlichtweg, wird zuerst
numVar1 mit
numVar2 addiert und dann das Ergebnis mit dem String
„Summe: “ verkettet, oder zuerst
„Summe: “ mit
numVar1 verkettet und dann
numVar2 angefügt. JavaScript (und die anderen Sprachen, die
„+“ als Verkettungsoperator haben) würden für den Fall, dass
numVar1 den Wert „1“ und
numVar2 den Wert „2“ enthält „Summe: 12“ ausgeben, sprich von links nach rechts verketten und nicht vorher
summieren. In Python möchte man diesem Problem aus dem Weg gehen und verkettet ausschließlich Stings,
weshalb man Zahlen vor der Verkettung mit
„str()“ in Strings umwandelt.
Wenn wir den Code nun ausführen, erhalten wir:
Der Begriff
„float“ ist hier nicht als
„float“ Datentyp wie in den kompilierten Programmiersprachen zu verstehen, sondern als „Gleitkommazahl“.
Python interpretiert also das Ergebnis einer Division zwingend als eine Gleitkommazahl - selbst wenn die
Division durch 1 ist.
Weiterhin fällt auf, dass Python einfache Datentypen auch als Klassen interpretiert. Dies schafft
eine Flexibilität gegenüber den Maximalwerten – Python kennt (theoretisch) keine Obergrenzen von
int. Dies kann man mit folgendem Code schön sehen:
Listing 22: Bitlängenanpassung bei Wertvergrößerung in Python
Kurze Erklärung der Codezeilen: Wir starten mit dem ersten Wert, der mit 64 Bit dargestellt werden muss.
Bei der Ausgabe zeigen wir den Wert an. Da jeder Datentyp ein Objekt ist, können wir somit auch auf die
Methoden der Objekte mit dem Punktoperator zugreifen.
int kennt bspw. die Methode
bit_length(), welche die Notwendige Bitlänge im Speicher anzeigt. Diese geben wir zusätzlich aus. Nach
der Multiplikation mit 4 müsste nun entweder der Wert überlaufen, oder die Bitlänge sich verändern.
Führen wir den Code aus, erhalten wir:
Python vergrößert also automatisch den Speicherbereich für den größeren Wert. Der durchgängige
objektorientierte Ansatz für Daten hat den Python Autoren nun auch die Möglichkeiten eröffnet,
über die Grenzen der Rationalen Zahlen hinauszugehen. Python kennt bspw. „ab Werk“ komplexe
Zahlen(3). Diese Flexibilität und Unbeschränktheit von Python
erklärt auch ein Stück weit die große Akzeptanz von Python in Hochschulen.
(3) Eine kurze Einführung zu komplexen Zahlen folgt in einem späteren Kapitel
Arrays
Jetzt, da wir einen groben Überblick über die Datentypen haben welche wir in kompilierten Sprachen als
„primitive Datentypen“ verstehen würden, kümmern wir uns noch um ein wichtiges Konstrukt der
Programmierung, den Arrays. Bei den kompilierten Programmiersprachen sind Arrays ja nicht dynamisch
vergrößerbar.
In Skriptsprachen sieht das aufgrund ihrer Flexibilität durch die Interpretation anders aus. Die
einzelnen Skriptsprachen bieten einen ganzen Strauß an Funktionalitäten an, mit denen man Arrays nach
Belieben vergrößern, verkleinern oder sonst wie verarbeiten kann. Ich werde hier nur auf die wichtigsten
Funktionalitäten eingehen. Wer einen tieferen Einblick benötigt, dem seien die API-Beschreibungen der
einschlägigen Seiten (für JavaScript die Browserhersteller,
w3schools.com
oder
selfhtml.org, für PHP
php.net oder für Python
docs.python.org) oder eine einfache Suche wie „JavaScript API Array“ empfohlen. Im Folgenden werde ich
in JavaScript, Python und PHP wie bei den kompilierten Sprachen ein Array mit Initialwerten erstellen,
einen Wert auslesen, danach mittig einen Wert hinzufügen, den vorletzten Wert löschen und einen Wert ersetzen.
Danach werden alle Werte nochmal per Schleife ausgegeben. Beginnen wir mit JavaScript:
Listing 23: Arraymanipulation in JavaScript
Kurze Erklärung der Codezeilen: Das Array wird mit eckigen Klammern initialisiert. Alternativ würde man
auch den Weg über einen Arraykonstruktor gehen können:
„new Array("a", "b", "c", "e", "X", "F") oder für leere Arrays einfach
new Array(6). Der Zugriff läuft wie in den kompilierten Sprachen über den Index in eckigen Klammern.
Die wichtigste Funktion in JavaScript für die dynamische Arrayanpassung ist
splice(). Hiermit kann man bspw. einen Wert hinzufügen:
myArr.splice(3, 0, ["d"]). Dies bedeutet „Ändere das Array
myArr ab der 3. Position, lösche 0 Elemente und füge dann das Teilarray
["d"] (also hier nur ein Wert) hinzu. Dadurch ist in dem Array "a", "b", "c", "d", "e", "X", "F"
enthalten. Mit dem Aufruf
„splice(5, 1)“ wird wieder ab der 5. Stelle verändert – diesmal jedoch wird 1 Element gelöscht und
keines hinzugefügt. Die Ersetzung läuft über eine einfache Zuweisung an der entsprechenden Position.
Am Schluss sehen wir eine in diesem Buch schon öfter gesehene Zählschleife über die Länge des Arrays
myArr.length.
Die Ausgabe des Codes ist wie zu erwarten:
Leere zweidimensionale Arrays müssen in JavaScript etwas aufwändiger erzeugt werden. Da diese Konstrukte in JavaScript
genauso wie in Java „Arrays von Arrays“ sind, ist folgende Vorgehensweise möglich:
Listing 24: Erzeugung 2D Array in JavaScript
Alternativ wurde mit ES6 auch folgende Option möglich:
Listing 25: Erzeugung 2D Array in JavaScript mit Array.from()
Kurze Erklärung der Codezeilen:
Array.from() erzeugt aus dem ersten Argument ein Array – es sei denn, es handelt sich schon um ein Array, dann
wird es 1:1 verwendet. Das zweite Argument ist eine Mapping Funktion. Hier wird für jeden Eintrag des Arrays mit
=> der rechts davon stehende Code aufgerufen. Es wird also pro Arrayeintrag ein neues Array erzeugt.
Sehen wir uns nun Python an. Hier müssen wir gleich wieder eine Besonderheit klarstellen. Python kennt
unterscheidet zwischen Arrays und Listen. Das, was wir in PHP und JavaScript als Array verstehen, ist in
Python eher eine Liste.
Listing 26: „Array“-Manipulation in Python
Arrays sind in Python im Wesentlichen typisiert – bzw. sie erlauben nur einen Datentyp, den man bei der Erzeugung
auch als Parameter angeben muss. Sehen wir uns den Vergleich von List und Array hierzu an:
Listing 27: Liste vs. Array in Python
Kurze Erklärung der Codezeilen: Der
import ist für das
array Modul notwendig. Die Arrayerzeugung benötigt den Datentyp(4)
(in unserem Fall Integer, weshalb das
"i" angegeben wurde). Danach folgt eine Auflistung, deren Elemente vom angegebenen Datentyp sein müssen.
Die Liste in myList wiederum benötigt keine Datentypspezifikation und kann Elemente verschiedener Datentypen
aufnehmen. Würde die Auflistung
[1, 2, "10", "20"] für die Arrayerzeugung eingetragen werden, so würden wir hiermit einen Fehler erzeugen.
(4) Weitere unterstützten Datentypen unter https://docs.python.org/3/library/array.html
Insgesamt ist das Array etwas effizienter als die List – sowohl in der Speicherbelegung als auch in
Puncto Performance. An dieser Stelle möchte ich auch noch ein paar Zusätzliche Infos mitgeben. Python
erlaubt auch das Erzeugen von leeren Listen
(myList = []) wo wir mit
myList.append("g") neue Elemente hinzufügen können, was performanter ist als mittels
myList.insert(7, "g"). Zweidimmensionale Listen müssen auch hier etwas umständlicher erzeugt werden:
Listing 28: Erzeugung 2D Listen in Python
Weiterhin liefert Python noch die Bibliothek
numpy, welche eine Vielzahl von mathematischen Tools für die Verarbeitung von Zahlen bietet und eine
eigene Array Implementierung aufweist.
Und nun der Vollständigkeit halber noch die Funktionalität in PHP:
Listing 29: Arraymanipulation in PHP
Kurze Erklärung der Codezeilen: Im Wesentlichen finden wir Konstrukte, welche bereits in anderen Sprachen
genutzt wurden, wie bspw.
„splice“. Was bei PHP jedoch auffällt ist, dass die Grundbausteine nicht wirklich objektorientiert sind.
Wir finden bspw. nicht wie in JavaScript oder Python die Möglichkeit, die Arraylänge direkt vom Array
abzugreifen. Also anstatt
$myArr.length() müssen wir eine externe Funktion nutzen und dieser das Array übergeben:
count($myArr).
Eine Anmerkung zu PHP ist hier noch notwendig. Diese Sprache geht sehr flexibel mit Arrays um – wir können beispielsweise eine Variable
als ein leeres Array deklarieren
($myArr = array();) und dann die einzelnen Arraypositionen belegen
($myArr[0] = "a"; $myArr[1] = "b";). Dies gilt auch für mehrdimensionale Arrays. Es ist also auch folgendes möglich:
$myArr2 = array(); $myArr2[0][0] = "a";
Wir haben nun gesehen, dass in unseren Skriptsprachen Arrays grundsätzlich erstmal dynamisch sind. Bei den kompilierten Programmiersprachen
haben wir aber noch einen zweiten Typus von dynamischen Arrays kennen gelernt, die assoziativen Arrays. Wie sieht es hier bei JavaScript
und Co aus? Wie eigentlich zu erwarten war, haben die Macher der Skriptsprachen das Handling im Vergleich zu den kompilierten
Programmiersprachen hier auch ziemlich vereinfacht. Sehen wir uns wieder zuerst JavaScript an:
Listing 30: Assoziatives Array in JavaScript
Kurze Erklärung der Codezeilen: Es wird also einfach ein leeres Array mit
[] erzeugt, wobei
Array() auch funktioniert. Danach wird einfach anstatt des Indexwertes der Key eingetragen und mit
„=“ der Wert zugewiesen. Der Lesezugriff funktioniert entsprechend. Einträge würde man mit delete wieder löschen:
delete cfgValues["DBType"];
Die Ausgabe ist somit:
JavaScript hat gegenüber dem klassischen assoziativen Array auch die Möglichkeit eine
„Map“ zu nutzen. Es handelt sich hier um ein Objekt, welches mit
„set()“,
„get()“ und
„delete()“ arbeitet. Details hierzu findet man wie immer in den einschlägigen Webseiten für JavaScript. Sehen wir uns nun die PHP-Lösung an.
Bis auf die Tatsache, dass man ein assoziatives Array in PHP relativ einfach mit Initialwerten belegen kann, ist das Handling vergleichbar
mit JavaScript:
Listing 31: Assoziatives Array in PHP
Das Löschen erfolgt in PHP mittels
unset(). Wenn wir bspw. den Eitnrag für DBType löschen wollen, geht dies mit
unset($cfgValues["DBType"]);. Schließlich fehlt uns noch Python, was bis auf ein paar Syntaxunterschiede wieder ähnlich zu PHP ist:
Listing 32: Assoziatives Array in Python
Python würde mit folgendem Kommando den DBType Eintrag löschen:
del cfgValues['DBType']. Wie immer, gibt es also kleine Unterschiede, welche aber nicht darüber hinwegtäuschen, dass die
eigentlich dahinterliegenden Konzepte sehr ähnlich sind. Der wesentliche Unterschied bei Skriptsprachen zu den kompilierten Sprachen ist wie immer die Flexibilität
bei der Nutzung von Variablen. Dies kann man als Vereinfachung, aber auch als „unsauber“ interpretieren. Wenn wir uns beispielsweise PHP ansehen, so unterscheidet die Sprache zwangsweise aus Sicht der Deklaration nicht zwischen „normalen“ und assoziativen Ar-rays. Da es also bei der Erzeugung nicht festgelegt wird, können wir ein und dieselbe Variable sowohl als indiziertes, als auch assoziatives Array nutzen:
Listing 33: Assoziatives Array in PHP mit Indexzugriff
Kurze Erklärung der Codezeilen: Der neue Eintrag wird nun mit dem Key 5 vorgenommen und bei der Ausgabe mit dem Index 5 gelesen.
print_r() formatiert ein Array (oder auch Objekt) in ein lesbares Format um.
Die Ausgabe lautet:
PHP behandelt also ein normales Array wie ein assoziatives, bei dem die Indexwerte als Keys zu verstehen sind. Dies ist bspw. beim
Auslesen von Datenbankwerten interessant, da hier mitunter beide Ansätze untersützt werden. Tabellenspalten werden also über
Key/Value Paare und/oder Indizes übergeben(5). Wenn wir die gleiche Übung in JavaScript machen, sieht die Sache wieder ganz anders aus:
Listing 34: Array mit Index und Key in JavaScript
Kurze Erklärung der Codezeilen: JavaScript gibt die Daten von Objekten und Arrays über
log()
strukturiert aus, sofern keine anderen Strings involviert sind. Die Struktur wird vor und nach der Ergänzung
eines assoziativen Arrays um einen Indexzugriff ausgegeben.
Die Ausgabe ist wie folgt:
Durch das Setzen eines Wertes auf Indexposition 5 wird das assoziative Array um fünf leere Elemente am Anfang aufgefüllt, danach
kommt der indizierte Wert und anschließend die Key/Value Paare. Hier sieht man, dass in JavaScript die Mischung aus assoziativen
und indizierten Elementen eigentlich keine saubere Lösung ist und somit ohnehin vermieden werden sollte. Interessanterweise würde
aber JavaScript einen Key, der einen reinen Zahlenwert darstellt ebenfalls als Index interpretieren:
Listing 35: Indiziertes Array in JavaScript trotz Verzicht auf Indexwerte
Die Ausgabe ist vergleichbar mit einem Array, welches mit Index und Keys erzeugt wurde:
Python setzt diese Funktionalität meines Erachtens für Skriptsprachen am nachvollziehbarsten um, da indizierte Arrays zwar wie
assoziative Arrays behandelt werden, aber String Keys und Zahlenkeys (also Indizes) unterschieden werden:
Listing 36: Gemischtes Array in Python
Die Ausgabe beweist diese Aussage:
Funktionsaufrufe
Sehen wir und nun mal die Skriptsprachen bezüglich Funktionsaufrufe an – vor allem was das „call by value“ und „call by reference“
Verhalten angeht. Da wir bei Skriptsprachen ja keinen direkten Zugriff auf die Speicheradressen haben und somit keine Pointerarithmetik
auf dem Systemspeicher durchführen können liegt die Vermutung nahe, dass die Konzepte sich eher and Java und C# orientieren. Nutzen
wir hier das gleiche Verfahren wie in Kapitel 8, indem wir den Wert eines primitiven
Datentypen und eines Arrays in einem Unterprogramm ändern:
Listing 37: Übergabeverhalten in JavaScript
Der Code gibt, genau wie der Java Code aus Kapitel 8 die folgenden Werte aus:
Insofern war unsere Annahme richtig, dass die Umsetzungen identisch sind. Dieses Verhalten würde übrigens auch Python zeigen, was ich mir
jetzt spare zu zeigen.
Was wir in dem JavaScript Code auch noch sehen ist, dass die Unterprogramme in JavaScript
„function“ genannt werden, gefolgt von dem Funktionsnamen und der Parameterliste. Sehen wir uns nun ein
Konzept an, welches in den objektorientierten Programmiersprachen gang und gebe ist, aber bei
JavaScript aufgrund der fehlenden Typisierung(6) problematisch sein
dürfte: das Überladen von Funktionen.
Überladen bedeutet ja, dass man gleiche Funktionsnamen verwenden kann, die Unterscheidung zwischen den
einzelnen gleichnamigen Funktionen über die Datentypen und Reihenfolge der Parameter erfolgt. Mangels
Datentypen bei der Deklaration der Parameter in JavaScript gibt es hier also ein Problem. Versuchen wir es:
(6) Und der Stellung von Funktionen, was wir in Kürze näher betrachten werden
Listing 38: Versuch der Überladung von JavaScript Funktionen
Kurze Erklärung der Codezeilen: Wir haben zwei Funktionen, welche zwar gleich heißen, aber
unterschiedliche Parameterzahl aufweisen. Zur Kontrolle, welche der beiden Funktionen aufgerufen wurde,
wird „2 params“ bzw. „3 params“ ausgegeben. Der Rückgabewert beider ist die Summe aller Eingangsparameter,
indem wir die Summe über
return zurückgeben. Durch die beiden Aufrufe mit 1, 2 bzw. 1, 2 und 4 können wir somit prüfen, ob die
Überladung funktioniert.
Die Ausgabe beweist nun, dass JavaScript keine Überladungen unterstützt:
Es wurde also in beiden Fällen die Funktion mit drei Parametern aufgerufen – auch bei dem Aufruf
„doSum(1, 2)“. Die Funktion hat somit einen nicht initialisierten Parameter gefunden (nämlich
„c“), weshalb die Summierung fehlschlug. Um solche Probleme jetzt in den Griff zu bekommen, haben die
JavaScript Autoren noch die Möglichkeit des Defaultwertes eingeführt. Man kann die Parameterliste
unseres zweiten
„doSum“ nun wie folgt ergänzen:
„doSum(a, b, c = 0)“. Dadurch erhält
c einen Standardwert, wenn er nicht durch den Aufrufenden belegt wurde und wir können auf die erste
„doSum“ Funktion verzichten.
Das Ganze scheint nun eine eingeschränkte Funktionalität gegenüber Java und Co. zu sein, da wir hier die
Überladung relativ häufig nutzen. Der eigentliche Grund, warum das Überladen nicht funktioniert ist,
dass in JavaScript Funktionen genauso behandelt werden wie Objekte – sprich man kann sie auf Variablen
zuweisen:
Listing 39: Zuweisung von Funktionen in JavaScript
Kurze Erklärung der Codezeilen: Die Funktion
add() wird erzeugt und gibt lediglich die Summe der beiden Parameter zurück. Nun weisen wir die Funktionsnamen
add auf die Variable
doAdd zu. Diese Zuweisung erfolgt ohne Parameter – wodurch die Identifikation einer Funktion einzig und alleine
auf dem Funktionsnamen beruht. Nun zeigt die Variable
doAdd auf die Funktion und wir können sie mit
doAdd() aufrufen.
Die Ausgabe lautet somit 3. Man spricht bei JavaScript (und übrigens auch bei Python und PHP) davon,
dass Funktionen „first class citicens“ sind. Hiermit möchte man ausdrücken, dass sie genau wie Objekte
zugewiesen, übergeben oder zurückgegeben werden können. Im einem späteren Kapitel werden
wir uns im Rahmen der funktionalen Programmierung nochmal darum kümmern. Untersuchen wir nun das
Phänomen der Überladung in Python und lernen gleichzeitig den Python Syntax für die Funktionsdefinitionen:
Listing 40: Versuch der Überladung von Python Funktionen
Kurze Erklärung der Codezeilen: In Python werden Funktionen mit def festgelegt, gefolgt vom Funktionsnamen,
Parameterliste und dann ein
„:“. Was bei Python im Gegensatz zu JavaScript auffällt ist, dass wir zuerst die Funktionen schreiben müssen,
bevor wir sie im Code nutzen. Wir können also die beiden Aufrufe der Funktionen erst nach der Definition durchführen.
Führen wir den Code aus, erhalten wir eine Fehlermeldung:
Python kann also auch nicht überladen, bietet aber genau wie JavaScript die Möglichkeit mit der
„= 0“ Ergänzung einen Defaultwert zu setzen, wodurch der Code wieder korrekt läuft. Nun sieht man
mitunter in Python die Funktionsdeklarationen mit typisierten Parametern. Man kann also festlegen,
mit welchen Datentypen man zu tun hat. Sehen wir uns die Summierungsfunktion hierzu nochmal an:
Listing 41: Typisierte Parameter in Python
Kurze Erklärung der Codezeilen: Die Variablen
a und
b sollen jeweils vom Typ
int sein und auch der Rückgabetyp wird mit Hilfe der
-> Notation als
int vorgegeben.
Soweit erstmal nichts Besonderes, außer dass man hier bei einer dynamisch typisierten Programmiersprache
doch wieder Datentypen vorgibt. Die Frage ist nun, was bei einem Konflikt passiert. Provozieren wir also mal einen Fehler:
Listing 42: Ignorieren der Typvorgaben in Python
Kurze Erklärung der Codezeilen: Zuerst müssen wir über
import sicherstellen, dass der Datentyp String überhaupt akzeptiert wird, da er nicht "primitiv" ist. Die Variablen
a und
b sollen nun vom Typ
String sein. Den Rückgabetyp habe ich ebenfalls auf
String gesetzt. Beim Aufruf übergebe ich aber wieder Zahlen. Den Rückgabewert addiere ich nun mit einer
weiteren Zahl, was in Python bei Strings nicht möglich sein dürfte.
Führen wir den Code aus, sehen wir die Zahl 6. Python ignoriert also einfach die Typvorgaben. Also
warum der ganze Aufwand, wenn er ohnehin ignoriert wird? Die Antwort liegt außerhalb von Python.
Wenn wir mit Prüfungstools versuchen unseren Code auf potentielle Fehler zu überprüfen, dann spielen
die Typisierungen oft eine große Rolle. Insofern hat man in Python zwar syntaktisch die Typisierung
eingeführt, jedoch nur um einen „Typhinweis“ (engl. „type hint“) auf die erwarteten Datentypen zu
hinterlegen. Die Interpretation des Codes erfolgt nach wie vor wie bei nicht (bzw. dynamisch) typisierten
Aufrufen – Python legt erst zur Laufzeit die Datentypen fest. PHP bietet ebenfalls Typisierungen bei
Funktionsaufrufen an, welche ebenfalls als „type hint“ gewertet werden.
Nun haben wir bei unseren bisherigen Untersuchungen des Aufrufverhaltens PHP außen vorgelassen.
PHP müssen wir an dieser Stelle getrennt untersuchen, da PHP das Konzept „call by value“ und „call by
reference“ explizit unterstützt und sich somit grundsätzlich anders verhält als JavaScript und Python.
Testen wir wieder unser Übergabeverhalten mit unserem bekannten Ansatz:
Listing 43: Übergabeverhalten in PHP
Im Gegensatz zu JavaScript und Python, erhalten wir folgende Ausgabe:
PHP übergibt also auch ein Array als Value – es wird eine Kopie des gesamten Arrays angefertigt und
übergeben! Wenn wir dies nicht wollen, müssen wir den
„&“ Operator bei der Parameterdeklaration verwenden. Wir passen also die Funktionen aus
Listing 43 an:
Listing 44: Übergabeverhalten in PHP – call by reference
Nun führen wir den Code wieder aus und erhalten:
Wir haben also in PHP, ähnlich wie in C, die Möglichkeit der expliziten Wahl, ob wir call by value oder by
reference haben möchten. Der Unterschied liegt darin, dass dies nur in der Parameterdeklaration festgelegt wird
und der Aufruf für beide Varianten gleichbleibt. Was nun noch fehlt ist die Frage der Überladung.
PHP funktioniert hier genauso wie Python und JavaScript – wenn wir überladen, erzeugen wir eine
Fehlermeldung. Nachdem aber auch Defaultwerte unterstützt werden, können wir diese Mechanik wieder für uns nutzen:
Listing 45: Defaultwerte für Funktionsparameter in PHP
Die Ausgabe auf der Konsole lautet:
Bevor wir uns auf die Strukturierung von Code in den Skriptsprachen stürzen, müssen wir noch eine sehr oft
genutzte Syntaxvariante bei der Funktionendefinition in Skriptsprachen sprechen; und zwar die sogenannten
anonymen Funktionen, welche wegen der möglichen Notation in PHP und JavaScript mit dem
=> Operator auch „Pfeilfunktionen“ genannt werden. Im Listing 25
haben wir eine solche Funktionalität im Rahmen von JavaScript bereits genutzt. Zeit, sich dieses Konstrukt mal
genauer anzusehen. In Skriptsprachen können wir anstatt einer Funktion einen Namen zu geben, meist Funktionen
einer Variablen zuordnen, wodurch der Variablenname scheinbar zum Funktionsnamen wird:
Listing 46: Anonyme Funktion in JavaScript
Bei Start des Codes sehen wir „Hallo Maik“ auf der Konsole. Was hier eigentlich passiert, ist dass wir eine
anonyme Funktion – also eine Funktion ohne Namen – erstellen, welche wir einer Variablen zuweisen. Die
Variable hält also eine Referenz auf eine Funktion. Ähnlich der Lambda Funktionen können wir nun diese
Schreibweise abkürzen:
Listing 47: Pfeilfunktion in JavaScript
Da in unserem Beispiel die Funktion nur ein Statement enthält, könnten in JavaScript die geschweiften Klammern auch
weggelassen werden. Gleiches gilt für die runden Klammern – wenn nur ein Parameter existiert, könnten diese auch
entfernt werden. In solch einem Fall schreibt man die Funktion meist in einer Zeile:
Listing 48: Weglassen von Klammern in Pfeilfunktion bei JavaScript
Returnwerte werden wie in „normalen“ Funktionen mit
return zurückgegeben:
Listing 49: Return bei Pfeilfunktionen in JavaScript
Wird jedoch nur eine Aktion durchgeführt, so kann auch hierauf verzichtet werden:
Listing 50: Verzicht auf return bei Pfeilfunktionen in JavaScript
Eine sehr vorteilhafte Nutzungsweise der Pfeilfunktionen in JavaScript können wir bei der Verarbeitung
von Arrays zusammen mit der
forEach() Funktion sehen:
Listing 51: Nutzung Pfeilfunktionen mit Arrays in JavaScript
Die Ausgabe lautet:
Hier sehen wir, dass der Code auf jeden Fall kompakter, wenngleich nicht immer übersichtlicher wird.
In PHP finden wir ebenfalls die Möglichkeit von anonymen Funktionen:
Listing 52: Anonyme Funktion in PHP
Seit der Version 7.4 erlaubt PHP auch die Notation mittels des Pfeiloperators:
Listing 53: Pfeilfunktion bei PHP
Wichtig bei PHP im Zusammenhang mit dem Pfeiloperator ist, dass wir hier nach der Zuweisung
fn() schreiben und nicht
function(). Weiterhin darf nach dem
=> nur ein Ausdruck stehen – wir dürfen also nicht wie in JavaScript mit geschweiften Klammern
komplexere Funktionaltäten erstellen. Genauso haben wir nicht die Option
„return“ als Schlüsselwort einzutragen, es wird lediglich das Ergebnis des Ausdrucks zurückgegeben:
Listing 54: Pfeilfunktionen mit Rückgabewert in PHP
Python sieht hier ein eigenes Schlüsselwort für die Definition von anonymen Funktionen vor:
lambda – ein Begriff, den wir aus Java ja bereits kennen:
Listing 55: Lambdaausdruck in Python
Auch hier gilt, dass wir als Lambdaausdruck nur einen Ausdruck verwenden dürfen – so wie es der Name
ja schon nahelegt. Die Parameter werden zwischen
lambda und dem Doppelpunkt kommasepariert hinterlegt. Rückgabewerte werden wie in PHP behandelt:
Listing 56: Lambdafunktion mit Rückgabewert in Python
Viele Skriptsprachen – und somit auch Python – ermöglicht uns mit
map() und
list() ebenfalls eine vereinfachte Verarbeitung von Arrays mit
Lambdaausdrücken(7):
(7) Details hierzu sehen wir uns in einem späteren Kapitel zum Thema funktionale Programmierung nochmal an
Listing 57: Arrayverarbeitung mit Lambdaausdrücken in Python
Kurze Erklärung der Codezeilen: Diese Notation
list(map()) verarbeitet das in
map() hinterlegte Array names mit der vor dem Komma hinterlegten Funktion. Da wir diese als anonyme Funktion
realisieren wollen, benötigen wir das
lambda Schlüsselwort. Das nach dem Komma befindliche Array
names wird somit Element für Element verarbeitet, indem jeder einzelne Wert aus dem Array in
name übernommen und mit der Funktion verarbeitet wird.
Oft wird jedoch keine Ausgabe durchgeführt, sondern eine anderweitige Verarbeitung der Daten, welche wieder in
einer anderen Liste abgelegt werden sollen:
Listing 58: Übertragung der verarbeiteten Arraydaten in eine Liste
Die Ausgabe lautet:
Es wurde also ein neues Array mit den veränderten Daten erstellt. Wir sind nun in der Lage, komplexere
Funktionalitäten in einzelne Unterprogramme zu zerlegen, über Defaultwerte eine gewisse Flexibilität
in der Handhabe von diesen Unterprogrammen zu erzeugen und sogar anonyme Funktionen definieren.
Modularisierung
Der nächste logische Schritt ist nun die Frage, wie kann ich die einzelnen Funktionalitäten sinnvoll ordnen und wiederverwendbar machen,
sprich „auslagern“. In den kompilierten Sprachen haben wir Schlüsselwörter wie
„import“ oder
„include“ um externe oder auch selbst erstellte Bibliotheken in unser Programm einzubinden. Eine solche Funktionalität wird auf jeden
Fall auch für Skriptsprachen benötigt. Hier gibt es aber keinen Compiler (und Linker), der sich um das Suchen und Zusammenfügen der
einzelnen Teilfunktionalitäten kümmert. Wir müssen also die ausgelagerten Funktionalitäten in eigene Skriptfiles schreiben und diese
dann geeignet referenzieren. Zur Laufzeit werden diese Files dann geöffnet und verarbeitet. Hier lauern aber ein paar Probleme. Am
besten sieht man das bei PHP. Wir lagern unsere Summierungsfunktion in ein eigenes File
„sub1.php“ aus und legen dies in einem Unterverzeichnis
„myfunctions“ an. Dort sehen wir auch gleich ein zweites File
„sub2.php“ für PHP-Funktionalitäten vor:
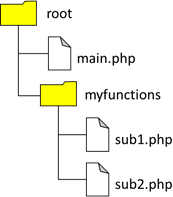
Abb.: 1: Beispielhafte Ordnerstruktur
Den Code unserer beiden Files main.php und sub1.php schreiben wir wie folgt:
Listing 59: Auslagerung von Code in eigene PHP Files
Kurze Erklärung der Codezeilen: Wir haben hier ein neues, wichtiges Programmiersprachenelement, den „Kommentar“ eingeführt. Wir
werden später näher darauf eingehen. In der hier genutzten Form wird die gesamte Zeile rechts von dem
„//“ Element nicht vom Interpreter ausgewertet, wir können also „Klartext“ schreiben und eben „kommentieren“. Danach folgt das
include, welches den Pfad in Anführungsstrichen erwartet. Die Pfadtrenner sind „Forwardslashes“ – also
“/“ wie in Linux oder iOS… übrigens funktioniert dieser Pfadtrenner so auch auf Windows Systemen, da sich der Interpreter darum
kümmert, aus den Forwardslashes für Windows wieder Backslashes zu machen.
Führen wir den Code von main.php aus, sehen wir die 3 auf der Konsole – wir haben also in
main.php eine Funktionalität aus einem anderen File
(sub1.php) genutzt. So weit scheint das Ganze erstmal einfach zu sein. Komplizierter wird es, wenn es mehr Files werden.
Erstellen wir
sub2.php mit folgendem Code:
Listing 60: Untergeordnetes File referenziert weiteres File in PHP
Kurze Erklärung der Codezeilen:
doSumAndPrint() nutzt nun die Funktionalität von
doSum(), weshalb hier auch ein
include notwendig ist. Da es im gleichen Verzeichnis zu finden ist, benötigen wir keine Pfadangabe. Die Funktion ruft nun
doSum() auf, speichert den Wert, damit er ausgegeben und an den Aufrufer zurückgegeben werden kann.
Und nun passen wir
main.php noch an, indem wir
sub2.php inkludieren und die neue
doSumAndPrint() Funktion nutzen:
Listing 61: Nutzung zweier untergeordneter Files in PHP
Kurze Erklärung der Codezeilen:
doSumAndPrint() befindet sich in
„sub2.php“, weshalb wir es auch einbinden müssen. Damit die beiden Ausgaben untereinander erscheinen, wurde noch ein Zeilenumbruch
ausgegeben.
Wenn wir nun versuchen, das Programm zu starten, erhalten wir einen Fehlercode. Das Problem ist, dass PHP die Definition von
doSum() zweimal liest und somit von einem Duplikat ausgeht. Wir können das Problem in dieser Situation dadurch lösen, dass wir in
main.php auf den
include von
sub1.php verzichten, da wir diesen ja über den
import in
sub2.php bereits haben. Wir müssen also immer genau nachvollziehen, welche includes gerade wo stehen. Das ist nun sehr fehleranfällig.
PHP liefert hier eine Abhilfe, indem wir in
sub2.php
include_once anstatt nur
include verwenden. Das Problem hier ist, dass
include_once inperformanter als
include ist. Prinzipiell ist also
include vorzuziehen, es sei denn, wir haben den Überblick über die includes verloren oder wir können aufgrund der Anzahl der
involvierten Programmierer im Projekt die saubere
include Struktur nicht garantieren. Neben
include und
include_once bietet PHP noch
require und
require_once an. Diese beiden Methoden funktionieren wie die
include Methoden, allerdings haben sie ein anderes Fehlerverhalten, wenn das referenzierte File nicht gefunden wird. Während die
„includes“ bei einer falschen Referenz einfach weiterarbeiten, brechen die „requires“ in solch einer Situation ab, was natürlich
beim Entwickeln die bessere Alternative ist, da wir im Entwicklungsprozess die Fehler nicht „vertuschen“, sondern finden wollen.
Eine abschließende Verhaltensweise bei PHP includes/requires ist noch wichtig. Es ist immer zu empfehlen, dass in den inkludierten Files
nur Code innerhalb Funktionen (und später Klassen) definiert wird, nie außerhalb. Ändern wir unser
main.php und
sub1.php wie folgt:
Listing 62: Variablen außerhalb Funktionen in PHP
Kurze Erklärung der Codezeilen: In
main.php wird die Variable
$myVar mit dem Wert „myValue“ erzeugt. In
sub1.php haben wir eine Varaible mit gleichem Namen außerhalb der Funktion festgelegt und den Wert „yourValue“ eingetragen. In main wird nun
$myVar ausgegeben.
Die Ausgabe zeigt, dass in
sub1.php der Wert von
$myVar überschrieben wurde, so dass in main.php „yourValue“ ausgebeben wird.
Die Variable
$myVar ist also global zugreifbar. Da PHP keinen eigenen Code für die Variablendeklaration hat, fällt dieses Verhalten während der
Codeerstellung nicht auf. Dies ist insofern problematisch, als dass man in größeren Projekten nicht immer weiß, wie die inkludierten
Files intern aufgebaut sind, da man sie einfach als Modul nutzt. Hält man sich an die Regel, außerhalb des zu startenden Files die
Variablen nur innerhalb von Funktionen zu nutzen, geht man diesem Problem aus dem Weg. Ändern wir bspw.
sub1.php wie folgt ab, erhalten wir in der Ausgabe „myValue“:
Listing 63: Variablen innerhalb Funktionen in PHP
Innerhalb der Funktionen werden die Variablen also in einem eigenen Kontext gesehen, auch wenn sie gleich heißen. Möchte ich trotzdem
innerhalb einer Funktion auf
$myVar aus dem globalen Kontext zugreifen, muss vor der Nutzung von
$myVar diese als global markiert werden:
„global $myVar;“. Wenn nun der Code wieder ausgeführt wird, würde wieder „yourValue“ ausgegeben werden. Man erkennt hier also, dass
der Vorteil der einfachen Nutzbarkeit von Skriptsprachen an einigen Stellen zu Sonderfällen führt, welche man mit zusätzlichen
Schlüsselwörtern wieder in den Griff bekommen muss. Wir werden bei der Besprechung der kompilierten objektorientierten Sprachen sehen,
dass man hier auf die Einfachheit der Anwendung zugunsten einer stringenten Anwendung von Konzepten und somit dieser „Extralocken“
verzichtet.
Werfen wir nun noch einen Blick auf Python. Hier wurde ein Modulkonzept eingeführt, um die imports besser strukturieren zu können.
Wenn wir die gleiche Funktionalität wie unser PHP-Beispiel umsetzen möchten, muss unser Filesystem wie folgt aussehen:
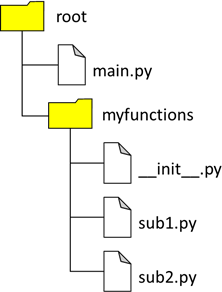
Abb.: 2: Modulsystem in Python
Wir benötigen also in dem Unterordner ein neues File, namens
„__init__.py“. Dieses kann erstmal leer sein. Python erkennt an diesem File, dass es sich um einen Modulunterordner handelt und platziert
hier auch noch automatisch einen weiteren Ordner für zwischengelagerte Informationen. Wenn die Struktur so angelegt wurde, können wir
die Python Files mit Inhalten füllen. Für den Code ist noch wichtig zu wissen, dass die Kommentardirektive für Python nicht der doppelte
Slash wie in den meisten Programmiersprachen ist, sondern ein
„#“ Zeichen:
Listing 64: Imports in Python
Kurze Erklärung der Codezeilen: Über
„import“ können nun die einzelnen Python Files importiert werden – da es sie ja als Module und nicht als Files gesehen werden,
ohne Anführungsstriche. Dadurch werden die Module automatisch geladen. Der Zugriff erfolgt dann über die Struktur
„Modulname“.“Filename“.“Funktionsname“. Obwohl sich das File
„sub2.py“ im gleichen Modul befindet wie
„sub1.py“, muss der komplette Modulname hinterlegt werden. Man kann dies durch die Anpassung von
sys.path etwas effizienter gestalten, indem bei Programmstart die entscheidenden Verzeichnisse eingetragen werden.
Wenn wir das Programm starten, erhalten wir wieder die korrekten Summationsergebnisse. Nun kann man in Python den Import so gestalten,
dass der komplette Modulpfad beim Funktionsaufruf nicht eingetragen werden muss, was die Nutzung natürlich vereinfacht, sofern die
Funktionsnamen über alle importierten Module eindeutig sind:
Listing 65: Import mit "from"
In JavaScript müssen wir dieses Thema in zwei Teile zerlegen. Wenn wir JavaScript im Kontext von HTML Seiten nutzen, dann werden
meistens alle Files im
„<script>“ Tag hinterlegt:
Listing 66: Einbindung mehrerer JavaScript Files in HTML Seiten
Mehr haben die „Macher“ von JavaScript den HTML Programmierern erstmal nicht zugemutet. JavaScript kennt mit ES6 offiziell solche
Konzepte wie Module nicht. Dies ist insofern auch in gewissen Grenzen nachvollziehbar, da man in Webbrowsern im Regelfall einen
begrenzten Kontext hat. Wir werden aber gleich eine Ausnahme sehen.
In der node.js Programmierung geht man über
„exports“. Die Idee ist, dass die Submodule Funktionalitäten exportieren und so von außen zugänglich machen. Hierzu muss aber die
referenzierende Stelle die entsprechenden Files über
„require“ zugänglich machen:
Listing 67: Files in JavaScript unter node.js einbinden
Kurze Erklärung der Codezeilen: Die Einbindungen erfolgen über
require, wobei hier einfache oder doppelte Anführungszeichen verwendet werden können. Ausgegangen wird vom aktuellen Verzeichnis des
referenzierenden Files (wofür der
„.“ im Pfad steht). Wie in PHP werden die
„/“ Zeichen als Pfadtrenner genutzt. Das System kümmert sich darum, dass Doppelreferenzierungen nicht zu Problemen führen. Das
„require“ Statement liefert eine Referenz auf das entsprechende File, welche in einer Variablen abgelegt wird. Beim Zugriff auf die
Funktion muss dieser Variablenname, gefolgt von einem Punkt vor dem Funktionsaufruf stehen. Dadurch umgeht man Probleme mit doppelten
Funktionsnamen aus verschiedenen Files. Die exportierenden Files müssen die Funktionen explizit „exportieren“, was mit
„exports.“, gefolgt vom Funktionsnamen durchgeführt wird. Diesem Konstrukt wird dann die (anonyme) Funktion zugewiesen. Dadurch kann der
Autor der referenzierten Datei festlegen, welche Funktionen von außen nutzbar sein sollen und welche nicht.
Ich möchte an dieser Stelle nicht zu tief in das Räderwerk der
node.js Modulstruktur eintauchen. Trotzdem will ich noch eine Syntaxvariante zeigen, welche relativ häufig genutzt
wird. In node.js wird jedes File als
„module“ angesehen, welches wiederum eine
„exports“ Eigenschaft besitzt. Über diese Eigenschaft erkennt der
require Befehl, was er aus dem referenzierten File übernehmen kann oder soll. Wenn wir nun nur eine einzige
Funktion (oder alternativ auch ein einziges Objekt) exportieren wollen, dann können wir dies auch über den Syntax
module.exports durchführen und müssen dadurch dem exportierten Element keinen eigenen Namen geben. Sehen wir uns
das in einem Listing nochmal an, indem wir
sub2.js und
main.js anpassen. Um die Flexibilität von „Funktionen als First Class Citizens“ nochmal darzulegen, habe ich hier
zusätzlich nochmal
sub1.js angepasst.
Listing 68: Files über module in JavaScript unter node.js einbinden
Kurze Erklärung der Codezeilen: Beginnen wir mit
sub1.js. Hier habe ich die zu exportierende Funktion zuerst unter dem Namen
mySumFunction erzeugt und erst anschließend unter dem Namen
doSum exportiert.
In sub2.js habe ich nun über module.exports die Summenfunktion ohne Namen direkt exportiert. Dadurch kann ich nun in der main.js direkt mit s2(3, 4) den Aufruf durchführen – die Variable s2 wird also zur exportierten Funktion.
In sub2.js habe ich nun über module.exports die Summenfunktion ohne Namen direkt exportiert. Dadurch kann ich nun in der main.js direkt mit s2(3, 4) den Aufruf durchführen – die Variable s2 wird also zur exportierten Funktion.
Eine Anmerkung sei bei der Nutzung von JavaScript auf dem Browser aber noch gemacht. Seit ES6 gibt es die Möglichkeit, Module zu verwenden. Dies ist
Stand 2022 zwar „nur“ ein Proposal, wird aber von fast allen JavaScript Interpretern unterstützt. Die Idee ist, einzelne Funktionsblöcke
als „Module“ zu kapseln, welche als Ganzes importiert werden können. Die Einbindung von Modulen erfolgt im Browser über die
type Eigenschaft des
script Tags:
Listing 69: Moduleinbindung in JavaScript für Browser
Hier noch eine kleine Anmerkung für den Beispielcode in https://github.com/maikaicher/book1.
Die HTML-Seite kann nur über einen Webserver ausprobiert werden, da sonst die Sicherheitsfeatures des Browsers die
Ausführung blockieren.
Für node.js nutzt man entweder anstatt
„js“ Files nun
„*.mjs“ oder man schaltet diese Funktionalität zentral frei. Hierfür wird ein eigenes File für die Zusammenstellung der
Projekteigenschaften benötigt. Solche Files nennt man auch „Manifest“ Files. Für Node.js lautet es
package.json und ist im Prinzip das Konfigurationsfile des Node Package Managers „npm“. Es würde an dieser Stelle zu weit führen,
dieses Konzept näher zu beleuchten, insofern reduziere ich es an dieser Stelle auf das Konzept der Module. Hierfür erzeugen wir ein
File namens
package.json und tragen lediglich folgenden Inhalt ein:
Listing 70: package.json mit Freischaltung von Modulen
Eine weitere Möglichkeit dieses File zu erzeugen ist über den
npm init Befehl. Diesen gibt man über die Konsole ein und folgt dem Konsolendialog. Dieses File muss anschließend noch um den
Text aus Listing 70 erweitert werden. Wenn dies erfolgt ist, dann sieht der
Export wie folgt aus:
Listing 71: Export als Modul
Und der dazu passende Import:
Listing 72: Import von Modulen
Wenn man den Alias (also
„as myDoSum“) weglässt, dann ruft man die Funktion mit dem ursprünglichen Namen
„doSum“ auf. Der Vorteil ist nun, dass man mehrere Elemente exportieren kann und nur einen
import hierfür benötigt:
Listing 73: Export mehrerer Funktionen als Modul
Und der dazu passende Import:
Listing 74: Import von Modulen mit mehreren Funktionen
Den letzten Punkt, den wir bei Skriptsprachen besprechen müssen, ist das Speichermanagement. Wie man bereits vermuten kann,
versteckten Skriptsprachen das Speichermanagement komplett vor dem Programmierer. Er hat, ähnlich wie in Java, keinen wirklichen
Einfluss darauf, was im Heap und was im Stack landet und schon gar nicht, wie der Speicherplatz wieder freigegeben wird. Das hat
im Wesentlichen zwei Gründe. Das Ziel von Skriptsprachen war ja, die Arbeit des Programmierers möglichst zu vereinfachen. Es wäre
somit kontraproduktiv, dem Programmierer das Speichermanagement aufzubürden. Der zweite, wahrscheinlich wichtigere Grund ist, dass
zwischen dem von uns geschriebenen Code und dem System – bestehend aus Prozessor, Speicher und Betriebssystem – die Laufzeitumgebung
mit dem Interpreter sitzt und dessen Speicherverwaltung erstmal intern gelöst werden muss. Die meisten Laufzeitumgebungen sind
selbst in C++ geschrieben, wo man sich ja selbst um das Speichermanagement kümmern muss. In diesem Zusammenhang konnte man sich
auch gleich um das Managen des Speichers für den interpretierten Code kümmern. Die Notwendigkeit der Laufzeitumgebung haben wir bei
Java und C# auch, weshalb sich Java Entwickler ähnlich „wenig“ Gedanken über das Speichermanagement machen müssen wie
Skriptsprachenprogrammierer.
An dieser Stelle möchte ich nochmal kurz auf die „Grabenkämpfe“ von ambitionierten Skriptsprachenentwicklern versus ambitionierten
C++ Entwicklern zu sprechen kommen. Ist der Ansatz von Skriptsprachen, dass der Rechner sich um Datentypen und der Garbage collection
kümmert, nun besser oder schlechter als sich um alles selbst zu kümmern? Eine sinnvolle Antwort auf diese Frage gibt es nicht, da die
Frage als solches schon falsch ist. Es wäre genauso töricht zu fragen, ob in einem Auto ABS jetzt gut ist oder nicht. Für den normalen
Privatfahrer ist es auf jeden Fall sinnvoll, sich ein Fahrzeug mit ABS zu kaufen. Allerdings wird es keinen professionellen Rallyefahrer
geben, der sich ernsthaft ABS in sein Rennauto bauen lässt. Es kommt wie immer auf den Anwendungsfall an.

CC Lizenz (BY NC SA)