
Objektorientierung – wir modellieren die Welt
Wir haben in den letzten Kapiteln schon sehr viel von Objekten und Klassen gelesen, ohne aber explizit darauf einzugehen, was „Objektorientierung“ eigentlich ist.
Dies werde ich in diesem Kapitel nachholen. Bis jetzt haben wir keinen objektorientierten, sondern einen prozeduralen Ansatz bei unseren kleinen Testprogrammen
verfolgt. Dieser Ansatz kommt dem internen Ablauf unseres Prozessors – also dem Maschinencode – prinzipiell am nächsten. Dieser Ansatz bringt aber ein Problem bei
bestimmten Programmieraufgaben mit sich.

Das prozedurale Problem
Gehen wir mal davon aus, wir wollen einen Getränkeautomaten simulieren. Unser Getränkeautomat soll sehr vereinfacht aufgebaut sein, so dass wir nur drei verschiedene
Getränkedosen aus dem Automaten entnehmen können – Cola, Limonade und Wasser und alle sollen gleich viel kosten, nämlich 1 EUR:
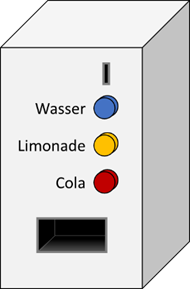
Abb.: 1: Modell Getränkeautomat
Der Getränkeautomat hat nun zwei Eingangsgrößen – das Geld und die Information über den Knopfdruck. Für unser Modellprogramm definieren wir einfach die Auswahl mit
Zahlen. 0 steht für Wasser, 1 für Limonade und 2 für Cola. Wenn wir 1 EUR einwerfen und einen der drei Knöpfe drücken, kommt eine Dose des gewählten Getränks heraus.
Wenn wir zu viel oder zu wenig Geld einwerfen und einen Knopf drücken, bekommen wir einfach das Geld wieder zurück. Dies ist eigentlich ein recht einfacher
Algorithmus, der aus Struktogrammsicht wie folgt aussieht:
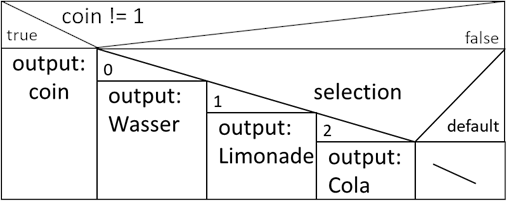
Abb.: 2: Modellhafter Algorithmus des Getränkeautomaten
Wir gehen hier einfach davon aus, dass wir nur die Werte 0, 1 oder 2 bei der Auswahl erhalten können und wir somit auch kein Errorhandling diesbezüglich benötigen.
Dies ist deshalb tragbar, da der Automat ja auch nur drei Knöpfe hat – es gibt also keine Möglichkeit einen anderen Knopf außer 0, 1 oder 2 zu betätigen. Nachdem wir
den Algorithmus nun erstmal prozedural umsetzen wollen, nutzen wir die einzige bis dato besprochene rein prozedurale Programmiersprache, nämlich C:
Listing 1: Prozedurale Umsetzung des Getränkeautomaten in C
Kurze Erklärung der Codezeilen: Das Unterprogramm wird als erstes definiert. Der Rückgabewert soll ein Text sein, weshalb wir hier einen Pointer auf das erste
char Zeichen des Textes zurückgeben. Die Parameter sind wie beschrieben der ausgewählte Typ
"selection" und das Geld
("coin"). Der Speicherbereich des Rückgabestrings muss zuerst über
malloc() reserviert werden, da wir den String außerhalb des Unterprogramms weiterverarbeiten (sprich ausgeben) wollen. Danach folgen die Prüfungen entsprechend des
Struktogramms. Die Konvertierung einer Zahl in einen String (also für die Rückgabe des nicht passenden Geldbetrages) können wir in C über
sprintf realisieren. Diese Funktion funktioniert wie
printf, lediglich wird nicht auf die Konsole geschrieben, sondern in einen String (als
char*). Die Konstantwerte für die Texte „Wasser“, „Limonade“ und „Cola“ werden über
strcpy in den
output String übernommen. Der Aufruf in der Main-Funktion erwartet nun die Parameter für den gewählten Getränketyp und den eingeworfenen Geldbetrag. Am Ende geben
wir den reservierten Speicherplatz wieder mit
free() wieder frei.
Wenn wir das Programm starten, sehen wir den korrekten Wert:
Leider hat unser Programm einen kleinen Makel im Vergleich zu einem realen Getränkeautomaten. Wenn wir unsere Main-Funktion wie folgt anpassen:
Listing 2: Zyklischer Aufruf des Getränkeautomaten in C
sollte uns das Problem klar werden. Wir können streng genommen unendlich viele Getränkedosen entnehmen – unser Automat wird niemals leer. Dieses Manko können wir
nun über zwei Wege korrigieren. Der erste wäre über eine globale Variable, in der wir den Füllstand unser drei verschiedenen Getränkesorten vorhalten. Hierzu
erzeugen wir ein Array, welches auf Position 0 den Füllstand von Wasser, auf 1 den von Limonade und auf 2 den von Cola hinterlegt. Wenn wir nun ein Getränk wählen,
welches ausverkauft ist – also an der entsprechenden Position die 0 steht, dann soll eine Meldung samt Geld herausgegeben werden. Passen wir also erstmal unser
Struktogramm entsprechend an.
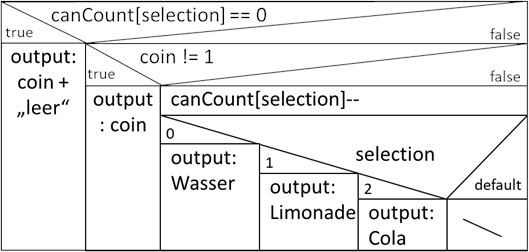
Abb.: 3: Modell Getränkeautomat mit Füllstandsprüfung
Auch hier verzichten wir auf die Überprüfung, ob die Auswahl eventuell außerhalb der Wertemenge 0 bis 2 ist. Dies wäre nun der zugehörige Code:
Listing 3: Zyklischer Aufruf des Getränkeautomaten in C inklusive Füllstandsprüfung
Der Code dürfte soweit inzwischen selbsterklärend sein. Wenn wir ihn laufen lassen sehen wir, dass nach 29 Aufrufen die Ausgabe nur noch
Rueckgabe: 1.000000 leer ist. Insofern haben wir das Problem zwar in den Griff bekommen, es ist aber nicht wirklich „schön“. Der Grund liegt darin,
dass wenn wir nun zwei Getränkeautomaten mit unserem Code realisieren wollen, wir nun zwei globale Arrays (
fuellstand0 und
fuellstand1) erzeugen müssen und die Funktion
getCan ebenfalls doppelt auslegen, um in dem einen Programm auf
fuellstand0 und in dem anderen auf
fuellstand1 zuzugreifen. Alternativ könnten wir ein zweidimensionales Array anlegen und mit Hilfe eines weiteren Parameters dem Programm sagen,
um welchen Automaten es sich handelt:
Listing 4: Ergänzung um zweiten Getränkeautomaten
Grundsätzlich wäre dies eine umsetzbare Lösung, wenngleich es nicht wirklich ein zufriedenstellender Weg wäre – da wir die Daten der verschiedenen Automaten in einem Array
kombinieren würden. Stellen wir uns vor, die beiden Automaten sollen unabhängig voneinander betrieben werden. Wir fügen also Daten zusammen, die eventuell nicht zusammengehören.
Eine mögliche weitere Alternative wäre, pro Automaten ein Array zu erstellen und dieses dann über die Parameterliste zu übergeben. Dadurch würde die
„getCan“ Funktion zustandslos werden – sprich alle notwendigen Informationen werden ausschließlich über die Parameterliste übergeben. Das Programm hätte dann in etwa folgende Form:
Listing 5: Zwei Getränkeautomaten mit stateless Unterprogramm
Mit dieser Lösung haben wir also die Möglichkeit, die Daten der beiden Getränkeautomaten unabhängig voneinander zu verwalten. Es bleibt aber ein Manko, welches wir mit prozeduralen
Programmieransätzen nicht loswerden können – die Trennung von Funktion und Daten. Ein realer Getränkeautomat ist nicht ein Gerät mit Funktion oder ein Gerät mit Getränkedosenspeicher,
sondern beides. Er hat die Funktionalität der Getränkeausgabe basierend auf den Eingabewerten und er hat intern den Speicher für die Getränkedosen. In unserem prozeduralen Code ist
dies aber strikt getrennt. Die liegt daran, dass die Variablen, welche innerhalb der Unterprogramme deklariert und initialisiert wurden ungültig werden, sobald das Unterprogramm abgearbeitet
wurde. Wir müssen die Variablen also zwingend außerhalb der Unterprogramme erzeugen. Die Welt um uns herum ist jedoch anders aufgebaut. Objekte sind im Regelfall Konstrukte mit Speichern und
Funktionalität. Und genau an dieser Stelle setzt die objektorientierte Programmierung an. Ein Objekt einer objektorientierten Programmiersprache hat ebenfalls diese beiden Dimensionen – es
hat Speichermöglichkeiten und Funktionalität. Da C nun keine objektorientierte Sprache ist, schwenken wir für die nächsten Gedankengänge auf eine andere Programmiersprache um. Im Prinzip
ist es nun egal, welche wir verwenden. Ich habe mich hier aber für Java entschieden, da Java die Konzepte ohne große Umschweife implementiert. Am Ende des Kapitels werde ich aber für die
einzelnen Konzepte der Objektorientierung die Syntaxvarianten der anderen Sprachen C++, C#, JavaScript, PHP und Python ansprechen.
Den Code entwickle ich hier zwar in Java, ich werde die wesentlichen Elemente aber in allen Sprachen unter
https://github.com/maikaicher/book1 zur Verfügung stellen.
Zusammenschluss von Daten und Funktionalität
Beginnen wir mit der Umsetzung unseres Getränkeautomaten in objektorientierter programmierweise. Wir müssen an dieser Stelle noch nicht alles verstehen – wir sollen lediglich eine Idee bekommen,
was hinter dem objektorientierten Ansatz steckt. Sehen wir uns den Code in Java an, welcher die Funktionalität in einer Klasse realisiert. Java verlangt, dass jede Klasse in einem eignen File liegt
(Ausnahmen wären hier „nested Classes“, was hier aber erstmal keine Rolle spielt). Für unser Programm benötigen wir also nun zwei Files – eines für die Klasse des Getränkeautomaten und eines für das
Hauptprogramm:
Listing 6: Klasse für Getränkeautomat
Kurze Erklärung der Codezeilen: Dieser Code kapselt die gesamte Funktionalität eines Getränkeautomaten, so wie wir ihn designed haben, in einem File zusammen. Die Details der einzelnen objektorientierten
Elemente werden wir später genauer ansehen. Soviel sei vorab gesagt – das Array für den Füllstand der drei Getränketypen befindet sich jetzt nicht mehr im Hauptprogramm, sondern in der Klasse bzw. eigentlich
dem Objekt. Die Funktionalität der
getCan() Methode ist in der Lage, auf dieses Array zuzugreifen. Die Methode
VendingMachine() mit dem Arrayparameter ist dafür zuständig, bei Erzeugung des Objektes die initialen Füllstandswerte zu übernehmen – man nennt diese Methode den „Konstruktor“.
Sehen wir uns nun die Nutzung dieser Klasse im Rahmen des Hauptprogramms mal an:
Listing 7: Nutzung des Getränkeautomaten als Objekt
Kurze Erklärung der Codezeilen: Wir erzeugen aus der Klassendefinition nun zwei unterschiedliche Objektinstanzen (oft kurz „Objekte“ genannt),
g0 und
g1. Dies sind die beiden Getränkeautomaten. Bei der Erzeugung übergeben wir ein neu erzeugtes
int Array mit den Füllstandsinformationen. Danach laufen wir 100 mal durch die Schleife und wählen mit der 1 die Limonade und übergeben den korrekten Betrag von 1.0.
Wie wir sehen, sind die Funktionalitäten, welche ausschließlich den Getränkeautomaten betreffen, nun in der Klasse
VendingMachine hinterlegt. Die Mainmethode nutzt somit lediglich die Methoden des Objektes, um mit ihm zu arbeiten. Mit Hilfe des Punktoperators greifen wir pro Objekt auf die dort
liegenden Methoden zu. Die Idee, Daten wie die Füllstände und die Funktionen wie das Entnehmen von Dosen in einem Konstrukt zu verbinden, bietet uns aus Sicht der Nutzung nun den
Vorteil der Übersichtlichkeit. Die für uns hier also wichtigste Erkenntnis ist somit:
- Objekte haben Eigenschaften
- Objekte haben Funktionalitäten
Klasse – ein Plan mit Hierarchie
Nun wollen wir diese Grundidee, die Welt in einer objektorientierten Sprache zu modellieren, noch einen Schritt weiterführen. In den vorausgegangenen Absätzen wurde immer von „Objekten“ und von
„Klassen“ gesprochen. Diesen Unterschied müssen wir jetzt erst einmal klären, da er essenziell für das Verständnis dieses Programmierkonzeptes ist. Am besten vergleicht man ein Objekt mit einem Haus
und eine Klasse mit dem zugehörigen Plan. Der Plan legt exakt fest, welche Eigenschaften und Funktionalitäten ein Haus haben muss. Das Objekt wiederum ist die Umsetzung des Plans.
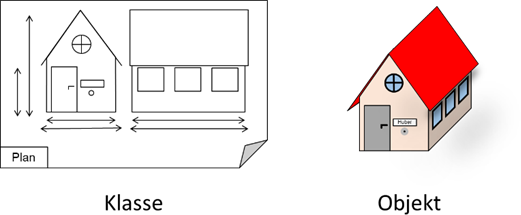
Abb.: 4: Klasse vs. Objekt am Beispiel eines Hauses
Man sagt auch, dass man durch die „Instanziierung“ einer Klasse das Objekt erzeugt, weshalb Objekte auch als „Objektinstanzen“ bezeichnet werden. Wir werden dieses Bild des Plans und des Hauses noch
öfter bemühen müssen, um die Konsequenzen mancher Konzepte besser zu verstehen. Das erste wichtige Detail ist, dass wir basierend auf einem Plan beliebig viele Häuser „bauen“ können. Genau dies haben
wir ja auch mit unseren Getränkeautomaten gemacht – wir hatten eine Klasse
VendingMachine und haben mit
g0 und
g1 zwei Instanzen dieser Klasse erstellt. Weiterhin haben wir gesehen, dass die Objekte unabhängig voneinander sind. Die beiden Getränkeautomaten-Objekte hatten für die drei Getränkekategorien
unterschiedliche Füllstände. Gleiches gilt für die Häuser – sie sollten bspw. die Möglichkeit haben, unterschiedliche Werte für die Türnamensschilder zu akzeptieren. Nun, wenn wir jetzt die
Klasse als den „Plan“ unserer Objekte identifiziert haben, dann wird unser
Listing 6 somit zum Plan. Wir können die Klasse also in Form des Codes – oder auch des Kompilierergebnisses auf unserer Festplatte als Datei „sehen“. Die Frage ist jetzt, wo können wir jetzt
unser Objekt „ansehen“? Die Antwort ist: nirgends! Das Objekt befindet sich in unserem Speicher – im Heap, bzw. während der Verarbeitung sind die Methoden im Stack. Sie existieren also nur zur
Laufzeit. Wir beschäftigen uns also beim Programmieren ausschließlich mit den Klassen und die Objekte entstehen erst dann, wenn unsere Programme laufen. Die nächste zu klärende Frage wäre,
warum man die Klassen jetzt „Klassen“ und nicht etwa „Pläne“ getauft hat. Wenn wir schon Pläne schreiben, warum nennen wir es nicht so? Hier kommt nun das nächste Konzept der Objektorientierung zum
Tragen, die Vererbung.
Nehmen wir an, wir wollen ein Grafikprogramm realisieren. Hierzu möchten wir gerne unterschiedliche Grafikelemente verwalten:
- Linie
- Rechteck
- Kreis
- Quader
- Kegel
| Linie: | Rechteck: | Kreis: | Würfel: | Kegel: | |
|---|---|---|---|---|---|
| Randfarbe | X | X | X | X | X |
| Füllfarbe | X | X | X | X | |
| Umfang | X | X | |||
| Fläche | X | X | X | X | |
| Volumen | X | X | |||
| Länge | X | ||||
| Rechtecklänge | X | X | |||
| Rechteckbreite | X | X | |||
| Kreisradius | X | ||||
| Kantenlänge | X | ||||
| Grunddurchmesser | X | ||||
| Spitzenhöhe | X |
Tabelle 1: Eigenschaften von Grafikelementen
Die ersten fünf Eigenschaften gelten jeweils für mehrere Elemente. So können wir beispielsweise die Randfarbe bei allen Elementen feststellen, einen Umfang besitzen jedoch
nur die zweidimensionalen Elemente. Dies bedeutet also, dass wir die einzelnen Elemente nach deren Eigenschaften „klassifizieren“ können. Beispielsweise können wir sagen,
dass alle fünf Elemente zur Klasse der Grafikelemente gehören. Das Rechteck und der Kreis gehören zur Klasse der ZweiDElm, der Würfel und der Kegel zu den DreiDElm.
Diese Klassenstruktur lässt sich auch grafisch darstellen:
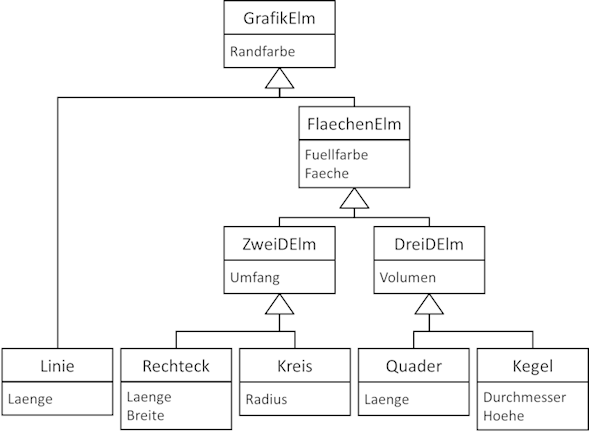
Abb.: 5: Vereinfachtes Klassendiagramm Grafikelemente
Das Diagramm ist in unserem Fall so gestaltet, dass die allgemeineren Klassen oben stehen. Das muss zwar nicht zwingend so sein, da die Pfeile die Richtung bestimmen, es ist
aber üblich die Pfeile von unten nach oben zeigen zu lassen. Bis auf die oberste Klasse können wir also bei allen eine Klasse identifizieren, welche darübersteht. Dies sind die
„Elternklassen“. Jede Eigenschaft, die eine Elternklasse besitzt, geht automatisch auf die Kindklasse über. Dadurch haben wir nicht mehr die Notwendigkeit, beispielsweise in der
Quader Klasse eine Variable für die Volumen-, Flächen-, Füllfarben- und Randfarbeinformationen zu implementieren. Dieses Phänomen nennt man „Vererben“ – die Elternklassen vererben
ihre Eigenschaften und Methoden an die Kindklassen. Aus Sicht der Kindklassen bezeichnet man diesen Vorgang „Erweitern“ – eine Kindklasse erweitert die Methoden und Eigenschaften der
Elternklasse um neue Methoden bzw. Eigenschaften. In unserem Diagramm finden wir nun immer nur eine Elternklasse pro Kindklasse – es handelt sich hier um „Einfachvererbungen“. Die
meisten objektorientierten Programmiersprachen unterstützen nur diese Einfachvererbung. C++ und Python hingegen erlauben mehrere Elternklassen pro Kindklasse, was wir als „Mehrfachvererbung“
bezeichnen. Hiermit sollte man eher vorsichtig sein, da sich die Komplexität und vor allem auch die Gefahr von Konflikten im Vergleich zu Einfachvererbungen erheblich erhöht.
Wir können nun eine beliebige Klasse nehmen, welche aus unserer Sicht sinnvolle Eigenschaften und Methoden aufweist. Diese können wir dann mit eigenen, neuen Eigenschaften und Methoden
ergänzen. Angenommen, jemand hat die „ZweiDElm“ Klasse bereits geschrieben und wir möchten diese Funktionalitäten für unsere Rechteck Klasse nutzen. Wir nehmen somit einfach diese ZweiDElm
Klasse und erweitern sie in der Kindklasse „Rechteck“. Hier sehen wir, dass der Begriff „Erweitern“ eigentlich sinnvoller als „Vererben“ ist, da dies der wesentliche Vorgang ist, den wir beim
Programmieren verfolgen. Wenn jemand eine Klasse geschrieben hat, muss er dies nicht zwangsläufig mit der Option der „Vererbung“ gemacht haben. Erst wenn ein Programmierer den Funktionsumfang
der Klasse zwar als sinnvoll, nicht aber als ausreichend ansieht, wird er davon eine Kindklasse erstellen. Nun wird erst klar, dass hier eine Vererbung – oder eben Erweiterung – stattfindet.
Dies erklärt auch, warum in dem Diagramm aus
Abbildung 5 die Zuordnungspfeile von der Kind- zur Elternklasse führen – man nenn diese Pfeile somit auch „Erweiterungspfeile“. In Programmiersprachen wie Java führt auch das Schlüsselwort
„extends“ zu einer entsprechenden Vererbung/Erweiterung von Klassen. Wenn man allerdings nicht möchte, dass seine Klasse von anderen Klassen erweitert wird, kann man dies mit entsprechenden
Schlüsselwörtern auch verhindern – man „versiegelt“ die Klasse. Wir werden die einzelnen Codefragmente hierfür gleich kennenlernen. Nun ist aber das Diagramm streng genommen nicht vollständig. Es fehlt
„die Mutter aller Klassen“ – also die Elternklasse, von der jedes Objekt erbt, was aber keine expliziten Vorfahren hat – in unserem Fall müssten wir eigentlich die diese „Urklasse“ als Elternklasse
bei GrafikElm ergänzen. Diese erbt ohne unser Zutun automatisch von dieser „Urklasse“. In Java ist dies die Klasse
„Object“. Jede Klasse weist also die Eigenschaften und Methoden der Klasse
„Object“ auf. Da aber grundsätzlich
„Object“ der Urvorfahre aller Klassen ist, wird sie nicht in den Diagrammen eingezeichnet.
Zugriffsmodifikatoren
Der nächste Punkt ist die Frage ob es sinnvoll ist, dass sämtliche Eigenschaften und Methoden, welche innerhalb von Klassen existieren, von außen abgreifbar sein sollen. Möchten wir beispielsweise
interne Hilfsprogramme, welche zur sauberen Strukturierung von Code notwendig sind, aber für außenstehende Nutzer der Klassen irrelevant oder gar verwirrend sind, allen Nutzern der Klasse zugänglich
machen? Das wäre so, als würden wir in einem Auto jeden Schalter, jede Stellschraube, alle Sicherungen, jeden Einfüllstutzen für alle möglichen Flüssigkeiten rund um den Fahrer platzieren – insofern
können wir die Frage mit „nein“ beantworten, da das Ganze dann viel zu unübersichtlich wird. Wir wollen als Programmierer also die Kontrolle darüber haben, wer welche Eigenschaften und Methoden unserer
Klassen nutzen kann. Hier hilft uns die „Sichtbarkeit“ von Variablen und Methoden weiter, die im Englischen „Access Modifier“ genannt werden. Diese kontrollieren die Zugriffe basierend auf den aktuellen
Nutzerbereich des Zugreifenden. Im Wesentlichen gibt es vier verschiedene Nutzerbereiche von Klassen. Um diese zu verstehen, sehen wir uns folgende Situation an:
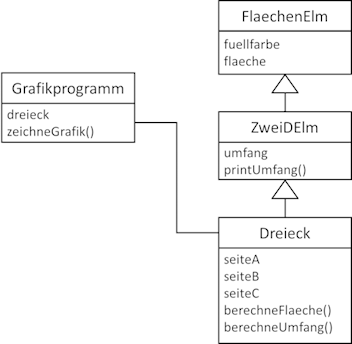
Abb.: 6: Nutzung einer Klasse
Wir haben die Anforderung, unser Klassendiagram um eine Dreiecksklasse zu erweitern und es im Rahmen eines Grafikprogramms zu nutzen (was durch den Strich, genannt „Assoziation“ zwischen Grafikprogramm und
Dreieck symbolisiert wird). Insofern können wir aus Sicht der existierenden Klassen „Dreieck“ und „ZweiDElm“ drei Bereiche definieren, in denen wir Methoden finden können:
- Alle Methoden der eigenen Klasse, bspw. „printUmfang()“ der Klasse „ZweiDElm“.
- Alle Methoden der „Nachfahren“, bspw. „berechneFlaeche()“ der Klasse „Dreieck“ aus Sicht von „ZweiDElm“.
- Alle Methoden außerhalb des Vererbungsbaumens, bspw. „zeichneGrafik()“.
- Alle Methoden, welche im gleichen Paket zusammengefasst wurden.
Diese Zugriffsbereiche haben in den objektorientierten Programmiersprachen eigene Namen bekommen:
| Bezeichnung: | Bedeutung: | Diagrammsymbol: |
|---|---|---|
| public | Jeder, der eine Referenz auf das Objekt besitzt darf zugreifen. | + |
| private | Nur das eigene Objekt darf auf zugreifen | - |
| protedted | Nur die Nachfahren dürfen zugreifen. | # |
| package | Alle Klassen des aktuellen Pakets (oder Assembly) dürfen zugreifen. | ~ |
Tabelle 2: Access Modifier
Wenn wir dieses Wissen nun auf unsere Klassen anwenden, dann wäre bspw. die Methode "berechneFlaeche()"" private, die Variable "Flaeche" protected und die Variable "Fuellfarbe" public. Sammeln wir
nun mal die Access Modifier der einzelnen objektorientierten Programmiersprachen:
| Gleiches Paket: | Anderes Paket: | ||||||
|---|---|---|---|---|---|---|---|
| Nutzbar innerhalb: | Klasse | Kind- klasse |
Fremd- klasse |
Kind- klasse |
Fremd- klasse |
||
| Modifier: | Keyword(1): | ||||||
| Java | private | private | X | ||||
| package | X | X | X | ||||
| protected | protected | X | X | X | X | ||
| public | public | X | X | X | X | X | |
| C# | private | Private | X | ||||
| package | Internal | X | X | X | |||
| protected | Private Protected | X | X | ||||
| Protected | X | X | X | ||||
| Protected Internal/span> | X | X | X | X | |||
| public | Public | X | X | X | X | X | |
| C++ | private | private | X | ||||
| protected | protected | X | X | ||||
| public | public | X | X | X | |||
| Python | private | __myVariable(2) | X | ||||
| protected | _myVariable(2) | X | X | X | |||
| public | public | X | X | X | X | X | |
| PHP | private | private | X | ||||
| protected | protected | X | X | ||||
| public | public | X | X | X | |||
| JavaScript | private | private | X | ||||
| public | public | X | X | X | |||
Tabelle 3: Access Modifier und Auswirkungen der einzelnen Programmiersprachen
(1) Leer: Defaulteinstellung - also ohne zusätzliches Keyword
(2) Nur Konvention – also ein unverbindlicher Hinweis an andere Programmierer. Privater und protected Zugriff von außen ist nach wie vor möglich. Details finden sich weiter unten.
(2) Nur Konvention – also ein unverbindlicher Hinweis an andere Programmierer. Privater und protected Zugriff von außen ist nach wie vor möglich. Details finden sich weiter unten.
Da C++ und PHP keine Packages kennen, sind die entsprechenden Felder leer.
Konstruktoren - Bob der Baumeister
Was uns in unserem kleinen Grafikprojekt jetzt noch fehlt, ist der Konstruktor. Dies ist eine Methode, welche immer dann aufgerufen wird, wenn wir aus einer Klasse ein Objekt erstellen wollen.
Bleiben wir kurz bei unserem Dreieck. Wenn wir ein Dreiecksobjekt erstellen wollen, benötigen wir die Informationen über die drei Seiten A, B und C. Ohne diese Information können wir mit unserem
Dreiecksobjekt nichts anfangen. Wir haben also die Notwendigkeit, bei der Erzeugung von dem Nutzer unserer Klasse zwingend abzufragen, wie die Werte für die drei Seiten sind. Dieses Abfragen
übernimmt der Konstruktor. Wir haben in den oberen Kapiteln schon öfter Objekte erzeugt und haben dort mehr oder weniger bewusst den Konstruktor genutzt. In den allermeisten Programmiersprachen
rufen wir den Konstruktor auf, indem wir den Klassennamen verwenden. Wenn also unsere Klasse „Dreieck“ heißt, dann heißt der Konstruktor
„Dreieck()“. Wir werden sehen, dass in den meisten anderen Programmiersprachen (und somit auch Java) nicht nur der Konstruktoraufruf dem Klassennamen entspricht, sondern auch die Definition der
Konstruktormethode im Code so heißt wie die Klasse, was ja auch intuitiv sinnvoll ist, aber nicht bei allen Programmiersrpachen so gehandhabt wird. Ausnahmen hier bilden bspw. Python und PHP.
Meist wird vor dem Konstruktor noch das Schlüsselwort
„new“ benötigt. Bevor wir uns nun in den Code stürzen, benötigen wir noch eine allgemeine Überlegung zum Thema „Dreiecke“. Ein Dreieck, das wir über die drei Seiten bestimmen, darf nicht mit
beliebigen Seitenlängen belegt werden. Wenn eine Länge A = 3, Länge B = 4 und Länge C = 5 ist, haben wir kein Problem. Erhöhen wir aber bspw. die Länge C so, dass sie größer oder gleich der
Summe von A und B ist, können wir kein Dreieck mehr zeichnen:
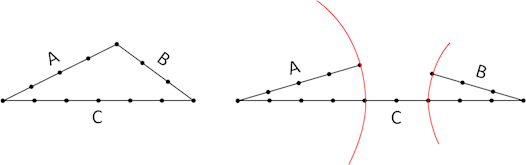
Abb.: 7: Mögliches und unmögliches Dreieck
Wir müssen also vor der Belegung der Werte im Konstruktor prüfen, ob die Werte überhaupt sinnvoll sind. Die Frage ist aber, was wir dann tun. In einem späteren Kapitel werde ich auf die Fehlerbehandlung
mittels Exceptions eingehen – bis dahin müssen wir uns anders behelfen. Wir belegen einfach die Instanzvariablen der drei Seiten mit einem sinnvollen Wert, bspw. jeweils die 1. Wenn die über den Konstruktor
übergebenen Werte sinnvoll sind, dann übernehmen wir sie, ansonsten belassen wir die ursprünglichen Werte. Diese Überprüfung lagern wir in eine eigene Methode aus, die wiederum private sein soll, da sie nur
für den internen Gebrauch innerhalb des Dreiecks bestimmt ist.
Schreiben wir also unsere Klassen – am Beispiel von Java. Wir erzeugen in VSCode erstmal ein package, namens
„mygraphs“. Hierzu gehen wir im VSCode Explorer auf den Bereich „JAVA PROJECTS“ und klicken hier mit der rechten Maustaste auf unser Projekt (Standard wäre hier der Name des Ordners, in dem sich das Paket
befindet) und wählen „New Package“ aus:
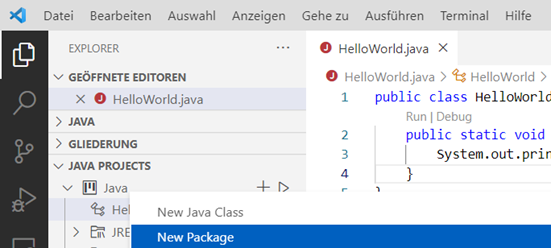
Abb.: 8: Erstellung eines Java Packages in VSCode
Danach erscheint das Package im Projekt:
{} mygraphs(3). Dadurch wird auch ein Unterordner auf dem Filesystem mit diesem Namen erzeugt. Mit dem + neben dem Package können wir jetzt die Klassen hinzufügen. Die Angabe des Packages wird dann
automatisch in das File eingefügt. Für unser Dreieck benötigen wir also nun eine eigene Klasse, welche die drei Werte für die drei Seiten A, B und C und die sonstigen Funktionalitäten vorhält.
Sehen wir uns den Code für die Klassen mal an. Hierbei finden wir in Java jede Klasse in einem eigenen
*.java File, welches den gleichen Namen wie die Klasse trägt. Die Klasse GrafikElm liegt also im File
GrafikElm.java:
(3) Wenn der Code innerhalb des Projektes in einem Unterordner liegt, so werden die darüberliegenden Ordner eben-falls in den Package-Namen aufgenommen
Listing 8: Klasse GrafikElm
Listing 9: Klasse FlaechenElm
Listing 10: Klasse ZweiDElm
Listing 11: Klasse Dreieck
Kurze Erklärung der Codezeilen: Die Klassen
GrafikElm,
FlaechenElm und
ZweiDElm sind in diesem Stand unseres Codes lediglich Behälter für Daten wie
fuellfarbe oder
flaeche, da wir hier (noch) keine Methoden eingebaut haben. Die beiden Farbwerte initialisieren wir gleich mit dem Wert 0.
FlaechenElm wird mit dem Schlüsselwort
„extends“ aus der Klasse
GrafikElm erzeugt – also erweitert
FleachenElm die Klasse
GrafikElm – in unserem Fall um die Eigenschaft
flaeche. Die Variable
randfarbe wird als
public deklariert und ist somit von außen zugreifbar. Die Variable
flaeche wiederum ist
protected, weshalb wir bei den Nachfahren darauf zugreifen können, nicht aber außerhalb des Vererbungsbaumes. Wir werden dies gleich bei der Nutzung im Rahmen des Hauptprogramms sehen. Die Klasse
Dreieck wiederum hat die drei Variablen für die Seitenlängen (welche wir gleich mit 1 belegen), die beiden Berechnungsmethoden, die Prüfmethode für die Längen und den Konstruktor. Hier fällt die
Verwendung des Schlüsselwortes
„final“ bei der Klassendefinition auf, wodurch wir verhindern, dass weitere Klassen von unserer Dreiecksklasse abgeleitet werden können. Solche Klassen nennen wir „versiegelt“. Im Konstruktor
sehen wir, dass er in Java genauso heißt wie die Klasse und dass er keinen Rückgabedatentypen aufweist. Dies ist nicht notwendig, da wir beim Konstruktoraufruf ohnehin nur das Objekt erwarten.
Die Werte der Parameterliste
a,
b und
c werden zuerst durch die
checkValues() Methode überprüft und bei korrekten Werten direkt in Seitenlängenvariablen übernommen. Die
checkValues() Methode prüft also lediglich, ob die Summe von zwei beliebigen Seiten nicht größer ist als die restliche Seite. Bei fehlerhaften Werten wird
false zurückgegeben, ansonsten
true. Man hätte die Methode auch einfacher gestalten können, indem wir nur eine Zeile hinterlegen:
return (a + b > c && b + c > a && c + a > b); wobei dies für manche als zu unübersichtlich empfunden wird, vor allem, wenn wir später noch zusätzlich eine Prüfung auf
negative Werte ergänzen würden. Nach der Zuweisung der Seiten im Konstruktor rufen wir dann die Generierung der Fläche auf, welche implizit auch den Umfang berechnet.
Hier sehen wir auch, dass wir eine Zugriffsmöglichkeit auf die Variablen
flaeche und
umfang haben, obwohl sie nicht in der Dreieck, sondern in der
FlaechenElm und
ZweiDElm Klasse definiert wurden.
Nun kommen wir auf das Hauptprogramm, die Klasse
Grafikprogramm, in dem die Main Methode liegt. Wir schreiben zu diesem Zeitpunkt natürlich nicht ein voll funktionsfähiges Grafikprogramm – wir wollen hier nur die Nutzung unserer
Klassen ausprobieren. Hierzu erzeugen wir im Package
„mygraphs“ die Klasse
Grafikprogramm. Im folgenden Code erzeugen wir einfach nur das Dreieck und geben dann testweise einige Daten aus um zu sehen, ob wir darauf zugreifen können und ob die Werte korrekt sind.
Listing 12: Klasse Grafikprogramm
Für den Start des Codes bleibt noch anzumerken, dass wir aus „Projektsicht“ in VSCode je nach Vorgehensweise noch ein kleines Problem haben. Es existieren eventuell mehrere Main Methoden. Diese sind aber der
Einstieg in unser Programm, weshalb VSCode mitunter nicht weiß, welche Klasse gestartet werden soll. Insofern kümmern wir uns darum, dass keine weitere Klasse mit der Main Methode existiert. In meinem Arbeitsbereich
würde bspw. noch
HelloWorld.java existieren, allerdings außerhalb des Packages
mygraphs. Insofern können wir diese Klasse einfach löschen. Aber Achtung – das geht natürlich nur dann, wenn es in dem gesamten Projekt auch wirklich nur eine Main-Methode geben soll. Dadurch, dass wir nun nicht
nur ein File kompilieren müssen, sondern 5, können wir nur über den CodeRunner gehen, wenn die Klasse Grafikprogramm gerade sichtbar ist. In größeren Projekten geht man üblicherweise über Hilfstools, wie bspw. Maven,
wo man diverse Abhängigkeiten hinterlegen und den Kompilierprozess steuern kann. Für kleinere Projekte ganz ohne Hilfsmittel können wir auch den manuellen weg gehen. Dies erledigen wir, indem wir im Terminal mit Hilfe
von
cd (also Change Directory) in den obersten Projektordner gehen und mit
javac alle Java Files dem Kompiler übergeben..
Danach kann das Programm manuell mint javac gestartet werden:
Der von VSCode erzeugte „Run“ Button direkt im Code oberhalb der Main-Methode macht diese Arbeit zwar obsolet (inklusive dem Entfernen von weiteren Main-Methoden) – es ist aber immer gut, wenn man versteht, was im Hintergrund
läuft. Ansonsten können wir auch den Startbutton rechts neben dem Projekt verwenden – hier wieder vorausgesetzt es existiert nur eine Main-Methode. Dadurch werden alle relevanten Files vor dem Ausführen kompiliert. VSCode müsste
dann in etwa wie folgt aussehen:
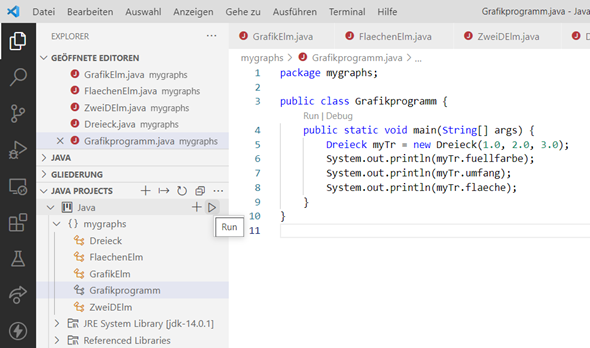
Abb.: 9: Java Projekt unseres Grafikprogramms
Wenn wir das Projekt nun starten, gibt das Programm folgenden Text aus:
Unser Programm funktioniert also. Nun wollen wir die Klasse
Grafikprogramm aus unserem Package herausnehmen. Hierzu erzeugen wir eine weitere Klasse
Grafikprogramm direkt auf Projektebene (durch einen Klick auf + neben „Java“) und fügen den folgenden Code ein:
Listing 13: Grafikprogramm außerhalb des Packages mygraphs
Kurze Erklärung der Codezeilen: Die Klasse ist nun nicht mehr im Package
mygraphs (in unserem Fall ist sie sogar in keinem Package mehr, weswegen die Angabe
package komplett fehlt). Damit wir nun aber auf unsere Klassen im Package
mygraphs überhaupt zugreifen können, benötigen wir den
import. Die beiden Zugriffe auf
umfang und
flaeche funktionieren jedoch nun nicht mehr, da sie aufgrund ihrer
„protected“ Eigenschaft außerhalb des Packages nur noch für direkte Erben zugreifbar wären. Aus diesem Grunde habe ich den Code mit einem Kommentarzeichen
// versehen – wir werden gleich testweise diese beiden Kommentarzeichen entfernen und sehen, was passiert.
Danach löschen wir das Grafikprogramm im Package
mygraphs und starten das Programm. Die Farbe wird wieder korrekt mit 0 angegeben. Wenn wir nun aber versuchen die beiden
// Zeichen zu entfernen, können wir das Programm nicht mehr starten. Die beiden Variablen
umfang und
flaeche sind rot unterstrichen, was in VSCode auf einen Fehler hinweist:
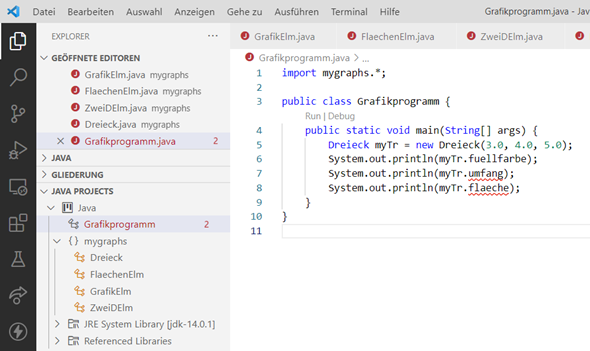
Abb.: 10: Zugriffsfehler bei protected Variablen außerhalb des Packages
Getter und Setter, denn Kontrolle ist alles
Jetzt mag mancher denken, dass es recht umständlich ist, die Sichtbarkeit möglichst klein zu halten. Warum machen wir nicht einfach alles
public und es gibt keinerlei Zugriffsprobleme mehr. Schließlich haben wir in unseren Klassen nichts zu verbergen! Die Antwort auf diese Frage lautet – ja, das ist eine Möglichkeit, aber es birgt auch eine Gefahr!
Beginnen wir mit dieser Gefahr und sehen uns danach die Ausnahmen an. Gehen wir mal davon aus, dass wir das Dreiecksobjekt nachträglich ändern wollen und ändern die Sichtbarkeit der drei Variablen für die Seite
A,
B und
C auf
public. Wir haben in unserem Code das Dreieck ja mit den Seitenlängen 3.0, 4.0 und 5.0 erzeugt. Sagen wir, das existierende Objekt soll nun auf die Längen 3.5 für die Seite
C angepasst werden. Da wir die drei Seitenvariablen (jetzt) als
public erzeugt haben, können wir dies relativ einfach:
Listing 14: Änderung der Seite C auf 3.5
So weit ist das alles problemlos, wir würden genau das gleiche machen, wie bei der initialen Erzeugung des Dreiecks mit den Werten 3.0, 4.0 und 3.5 – mit zwei Ausnahmen! Erstens haben wir nicht geprüft, ob die
Werte überhaupt ein sinnvolles Dreieck ergeben. Wir könnten also ohne Probleme die Werte 3.0, 4.0 und 9.0 hinterlegen, was kein Dreieck wäre. Und zweitens haben wir die Fläche und somit auch den Umfang nicht berechnet.
Wir müssen also irgendwie sicherstellen, dass das Unterprogramm
checkValues() ausgeführt wird und
berechneFlaeche(). Wir könnten dem Nutzer unserer Klasse dies per Manual mitteilen – aber ob er das liest, ist fraglich. Wir müssen den Nutzer also zwingen, den Wert über eine Methode zu setzen, in der wir unser
checkValues() und
berechneFlaeche() einbauen können. Dies heißt in der Konsequenz, dass wir den direkten Zugriff auf die Variable durch das Setzen von
private verhindern müssen. Damit der Nutzer unserer Klassen jetzt den Wert einer Seite verändern kann, kommen die „Getter“ und „Setter“ ins Spiel. Getter und Setter sind Methoden, welche einzig und allein dafür da
sind, die Werte von privaten Variablen nach außen zu führen. Wir ändern die Sichtbarkeit unserer drei Seitenwerte wieder auf
private und sehen uns am Beispiel der Seite A die Getter und Setter an:
Kurze Erklärung der Codezeilen: Der „Getter“ heißt üblicherweise
„get“ + Variablenname, wobei über das sogenannte CamelCasing (also Großbuchstabe pro Wortelement) das „s“ von
seiteA großgeschrieben wird. Der Rückgabedatentyp ist immer der gleiche wie der Datentyp der Variable, die ausgelesen werden soll. Im Regelfall gibt es für den Getter auch keinen Parameter. Der Setter wiederum benötigt
einen Parameter – natürlich wieder mit dem gleichen Datentypen, wie den der zu belegenden Variable – er hat aber keinen Rückgabetyp (also
void). In manchen Programmiersprachen (wie bspw. C#) können wir den Compiler übrigens dazu bringen, dass wenn wir einen Setter haben und eine normale Zuweisung durchführen (bspw.
myTr.seiteA = 5.0), der Setter hierfür genutzt wird. In unserem Setter haben wir nun die Prüfung über
checkValues() und belegen die Seite a in der Parameterliste mit dem neu zu setzenden Wert und den Rest über die bereits existierenden Seiten B und C. Somit können wir die gleiche Methode wie der Konstruktor nutzen und wir
würden von eventuellen „Verbesserungen“ im Code der Prüfung, wie bspw. den nachträglichen Check auf negative Werte, hier profitieren. Am Schluss wird noch
berechneFlaeche() aufgerufen.
Für die Seiten B und C sieht der Code entsprechend aus. Damit der Code nun einheitlich gestaltet wird, sollte somit für alle Instanzvariablen gelten, dass sie
private (oder
protected) sind und eventuelle Zuweisungen über Setter und der Lesezugriff über Getter erledigt wird. Dieses Konzept nennt man „Kapselung“ oder „Information Hiding“. Man zeigt nur die notwendigen Informationen nach außen und
kontrolliert den Zugriff über Methoden. Nun gibt es aber wie immer auch Ausnahmen. Entwickler von sehr performancekritischer Software – beispielsweise im 3D-Spielebereich – neigen dazu, auf
private Variablen zu verzichten, wenn die Werte außerhalb zugreifbar sein müssen. Dadurch sparen sie sich während der Laufzeit das Laden der Getter und Setter-Methoden in den Stack, was zu Performanceverbesserungen führt.
Wenn beispielsweise die Flugbahn eines 3DModells 60 mal die Sekunde berechnet werden soll, dann würde entsprechend oft der Getter und Setter von einzelnen Variablen bemüht werden. Hier gilt es, die Prioritäten richtig zu setzen –
sauberes und wartungsfreundliches Programmieren versus Performance.
Aufrufreihenfolge bei Konstruktoren
Gehen wir aber nochmal kurz auf die Konstruktoren ein. Wir haben in unserem kleinen Beispiel einen Konstruktor für die Dreiecksklasse erstellt, der sich um die Vorbereitung der internen Werte des Objektes kümmert.
Es ist immer eine gute Idee, den Konstruktor mit allen zwingend notwendigen Informationen zu versorgen, damit das Objekt nach der Erzeugung sinnvoll nutzbar ist. In unserem Beispiel war es, die drei Dreiecksseiten
zu belegen und die Fläche bzw. den Umfang zu berechnen. Nun kann man in den meisten Programmiersprachen auch auf das explizite Programmieren eines Konstruktors verzichten. Da wir den Konstruktor aber beim Erzeugen
des Objektes aus der Klasse zwingend benötigen, existiert hier trotzdem ein Konstruktor, den der Computer implizit erstellt – den Standardkonstruktor. In Java existiert also immer ein Konstruktor, auch wenn wir ihn
nicht selbst schreiben. Dieser Standardkonstruktor hat keinen Parameter und außer der Funktionalität das Objekt zu erstellen, sonst keine weiteren Aufgaben. Wir könnten also einen
ZweiDElm Objekt in unserem Code erstellen, obwohl wir hierzu keinen Konstruktor geschrieben haben:
Listing 16: Erzeugung eines Objektes mit Standardkonstruktor
Gehen wir aber nun davon aus, dass uns das zu wenig ist. Wir wollen bspw. in der Konsole ausgeben, dass ein
ZweiDElm Objekt erstellt wurde. Im impliziten Standardkonstruktor haben wir aber keine Eingriffsmöglichkeit – er existiert ja ohne unser Zutun. Die Lösung für dieses Problem ist, dass wir den Standardkonstruktor
„überschreiben“. „Überschreiben“ nicht mit „Überladen“ verwechseln – Überladen war die Erstellung von mehreren Unterprogrammen mit gleichem Namen, aber unterschiedlichen Parameterlisten. Die Signatur unterscheidet
sich also ausschließlich über die Parameter. Überschreiben ist dagegen die Erstellung einer Methode in einer Kindklasse mit exakt der gleichen Signatur, wie sie in einer höher liegenden (Eltern-)Klasse existiert.
Da die Existenz des Standardkonstruktors von der Urklasse (in Java die Klasse
„Object“) vorgegeben wird, können wir diesen also Überschreiben. Unser Code für die Klasse
ZweiDElm würde sich also wie folgt verändern:
Listing 17: Überschriebener Standardkonstruktor
Der ursprüngliche Standardkonstruktor ist von außen nun nicht mehr aufrufbar. Nun passiert etwas Interessantes. Wenn wir nun die Main Methode mit folgendem Code ausführen:
Listing 18: Erzeugung eines Dreiecksobjektes
sehen wir auf der Konsole:
Der überschriebene Standardkonstruktor wurde also von dem Dreiecksobjekt aufgerufen. Dies ist insofern sinnvoll, als dass der Konstruktor ja dafür da war das Objekt so weit vorzubereiten,
dass wir mit ihm arbeiten können. Wenn wir nun eine Klasse um einem Konstruktor erweitern, so bleibt die Forderung, die Elemente der Elternklasse „vorzubereiten“, bestehen. Diese Aufgabe
können wir nicht dem Konstruktor der Kindklasse übergeben, da im Zweifelsfall die Kindklasse gar keinen Zugriff auf alle Eigenschaften und Methoden der Elternklasse hat – sie könnten ja
private sein. Um nun das Verhalten noch genauer zu studieren, ergänzen wir den Konstruktor der Klasse
Dreieck ebenfalls um zwei Konsolenausgaben:
Listing 19: Kontrollausgaben im Dreieck Konstruktor
Bei den beiden Klassen
FlaechenElm und
GrafikElm ergänzen wir ebenfalls einen Konstruktor, der jeweils
„FlaechenElm erzeugt.“ und
„GrafikElm erzeugt.“ Ausgibt. Führen wir unser Programm aus sehen wir:
Bevor also irgendwas im Kindkonstruktor passiert, wird der Elternkonstruktor aufgerufen. Wir können uns also darauf verlassen, dass die Konstruktoren sich um die Elternaufrufe kümmern.
Nun ist noch ein Detail sehr wichtig. Bei der Dreieckklasse haben wir ja den Konstruktor mit Parametern versehen, damit wir sicherstellen konnten, dass die drei Seiten mit korrekten
Werten belegt werden. Wenn nun aber der Standardkonstruktor ohne Parameter immer existiert, könnten wir diesen „Schutzmechanismus“ mit den drei Parametern ja umgehen, indem wir nicht mehr
new Dreieck(3.0, 4.0, 5.0);, sondern
new Dreiek(); schreiben. Java verhindert dies aber, indem der Standardkonstruktor aus der Urklasse nicht mehr gültig ist, sobald mindestens ein anderer Konstruktor existiert, egal ob mit
oder ohne Parameter. Wenn wir also versuchen
new Dreieck() aufzurufen ohne, dass wir den Standardkonstruktor
Dreieck() aus der Urklasse überschrieben haben, werden wir einen Fehler erhalten:
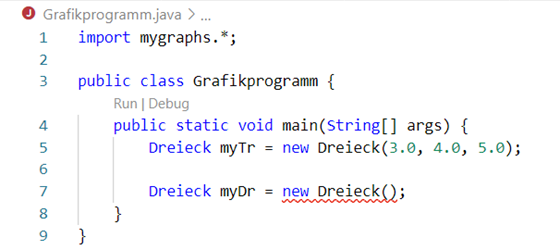
Abb.: 11: Fehlerhafte Nutzung des Standardkonstruktors
Jetzt stellt sich aber noch eine weitere wichtige Frage. Was ist, wenn wir einer Elternklasse einen Konstruktor mit Parametern geben. Ändern wir unseren Code von FlaechenElm mal wie folgt:
Listing 20: Elternkonstruktor mit Parametern
Wir haben Java also mitgeteilt, dass wir bei einem
FlaechenElm zwingend einen Wert für die Füllfarbe übergeben haben wollen. Die Kindklasse
ZweiDElm erweitert nun diese Klasse – somit auch den Konstruktor – und kümmert sich aber nicht um die Füllfarbe! Dadurch entsteht eine Compilerfehler in der Klasse
ZweiDElm:
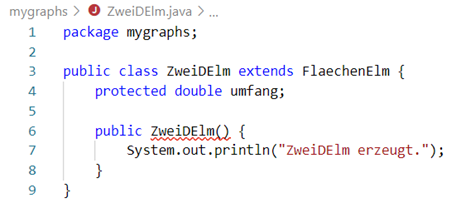
Abb.: 12: Compilerfehler aufgrund Konstruktorfehler
Die Klasse
FlaechenElm zwingt die Kindklasse nun, den parametrierten Konstruktor zu nutzten. Das bedeutet, dass sobald ein einziger Konstruktor vom Programmierer in einer Klasse mit Parametern geschrieben wurde,
der Standardkonstruktor aus der Urklasse nicht mehr existiert und wir gezwungen werden, in der Kindklasse diesen parametrierten Konstruktor der Elternklasse aufzurufen. Dadurch hat der Programmierer
der Eleternklasse die Möglichkeit denjenigen, der seine Klasse erweitert zu „leiten“, je nachdem wie viele und welche Konstruktoren er vorsieht. Aber wie ruft man den Konstruktor der Elternklasse auf?
Der Konstruktor ohne Parameter wird ja implizit aufgerufen – aber mit Parameter kann das nun nicht mehr funktionieren, da wir die Parameter ja mit irgendwelchen Werten belegen müssen! In Java erfolgt
dies über das Schlüsselwort
„super“, welches einen weiteren Namen der Elternklasse offenbart – die „Superklasse“. Programmiersprachen mit Mehrfachvererbung wie bspw. C++ kennen dieses Schlüsselwort jedoch nicht, da hier mehrere
Elternklassen existieren können. Hierauf werden wir aber später noch eingehen.
Listing 20: Elternkonstruktor mit Parametern
Kurze Erklärung der Codezeilen: Der Superkonstruktor muss in Java immer am Anfang des Konstruktorcodes der Kindklasse stehen – also in der ersten Zeile. In unserem Fall setze ich die Farbe auf
ff000016 was die Farbe Rot bedeuten würde. Alternativ kann man auch den
ZweiDElm Konstruktor um einen Füllfarbenparameter erweitern und diesen Wert einfach 1:1 an den Superkonstruktor weitergeben. Das werden wir später so implementieren. Dadurch müsste aber auch
der Konstruktor der Klasse
Dreieck ebenfalls angepasst werden, da dieser nun wiederum
ZweiDElm als Elternkonstruktor aufrufen muss.
In Programmiersprachen wie C# rufen wir den Elternkonstruktor nicht im Rumpf des Kindkonstruktors auf, sondern mit einem Doppelpunkt nach der Signatur des Kindkonstruktors. Dadurch stellt sich die Frage des Aufrufs
in der ersten Zeile wie in Java nicht. Die Details der anderen Programmiersrpachen werden wir weiter unten noch beleuchten. Fassen wir nun nochmal die Möglichkeiten zusammen. Wie müssen wir ein Objekt instanziieren,
wenn wir unterschiedliche Konstellationen bezüglich des Konstruktors haben und muss im Konstruktor der Kindklasse der Superkonstruktor aufgerufen werden? Ich gehe in der Tabelle davon aus, dass es in der Kindklasse
nur einen Konstruktor gibt – obwohl es in der Tat mehrere sein dürfen:
| Ohne Konstructor Code | Mit Konstruktor Code | ||
|---|---|---|---|
| Ohne Parameter | Mit Parameter | ||
| Instanziierung | new MyClass() | new MyClass() | new MyClass(param1, param2, ...) |
| Kindklasse mit super() call | nein | nein, wird implizit aufgerufen | Ja: super(param1, param2, ...) |
Tabelle 4: Verhaltensweisen bei Konstruktornutzung in Java
Somit haben wir schon einige interessante Konzepte der objektorientierten Programmierung kennengelernt. Mit das wichtigste aber ist das Konzept des Überschreibens von Methoden, also dass die
Kindklassen exakt die gleiche Signatur einer Methode vorsehen wie die Elternklassen (oder auch Großeltern etc.). Im Zusammenhang mit Typecasts können wir hier die eigentliche Stärke von
Objektorientierung voll ausnutzen. Gehen wir hierzu mal davon aus, wir wollen eine Methode haben, welche die wesentlichen Informationen unserer Objekte auf der Konsole ausgibt. Diese
printInfo() Methode soll nun in allen Klassen umgesetzt werden. Als erstes erweitern wir hierfür unser Klassendiagramm aus Abbildung 5. Wir tragen
auch gleich alle anderen Methoden, Datentypen und Sichtbarkeiten ein, wodurch das Klassendiagramm dem UML Standard entspricht(4). Da wir uns ab hier auf die
2D Elemente konzentrieren, verzichte ich auf alle Klassen außerhalb dieses Fokus. Weiterhin lasse ich (noch) das Dreieck weg, da wir es später nochmal integrieren werden.
(4) UML: Unified Modeling Language – eine Sammlung von normierten Diagrammen für Dokumentationen von Software
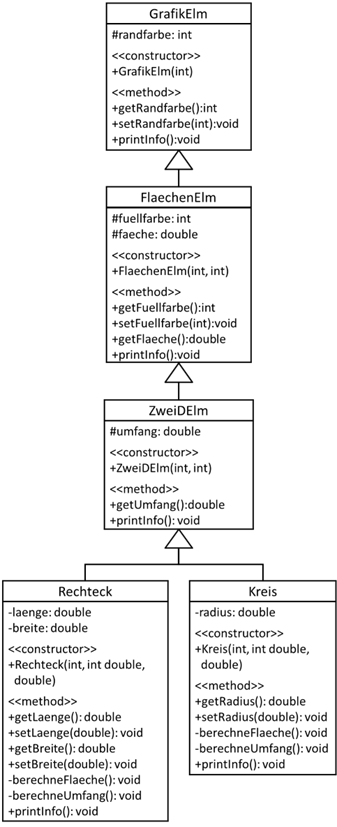
Abb.: 13: UML Klassendiagram für 2D Elemente
Wir haben also nun die Methode
printInfo() fünf mal in unserem Klassendiagramm hinterlegt. Zuerst in
GrafikElm:
Listing 22: Ergänzung GrafikElm um printInfo()
Die einzige Information, welche ein Objekt der Klasse
GrafikElm besitzt, ist die Randfarbe. Diese setzte ich nun gleich über den Konstruktor und erstelle die Getter- und Settermethoden. In der
printInfo() Methode wird somit auch nur die
randfarbe ausgegeben. Gehen wir nun auf die nächste Klasse des Klassendiagramms,
FlaechenElm:
Listing 23: Ergänzung FlaechenElm um printInfo()
Kurze Erklärung der Codezeilen: Sowohl die
fuellfarbe, als auch die
flaeche wurde auf
protected gesetzt, da die Kindklassen darauf zugreifen sollen. Dadurch werden auch die Gettermethoden notwendig, da wir sonst von außen
(sprich von der Klasse
Grafikprogramm) nicht zugreifen können. Der Setter wird allerdings nur für die
fuellfarbe erstellt, da die
flaeche idealerweise berechnet wird. Das kann aber nicht in dieser Klasse erfolgen, da die Fläche nicht auf dieser Ebene berechnet werden kann. Ein Objekt der Klasse
FlaechenElm weiß nicht, ob es bspw. ein Kreis oder ein Rechteck ist, bzw. wird. Insofern müssen sich die Klassen
Kreis bzw.
Rechteck darum kümmern die Fläche zu berechnen. Die
printInfo() Methode der Klasse
FlaechenElm ruft zuerst die
printInfo() Methode der Superklasse (also Elternklasse, was
GrafikElm ist) auf und gibt danach seine eigenen Informationen aus.
Wir dürfen natürlich nun nicht vergessen, in der Klasse
ZweiDElm den Superkonstruktoraufruf auf zwei Parameter anzupassen, indem wir bspw. die beiden Farben Rot und Blau hinterlegen:
super(0xff0000, 0x0000ff);
13.8 „this“ und „super“
An dieser Stelle müssen wir noch etwas genauer über die Schlüsselwörter
„super“ und
„this“ sprechen.
„super“ haben wir ja bereits beim Superkonstruktor kennengelernt und auch erfahren, dass dies nur bei Programmiersprachen sinnvoll ist, welche keine Mehrfachvererbung unterstützen.
Da wir mit Java eine solche Sprache vorliegen haben, gehe ich hier auf diese Schlüsselwörter ein. Am Ende des Kapitels kümmern wir uns um die Syntaxvarianten der anderen Sprachen. Das Schlüsselwort
„super“ finden wir in zwei verschiedenen Kontexten. Zum einen als Konstruktoraufruf der Superklasse
super(initRandfarbe); und zum anderen als Referenz auf die Methoden der Superklasse
super.printInfo(); Hier ist der Ausdruck
super so zu verstehen, wie eine Variable, welche eine Referenz auf ein Objekt besitzt. Das Gleiche gilt auch für
this. Es zeigt ebenfalls auf ein Objekt – sprich es beinhaltetet auch eine Referenz. Wir haben ja weiter Oben gesehen, dass eine Variable welche ein Objekt hält, lediglich eine Referenz auf das
Objekt beinhaltet – eine Art Adresse. Wenn wir also schreiben
FlaechenElm myElm = new FlaechenElm(0, 0); dann liegt in
myElm die Referenz auf das Objekt der Klasse
FlaechenElm, bei dem wir mit dem Punktoperator auf die einzelnen Methoden dieser Klasse zugreifen können (bspw.
myElm.getFuellfarbe();) Wir können nun innerhalb einer Klasse
FlaechenElm mit
this bzw.
super genauso auf dieses Objekt zugreifen. Der Aufruf
myElm.getFuellfarbe(); außerhalb der Klasse
FlaechenElm ruft also exakt die gleiche Methode auf, wie der Aufruf
this.getFuellfarbe(); innerhalb der Klasse
FlaechenElm. Hier ist also
myElm die Variable welche außenstehende Klassen nutzen, um auf die Objektmethoden zuzugreifen und
this das Konstrukt, welche für die Objekte der Klasse intern genutzt werden kann, um auf eigene Objektmethoden (und auch Eigenschaften) zuzugreifen – also eine Art Selbstreferenz.
super wiederum ist das Gleiche wie
this, lässt aber ausschließlich den Zugriff auf die Methoden der Superklasse zu, was im Fall von
FlaechenElm die Klasse
GrafikElm wäre. Sehen wir uns dieses Konzept nun mal beim Aufruf der Methode
printInfo() über die Objektvariable, dem Schlüsselwort
this und
super an:
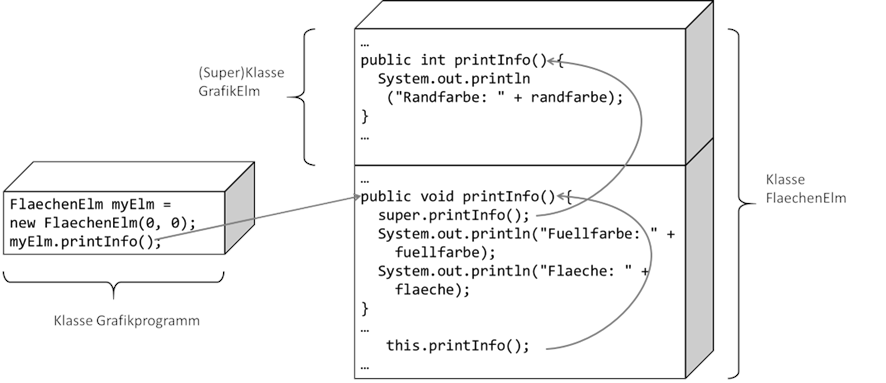
Abb.: 14: Zugriff über Variable, this und super
Sehr praktisch erweist sich das
this Schlüsselwort dann, wenn eine lokale Variable genauso heißt, wie eine Instanzvariable. In solch einer Situation wird die Instanzvariable immer mit
this davor notiert und die lokale Variable ohne
this. Weiter unten im
Listing 25 kann man das im Konstruktor der
Rechteck Klasse sehen. Nun ergänzen wir die Klasse
ZweiDElm:
Listing 24: Ergänzung ZweiDElm um komplette Parameter für Konstruktor
Soweit nichts wirklich Neues. Nun widmen wir uns den Klassen
Rechteck und
Kreis:
Listing 25: Ergänzung Klasse Rechteck
Die detaillierte Darstellung der Getter- und Settermethoden habe ich mir hier gespart, da sie nach Schema erzeugt werden. Es geht sogar soweit, dass die
meisten IDEs die Getter- und Settermethoden (meist bei einem Rechtsklick auf eine
private oder
protected Variable) automatisch generieren. Nun fehlt nur noch die Klasse
Kreis:
Listing 26: Ergänzung Klasse Kreis
13.9 Typecasts mit Klassen – von Verpackungen und Inhalten
Was nun inzwischen klar sein sollte ist die Tatsache, dass alle Methoden und Eigenschaften der Elternklasse jeweils an die Kindklasse vererbt werden
(dies gilt übrigens auch für die Methoden und Eigenschaften, die
private sind. Sie sind zwar aus Sicht der Kindklassen nicht zugreifbar, aber sie existieren). Dies hat nun eine wichtige Konsequenz für den Typecast.
Wir haben gesehen, dass eine Klasse nach außen hin die Eigenschaften und Methoden anbietet, welche
public sind. Wenn nun bspw. die Klasse
GrafikElm eine
public Methode implementiert hat, dann hat auch die Kindklasse
FlaechenElm diese Methode. Sehen wir uns diesen Gedanken für alle Methoden tabellarisch an. Die Tabelle zeigt alle Methoden und
Eigenschaften der einzelnen Klassen. Jeder nicht leere Eintrag bedeutet, sie existiert in der Klasse, egal ob von außen sichtbar oder unsichtbar. Das X indiziert,
dass die Eigenschaft bzw. die Methode implementiert wurde und das V, dass die Existenz nur wegen der Vererbung vorliegt. Ü wiederum heißt, eine erweiternde Klasse überschreibt die Methode.
| Methoden und Eigenschaften: | Typ: | GrafikElm | FlaechenElm | ZweiDElm | Rechteck | Kreis |
|---|---|---|---|---|---|---|
| private randfarbe | Eigenschaft | X | V | V | V | V |
| public int getRandfarbe() | Methode | X | V | V | V | V |
| public void setRandfarbe(int newRandfarbe) | Methode | X | V | V | V | V |
| public void printInfo() | Methode | X | Ü | Ü | Ü | Ü |
| protected int fuellfarbe | Eigenschaft | X | V | V | V | |
| protected double flaeche | Eigenschaft | X | V | V | V | |
| public int getFuellfarbe() | Methode | X | V | V | V | |
| public void setFuellfarbe(int newFuellfarbe) | Methode | X | V | V | V | |
| public double getFlaeche() | Methode | X | V | V | V | |
| protected double umfang | Eigenschaft | X | V | V | ||
| public double getUmfang() | Methode | X | V | V | ||
| public void printInfo() | Methode | X | V | V | ||
| protected double laenge | Eigenschaft | X | ||||
| protected double breite | Eigenschaft | X | ||||
| private void berechneUmfang() | Methode | X | X | |||
| private void berechneFlaeche() | Methode | X | X | |||
| public double getLaenge() | Methode | X | ||||
| public void setLaenge(double laenge) | Methode | X | ||||
| public double getBreite() | Methode | X | ||||
| public void setBreite(double breite) | Methode | X | ||||
| protected double radius | Eigenschaft | X | ||||
| public double getRadius() | Methode | X | ||||
| public void setRadius(double radius) | Methode | X |
Tabelle 5: Existenz von Methoden und Eigenschaften
Man erkennt, dass sich die Methoden und Eigenschaften komplett in den Kindklassen wiederfinden. Vor allem bei den Methoden eröffnet sich nun eine sehr schöne Möglichkeit.
Wir haben bei der Nutzung von Objekten immer den Konstruktor benannt, der bestimmt welches Objekt im Speicher erzeugt wird. Weiterhin haben wir immer eine Variable definiert,
welche das Objekt aufnehmen kann. Hier haben wir auch wieder die Klasse als „Datentyp“ vorgegeben:
FlaechenElm myVar = new FlaechenElm(0,0);. Der Datentyp der Variablen
FlaechenElm heißt also genauso wie der Konstruktor
FlaechenElm(). Nun kann man sich die Variable in diesem Beispiel als eine exakt angepasste Hülle für das Objekt vorstellen. Für jede nach außen sichtbare Methode bzw. Eigenschaft
wird von der Variable eine Zugriffsmöglichkeit vorgesehen. Wenn das Objekt also die Methode im Sinne eines „Knopfes“ hat, den man drücken kann, ist das im Falle der Variable nicht
ein Knopf, sondern ein Loch in der Hülle, welche den Knopf freigibt, so dass man ihn von außen drücken kann. Wenn wir nun das Objekt in eine andere Hülle stecken, die nicht für alle
„Knöpfe“ ein passendes Loch vorsieht, dann kann man eben nur noch diejenigen „Knöpfe“ drücken, welche von außen zugreifbar sind. Alle anderen „Knöpfe“ existieren zwar, sind aber nicht
zu betätigen, da die Aussparung fehlt. Sehen wir uns diesen Gedanken mal grafisch an, wenn bspw. ein Objekt vom Typ
FlaechenElm einmal in eine Variable vom Typ
FlaechenElm gelegt wird und einmal in eine Variable vom Typ
GrafikElm:
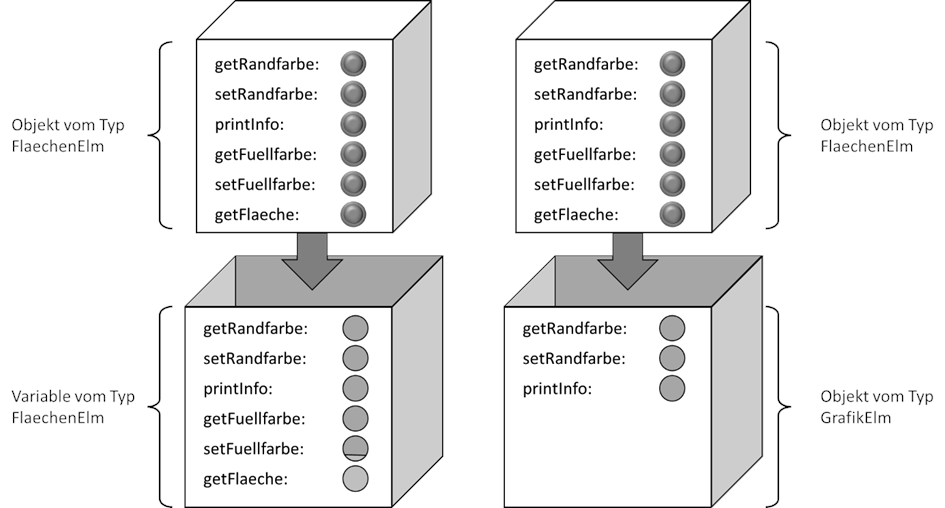
Abb.: 15: Vorstellungshilfe für Objekte in verschiedenen Variablentypen
Das Schöne daran ist nun, dass wir ein Objekt vor diesem Hintergrund in Variablen von allen Datentypen legen können, welche entweder identisch mit dem Objekt sind (also „Objekt
FlaechenElm liegt in Variable vom Typ
FlaechenElm“), oder aber von jedem Vorfahren (also bspw. „Objekt
FlaechenElm liegt in Variable vom Typ
GrafikElm“). Dies ist deshalb möglich, da die Kinder ja alle Methoden der Eltern erben – die „Aussparungen“ der Eltern also mit den „Knöpfen“ der Kinder übereinstimmen müssen. Entscheidend bei dieser
Vorstellung ist, dass das Objekt in der Variable immer das gleiche Objekt ist. Wir finden in unserem rechten Beispiel von
Abbildung 15 also ein
FlaechenElm Objekt in einer Variablen vom Typ
GrafikElm.
Polymorphie - eine Variable mit vielen Gesichtern
Die Möglichkeit, Kindobjekte in Elternvariablen zu setzen hat nun eine sehr wichtige Konsequenz zur Folge. Sehen wir uns hierzu folgenden Code an, den wir bspw. in der Klasse
Grafikprogramm finden könn-ten:
Listing 27: Ausgabe aller Objektinformationen
Wenn wir in der
ArrayList allElements nun einen Kreis und ein Rechteck haben würden, könnte unser Hauptprogramm wie folgt aussehen:
Listing 28: Bewirtschaftung der ArrayList
Wir speichern also sowohl Rechtecke als auch Kreise in der
ArrayList und erhalten die Ausgabe:
Die Meldungen über die Objekterzeugungen dürften nun keine Überraschung darstellen. Spannender ist nun, dass bei den
printInfo() Aufrufen offensichtlich nicht die Methoden der
GrafikElm Klassen aufgerufen wurden, sondern die der
Kreis und
Rechteck Klassen. Das deckt sich aber mit unserer Überlegung aus
Abbildung 15. Die eigentliche Funktionalität wird nicht durch den Variablentyp bestimmt, sondern einzig und alleine durch das Objekt, welches in dieser Variable „steckt“.
Die Variable ist lediglich dafür zuständig, welche Methoden von außen nutzbar sind. Insofern rufen wir zwar die Methode
printInfo() in einer Variablen vom Typ
GrafikElm auf, die Methode wird aber durch das Objekt vom Typ
Rechteck bzw.
Kreis bestimmt. Durch die Tatsache, dass die Funktionalität und die Eigenschaften in Objekten zusammengefasst sind, entstehen nun zwei entscheidende Vorteile. Zuerst sehen wir,
dass die Methode
printAllInfos() relativ einfach gestrickt ist. Überlegen wir uns mal, wie ein prozedurales Programm mit dieser Funktionalität aussehen müsste:
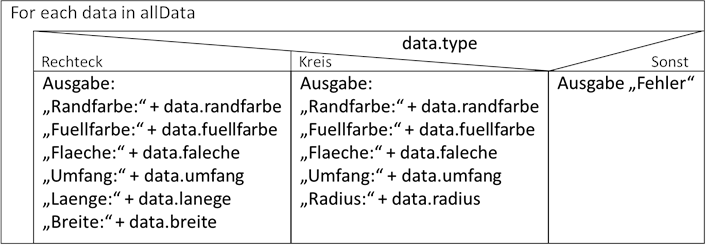
Abb.: 16: Prozedurale Lösung für Ausgabe der Dateninfos
Das Errorhandling im „sonst“ Zweig ist notwendig, weil wir nicht 100% sicher sein können, dass in data.type ausschließlich „Rechteck“ und „Kreis“ zu finden ist. Zum Vergleich nochmal die objektorientierte Lösung:

Abb.: 17: Objektorientierte Lösung für Ausgabe der Dateninfos
Wir sehen, dass die eigentliche Ausgabemechanik nicht Teil des zentralen Programms ist, sondern in den jeweiligen Objekten hinterlegt ist. Dadurch haben wir auch keine Notwendigkeit mehr, ein Errorhandling zu implementieren.
Es gibt nicht mehr die Möglichkeit, dass wir in data.type einen unbekannten Wert finden, weil wir kein Unterscheidungsmerkmal wie „Typ“ benötigen. Der zweite unschätzbare Vorteil dieses Ansatzes ist, dass wir keinerlei Änderungen in der
printAllInfos() Funktion mehr machen müssen, wenn wir eine neue Klasse hinzufügen. Wenn wir beispielsweise das Dreieck hinzufügen wollen, so müssen wir lediglich den Code für das Dreieck ergänzen:
Listing 29: Code für Dreieck Klasse
Wenn wir in unserem Hauptprogramm nun ein Dreieck hinzufügen:
Listing 30: Bewirtschaftung der ArrayList um zusätzliches Dreieck
…so werden diese Daten ganz normal mitverarbeitet:
Das heißt, die
printAllInfos() Methode kann Daten von Klassen verarbeiten, die zu seiner Compilezeit noch gar nicht vorhanden waren. Dies öffnet ein ganzes Universum an Möglichkeiten, da wir Codemodule wie das
Dreieck nachträglich ergänzen können, ohne den eigentlichen Kern des Programms wie bspw.
printAllInfos() anzufassen. Dieses Verhalten wird auch als „späte Bindung“ oder englisch „late binding“ bezeichnet. Die Zuordnung des eigentlich auszuführenden Codes erfolgt somit nicht bei der
Programmierung des
printAllInfos() Programms aus
Listing 27, sondern zum Zeitpunkt der Ausführung. Dieses Verhalten von (Eltern-)Variablen wird mit „Polymorphie“ umschrieben. Hierunter versteht man also, dass eine Methode (definiert durch die Signatur)
auf mehreren Ebenen des Vererbungsbaumes implementiert wurde – also genau das, was wir bei der Implementierung der Methode
printInfo() finden.
Abstrakte Elemente – die Kinder sollen es machen
Als nächstes müssen wir noch eine Ungenauigkeit aus unserem Code „ausbauen“, damit die Klassen nicht falsch genutzt werden können. In den Klassen
FlaechenElm und
ZweiDElm finden wir die Eigenschaften
flaeche und
umfang. Diese Werte existieren zwar auf den Ebenen dieser beiden Klassen, können aber erst auf der Ebene der Kreis-, Rechteck- und Dreiecksklasse berechnet werden, da nur hier ein Berechnungsalgorithmus definierbar ist.
Dies bedeutet mit anderen Worten, dass es nicht sinnvoll ist, Objekte zu instanziieren, welche oberhalb dieser drei Klassen liegen. Alle Klassen oberhalb von
Kreis,
Rechteck und
Dreieck dienen also lediglich als Sammlung von Methoden und Eigenschaften, nicht aber als Klasse für die direkte Instanziierung. Wir können mit Hilfe des Schlüsselwortes
„abstract“ dafür sorgen, dass aus einer Klasse kein Objekt erzeugt werden kann. Beginnen wir mit der Klasse
GrafikElm:
Listing 31: Abstrakte Klasse GrafikElm
Wenn wir nun versuchen würden, mit Hilfe von new
GrafikElm(0) ein Objekt zu erzeugen, erhalten wir eine Fehlermeldung. Bei den Klassen
FlaechenElm und
ZweiDElm können wir sogar noch einen Schritt weiter gehen. Wir würden bei beiden Klassen auf den ersten Blick erwarten, dass es die Möglichkeit geben sollte, die Fläche und den Umfang zu berechnen – sprich es
sollten die Methoden
berechneUmfang() und
berechneFlaeche() geben. Wie wir aber festgestellt haben, können wir diese Methoden auf dieser Ebene nicht umsetzen, sondern nur auf Ebene
Kreis,
Dreieck oder
Rechteck. Die Programmiersprachen bieten auch hier eine Möglichkeit, den Programmierer als Nutzer der Klassen sinnvoll zu „führen“. Wir können das Schlüsselwort
abstract auch vor eine Methode schreiben:
Listing 32: Abstrakte Methode
Wenn eine Methode als
abstract definiert wird, benötigt sie keinen Rumpf mehr und die zugehörige Klasse muss dann ebenfalls
abstract sein. Die Idee ist, dass in solch einem Fall die Klasse als „nicht komplett“ geflagged ist und man dem Nutzer der Klasse damit mitteilt, es ist sinnlos aus dieser
Klasse ein Objekt zu erzeugen, da noch etwas fehlt – in unserem Fall eben die Methode
berechneFlaeche(). Der einzige Weg nun diese Klasse zu nutzen ist, sie zu erweitern. Bei der Erweiterung muss nun die Methode
berechneFlaeche() implementiert werden, weshalb wir die Sichtbarkeit mindestens auf protected setzen müssen. Wird die Methode nicht in der erweiterten Klasse implementiert,
muss die erweiternde Klasse ebenfalls
abstract sein. In unserem Fall ist diese Option sinnvoll, da wir in der Klasse
ZweiDElm ebenfalls eine Methode haben, die
abstract sein muss:
Listing 33: Abstrakte Methode
Wenn wir in den Klassen
Kreis,
Dreieck und
Rechteck nun die Methoden
berechneUmfang() und
berechneFlaeche() als
protected Methoden implementieren (also ohne
abstract), so haben wir der Forderung genüge getan und die von den Elternklassen geforderten Methoden umgesetzt. Da die Sichtbarkeit von den Eltern als
protected vorgegeben wurden, muss diese bei den Kindern ebenfalls auf
protected gesetzt werden. Es wäre auch sinnlos, dass von den Eltern eine Methode gefordert werden würde, welche nur für den internen Gebrauch der Kinder vorzusehen ist. Ähnlich problematisch wäre es,
wenn eine Elternklasse etwas als
protected von der Außenwelt schützt und die Kinder es mit
public nun doch freigeben würden.
Interfaces – von Steckern und Steckdosen
Neben den
abstract Klassen (und Methoden) gibt es eine weitere Möglichkeit eine Klasse dazu zu zwingen, bestimmte Methoden zu realisieren – das Interface, also die „Schnittstelle“. Der Gedanke hier ist,
dass wir mit einem Interface nur noch die Methoden einfordern, welche vorhanden sein müssen. Dies wäre vergleichbar mit einer abstrakten Klasse, welche ausschließlich abstrakte Methoden vorsieht
und vom Prinzip her keinerlei Instanzvariablen besitzt (wobei es hierfür auch Ausnahmen gibt). Jede Methode, welche im Interface hinterlegt ist, muss von der Klasse implementiert werden. Die
einzige Ausnahme wäre, wenn die Klasse selbst
abstract wäre. Dann müssten die Kindklassen diese Implementierung übernehmen. Soweit die „reine Lehre“. Je nach Programmiersprache können Interfaces aber noch mehr als nur Methodenrümpfe enthalten
– bspw. Konstanten, oder eben auch Eigenschaften, Konstruktoren etc.
Grundsätzlich ist der Name „Interface“ recht treffend gewählt. Eine Interfacedefinition beschreibt eine Art „Norm“, welche erfüllt werden muss. Genauso wie bei Steckdosen eine Norm für die Maße existiert – somit können wir
beliebige Geräte in die Steckdose einstecken. Auch solche, die wir zum Zeitpunkt der Montage der Steckdose noch gar nicht kennen – solange der Ste-cker der Norm entspricht.
In der Programmierung legt das Interface die „Norm“ für die notwendigen Methoden einer Klasse fest, die zu einem späteren Zeitpunkt erst „in die Variable gesteckt wird“.
Somit können wir die Klasse, welche dem Interface entsprechen muss erst zu einem späteren Zeitpunkt realisieren.
Schreiben wir nun ein Interface, welches die Methode
„toJsonString()“ einfordert. Hierzu erzeugen wir ein neues File
„Jsonifyable.java“ und schreiben folgenden Inhalt hinein:
Listing 34: Interface
Der Einfachheit halber habe ich es in das Package
mygraphs gesetzt – es darf aber in einem beliebigen Package gespeichert sein. Die Parallele zu abstrakten Methoden ist offensichtlich. In unserem Beispiel habe ich „nur“ eine
Methode eingetragen(5), es dürfen aber auch mehrere sein. Nun wollen wir beispielhaft in der Klasse
Rechteck das Interface implementieren:
(5) Interfaces mit nur einer einzigen Methode nennt man auch „funkitonale Interfaces“ und spielen bei der funktio-nalen Programmierung eine Rolle.
Listing 35: Implementierung einer Interfacemethode
Kurze Erklärung der Codezeilen: Mit dem Schlüsselwort
implements wird in Java die Implementierung aller im Interface
Jsonifyable definierten Methoden gefordert. Diese müssen lediglich die gleiche Signatur und Sichtbarkeit wie im Interface aufweisen. JSON steht übrigens für
„Java Script Object Notation“ und ist eine an JavaScript angelehnte Auszeichnungssprache für den Datentransport. Variablennamen und Stringwerte werden in dieser
Notation in Anführungszeichen gesetzt. Da in Java ein
String auch immer in doppelten Anführungszeichen gesetzt werden muss, können wir die für JSON geforderten Anführungszeichen nicht direkt eintragen, sondern wir müssen
sie „escapen“, was für Java bedeutet, wir schreiben ein Backslash davor. Wenn wir die Filezugriffe bei Textdateien ansehen, kommen wir nochmal auf das
Thema „Escapezeichen“ zu sprechen.
Die Methode
getJsonString() muss mit exakt der Signatur implementiert werden, wie sie im Interface gefordert wird – genauso, wie es bei einer abstrakten Methode gefordert werden würde.
Im Gegensatz zu abstrakten (Eltern-)Klassen können aber Kindklassen beliebig viele Interfaces implementieren – auch in Java. Nach
implements dürfen also mehrere Interfaces kommasepariert geschrieben werden. Die Klasse muss somit sämtliche Methoden von allen Interfaces implementieren (oder eben abstrakt sein und die
Implementierung der Kindklassen überlassen). Wir können nun ein Objekt der Klasse
Rechteck instanziieren und dieses dann in eine Variable vom Typ
Jsonifyable legen:
Listing 36: Varablen vom Typ eines Interfaces
Die Ausgabe ist entsprechend:
Eine Variable vom Typ eines Interfaces ist also wieder wie ein Behälter für Objekte zu verstehen, welche die im Interface hinterlegten Methoden des Objektes zugreifbar macht.
Wenn nun abstrakte Klassen und Interfaces so ähnlich sind, was sollte man nun wann verwenden? Die beiden großen Unterscheidungsmerkmale sind ja, dass man (zumindest in
Java und C#) nur von einer Klasse erben kann, aber mehrere Interfaces implementieren darf und dass man in Klassen Methoden mit Funktionalität und auch Eigenschaften einbauen kann,
nicht aber in Interfaces. Insofern sollte man immer dann, wenn man keine für alle Kindklassen gemeinsame Funktionalität vorab implementieren möchte, ein Interface nehmen.
Sobald man jedoch auf der gemeinsamen Ebene Funktionalitäten (oder auch Eigenschaften) benötigt, sollte man über Superklassen nachdenken.
Es gibt bspw. mit C++ jedoch auch objektorientierte Programmiersprachen, welche das Konzept „Interface“ so nicht kennen und stattdessen voll auf abstrakte Klassen setzen.
Da C++ mehr als eine Elternkasse erlaubt, ist dies auch kein Problem
Eine Facette, welche man in Java mit Interfaces realisieren kann, sind anonyme Klassen. Bis jetzt haben Klassen immer einen Namen erhalten der uns garantiert, dass die Objekte exakt
die Funktionalitäten aufweisen, welche in der Klasse als Methoden vorgegeben waren. Ein Interface hingegen definiert nur die Signaturen der Methoden. Wir können nun basierend auf dieser
Definition ein Objekt erstellen, welches einzig und allein die Methoden realisiert, die im Interface vorgegeben sind. Dieses Objekt muss anschließend einer Variable vom Typ des Interfaces abgelegt werden:
Listing 37: Anonyme Klasse aus Interface
Wenn wir diesen Code ausführen, sehen wir auf der Konsole:
Da das Objekt der anonymen Klasse immer innerhalb des Kontexts eines Objekts und dort innerhalb einer Methode existiert
drängt sich die Frage auf, ob das anonyme Objekt auf diese Variablen zugreifen kann. Hier unterscheiden wir die
Instanzvariablen (also die Variablen, welche in der Klasse deklariert wurden) und die lokalen Variablen (also diejenigen,
welche in der Methode deklariert wurden). Während Instanzvariablen einen lesenden und schreibenden Zugriff des anonymen
Objektes erlauben, dürfen lokale in Java Variablen nur gelesen werden. Um den Code lesbarer zu gestalten, sollten die
lokalen Variablen, welche für die anonyme Klasse benötigt werden, sogar als
final deklariert werden – also nicht änderbar:
Listing 38: Zugriffe des anonymen Objektes auf externe Variablen
Kurze Erklärung der Codezeilen: Die Variable
instanceVar ist eine Instanzvariable der Klasse
Grafikprogramm.
localOuterVar wiederum ist eine lokale Variable der Methode
doSomething(), in welcher auch das Objekt der anonymen Klasse erzeugt wird. Dort wiederum greifen wir auf
localOuterVar nur lesend zu. Jeder schreibende Zugriff würde zu einem Fehler führen – selbst wenn wir auf das
Schlüsselwort
final bei der Deklaration der
localOuterVar verzichten würden.
instanceVar kann hingegen verändert werden. Die Variable
localInnerVar habe ich nur zum Vergleich für die innere Variable eingebaut.
Die Ausgabe des Programms ist:
In diesem Zusammenhang müssen wir nochmal kurz auf das Schlüsselwort
this eingehen. Da die anonyme Klasse innerhalb des Kontextes der Klasse
Grafikprogramm existiert, muss hier geklärt werden, auf welches Objekt
this zeigt – auf das anonyme Objekt oder auf das Objekt vom Typ
Grafikprogramm. Wie man vielleicht instinktiv bereits richtig vermutet, zeigt this innerhalb der anonymen Klasse
auf das Objekt eben dieser Klasse und nicht auf das Objekt der Klasse
Grafikprogramm. Wenn wir jedoch auf das Grafikprogramm Objekt zeigen wollen, müssen wir ein „qalifiziertes this“
verwenden, indem wir den Klassennamen davor schreiben. Wir könnten bei der Inkrementierung also anstatt nur
instanceVar++; auch
Grafikprogramm.this.instanceVar++; schreiben. Dies ist vor allem dann wichtig, wenn es Namensgleichheiten innerhalb
und außerhalb der anonymen Klasse gibt.
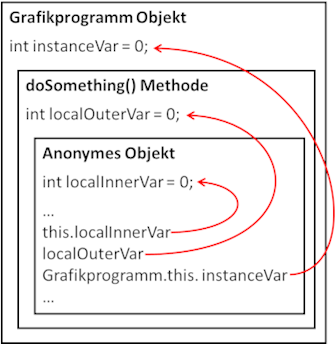
Abb.: 18: Zugriffe aus anonymen Klassen heraus
Interfaces werden auch häufig dafür genutzt, in einer Methode ein Objekt zu übergeben, welches einen exakt definierten
Funktionsumfang aufweist. Beispielsweise gibt es Objekte für grafische Nutzeroberflä-chen, welche eine ganz bestimmte
Methode aufrufen wollen, sobald sie geklickt wurden, oder wenn der Mauszeiger sie berührt. Sie erwarten also Objekte,
welche genau diese Methoden aufweisen. Gehen wir in unserem Beispiel mal davon aus, dass die Klassen
Dreieck,
Rechteck und
Kreis eine Referenz auf ein Loggingobjekt benötigen. Dieses Objekt soll gewisse Informationen schreiben – man möchte
aber offen halten, ob das Objekt auf die Konsole, in ein File oder gar per eMail die Informationen sendet. Je nach
Ziel soll ein anderes Loggingobjekt eingebaut werden können:
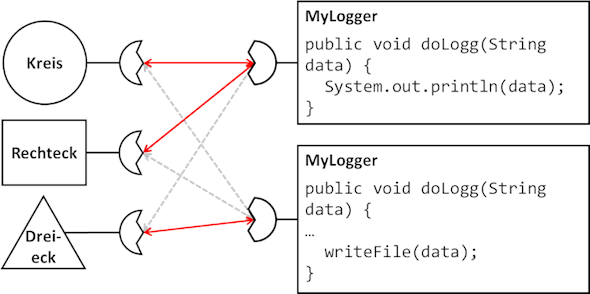
Abb.: 19: Interface für verschiedene Loggerobjekte
Je nachdem welcher Logger nun an das Interface angedockt wird, kommen die Logingformationen nun auf der Konsole oder
in einem Loggfile an. Der Code für das Interface ist sehr simpel:
Listing 39: Logger Interface
Der Übersicht halber habe ich für den Logger ein eigenes Package definiert. Nun ergänzen wir die Klasse
Grafikelement um folgenden Code, der dafür sorgt, dass ein Logger in den Objekten zur Verfügung steht:
Listing 40: Ergänzung der Klassen um das Logger Objekt
Nun können wir an jeder Stelle der Klasse
Grafikelement (bzw. allen Nachfahren) anstatt
System.out.println(…) den Logger nutzen. Bspw. können wir jeden Lesezugriff auf
umfang in der Klasse
ZweiDElm loggen:
Listing 41: Nutzung des Loggers in der ZweiDElm Klasse
Wenn also ein Logger registriert wurde, dann logged er die Infos, ansonsten passiert nichts. Den Logger können wir nun als aufwändige Klasse implementieren, welche die
Logginginformationen per Mail versendet oder als Logger, der in eine Datenbank schreibt oder als ganz simplen Logger für die Konsole. Und für letzteren können wir
nun wieder eine anonyme Klasse nutzen:
Listing 42: Registrierung eines Loggers als anonyme Klasse
…oder wir bauen uns zwei verschiedene Logger, welche wir dann beliebig einsetzen können. Da wir (noch) keine Filezugriffe kennen, realisieren wir einfach einen simplen Logger, der
einfach nur den data Parameter auf die Konsole schreibt und einen JSON Logger, der die Infos in einen JSON String eingliedert. Beginnen wir mit dem simplen Logger:
Listing 43: Simpler Logger
Und anschließene den nicht minder simplen JSON Logger:
Listing 44: JSON Logger
Nun instanziieren wir einen Logger – bspw. den JSON Logger und registrieren ihn in der
Dreieck Klasse:
Listing 45: Registrierung des JSON Loggers
In der
Kreis Klasse probieren wir einfach den simplen Logger
MyPlainLogger aus:
Listing 46: Registrierung des simplen Loggers
Je nachdem, welcher Logger registriert wurde, erhalten wir nun bei einem
doLog Aufruf eine Konsolenausgabe mit oder ohne JSON Formatierung. Wenn wir also bei
myR,
myD oder
myK den Umfang auslesen:
Listing 47: Triggern der Logvorgänge durch auslesen des Umfangs
…erhalten wir auf der Konsole die passenden Logeinträge:
Da wir nun unser Interface MyLogger mit nur einer einzigen Methode ausgestattet haben, sprechen wir von einem „funktionalen Interface“. Java ermöglicht hier eine alternative
Schreibweise bei der Registrierung unseres Loggers, und zwar mit Hilfe eines Lambda Ausdrucks. Diese Ausdrücke wurden mit Java 8 eingeführt und sollen dem Java Programmierer
helfen, die Sprache im Sinne von funktionalen Programmierparadigmen zu nutzen. Wir sprechen hier also streng genommen nicht von einem objektorientierten Feature. Der Vollständigkeit
halber bespreche ich es hier trotzdem. Wir werden später noch grob auf die Ideen dieses funktionalen Paradigmas eingehen. So viel vorab – man versucht bei einer funktionalen
Programmierung alle Methoden so zu gestalten, dass sie keinerlei Abhängigkeiten nach außen haben, mit Ausnahme der übergebenen Parameter und Rückgabewerte. Also keinerlei
Zugriffe auf bspw. globale Variablen. Da unsere Loggingfunktion über die Konsole genau diese Eigenschaft erfüllt, können wir die Registrierung unseres Loggers auch wie folgt schreiben:
Listing 48: Lambda Ausdruck in Java
Kurze Erklärung der Codezeilen: Im Wesentlichen ist es nur eine verkürzte Darstellung der Registrierung aus
Listing 42. In Klammern befinden sich die Übergabeparameter. In unserem Fall steht im Interface
MyLogger für die Methode
doLog, dass dort eine
String Variable benötigt wird – also schreiben wir im Lambda Ausdruck auch nur eine Variable – eben vom Typ
String hinein. Der Datentyp wird nicht benötigt, da er bereits im Interface beschrieben wurde. Somit müsste klar sein, warum wir hier ein funktionales Interface eben mit nur einer
Methode akzeptieren dürfen – sobald mindestens zwei Methoden im Interface stehen weiß Java nicht, welche der beiden gemeint ist. Danach erfolgt der
-> Operator, welcher die Variable(n) in Klammern dem Code zuordnet. Unsere Methode hat lediglich eine einzige Zeile, nämlich die Ausgabe auf der Konsole.
Statische Elemente – es geht auch ohne Objekte
Das letzte Schlüsselwort im Zusammenhang mit Objektorientierung, welches zu besprechen gilt, ist
static. Dieses Wort haben wir ja bereits in unserem ersten Java Programm „HelloWorld“ in der Main Methode gesehen. Um den Begriff
static zu verstehen, müssen wir wieder an den Anfang gehen, wo wir uns den Unterschied zwischen einem Objekt und der Klasse angesehen haben. Die Klasse haben wir dort mit dem Bauplan eines Hauses verglichen,
während das Objekt das eigentliche Haus war. Die Instanzvariablen waren Speicherzellen, welche jeweils pro Objekt erzeugt werden mussten. In unserem Haus Beispiel war das bspw. das Namensschild am Haus.
Jedes Haus hat ein eigenes Namensschild und jeder Hausbesitzer kann seinen individuellen Namen dort hinterlegen. Nun gibt es aber auch Eigenschaften, welche für alle Häuser, oder besser gesagt für den Plan
gelten. Sie unterscheiden sich nicht pro Haus. Beispielsweise ist der Name des Architekten für alle Häuser gleich. Selbst wenn noch gar kein Haus gebaut wurde – sprich kein Objekt instanziiert wurde – möchten
wir vielleicht den Namen des Architekten festhalten. Und dies würde in diesem Fall nur auf dem Plan selbst gehen:
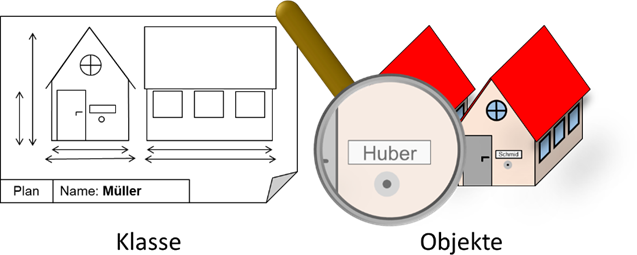
Abb.: 20: Statische Klassenvariablen vs. Instanzvariablen
Gleiches gilt auch für Methoden. Wir können Methoden realisieren, welche nicht auf Objektebene implementiert werden, sondern auf Klassenebene. Und diese Methoden und Eigenschaften, welche nur auf Klassenebene existieren sollen, sind
static. Oftmals sind statische Eigenschaften auch als
final implementiert, was bedeutet, sie können ihren Wert nicht mehr ändern – sogenannte Konstanten. Aber es ist nicht zwingend notwendig. Man kann in der Tat statische Variablen auch ohne
final implementieren, so dass sie auch änderbar sind. Dies ist jedoch nur dann notwendig, wenn wir im Rahmen der aktuellen JVM(6) (Java Virtual Machine) über Objekte hinaus Daten austauschen müssen. Ich persönlich rate davon ab,
Informationen massiv über statische Variablen zu verteilen, da der Gültigkeitsbereich dieser Variable nicht durch unser Programm, sondern über die Laufzeitumgebung bestimmt ist. Wenn wir bspw. ein Programm zweimal parallel
starten, so startet Java zwei Laufzeitumgebungen. Wenn nun in einer der Wert geändert wird, gilt dies nicht für die zweite Umgebung. Auf Servern kann sichim Rahmen von HTTP Verarbeitung durch Servlets die Situation jedoch anders
darstellen, was zu merkwürdigen Verhaltensweisen führen kann. Bei statischen Methoden wiederum muss man aufpassen, dass wir keinen Zugriff auf eine nicht statische Variable (also Instanzvariablen) implementieren. Eine
statische Methode muss ja ohne dem Objekt funktionieren. Wenn also kein Objekt instanziiert wurde, gibt es auch keine Instanzvariable. Grundsätzlich kann man aber genau daran erkennen, ob eine Methode nicht vielleicht als
statisch implementiert werden sollte, wenn sie keinerlei Zugriffe auf nicht statische Eigenschaften oder Methoden aufweist. Das Handling ist dann etwas einfacher, weil man hier ja kein Objekt instanziieren muss. Ein Beispiel
einer statischen Methode haben wir bereits bei den Datentypen kennengelernt, dem
String nach
Integer Inhalten parsen:
(6) Eigentlich nur im Rahmen des aktuellen Class Loaders
Listing 49: Aufruf einer statischen Methode
Kurze Erklärung der Codezeilen: Die Methode
parseInt() übernimmt den Stringparameter und konvertiert ihn wenn möglich in eine
int Zahl. Hier wird keinerlei Zugriff auf irgendwelche Instanzvariablen der
Integer Klasse benötigt. Insofern wurde die Methode statisch implementiert. Der Aufruf erfolgt sinnvollerweise nicht über eine Variable in der ein Objekt steckt – da wir kein Objekt benötigen, sondern direkt über den Klassennamen
Integer.
Package – zusammen, was zusammen gehört
Soweit zu den grundsätzlichen Ideen der objektorientierten Programmiersprachen. Bevor wir nun einen kurzen Blick auf die anderen Programmiersprachen werfen, müssen wir noch einen Begriff dazwischensetzen, welcher zwar kein reines
objektorientiertes Thema darstellt, dort aber eine zentrale Bedeutung hat, die „Namespaces“ oder zu Deutsch „Namensräume“. Wir haben ja gesehen, dass wir unsere Klassen mehr oder weniger beliebig benennen können. Die Frage ist nun
was passiert, wenn zwei Entwickler sich jeweils für eine ihrer Klassen den gleichen Namen ausgesucht haben? Wie können wir in solch einem Fall diese beiden Namen unterscheiden? Hier greift nun der Gedanke des Namespaces. In Java
sind diese sehr eng mit den Paketen verknüpft – sprich die Namespaces definieren sich durch die Paketstrukturen. In unserem Programm haben wir die Geometrieklassen in das Paket
mygraphs gepackt und das Interface
MyLogger in das Paket
mylogger – sprich wir haben für unsere weiteren Untersuchungen schon zwei Pakete. Gehen wir nun mal davon aus, dass wir jeweils in beiden Paketen die Klasse
„ConsoleLogger“ einfügen wollen, welche lediglich die statische Methode
„logToConsole“ hat. Ich habe die Methoden statisch realisiert, damit wir kein Objekt instanziieren müssen und somit der Testcode schlanker wird. Wenn wir vorab zwar wissen, dass es bereits eine Klasse mit dem gleichen Namen in dem
Projekt gibt, würden wir nicht auf die Idee kommen unsere Klasse genauso zu nennen. Aber es passiert durchaus mal, dass mehrere Projekte und Bibliotheken zusammengefasst werden und solche Namensgleichheiten zufällig auftreten.
Insofern ist unser theoretisches Beispiel hier durchaus nicht komplett aus der Luft gegriffen. Die Frage ist nun, wie können wir die beiden Klassen voneinander unterscheiden? Hierfür erzeugen wir erstmal die neuen Klassen:
Listing 50: Beispielklasse mit einfacher Methode im package mygraphs
Und das gleiche machen wir nun auch im package mylogger:
Listing 51: Beispielklasse mit einfacher Methode im package mygraphs
Zur Unterscheidung geben die beiden Methoden noch einen Hinweis auf ihr Paket aus. Nun greifen wir in der Main Methode auf die beiden Klassen und deren statischen Methoden zu und testen das Ganze:
Listing 52: Testcode für den Zugriff auf Namespaces
Kurze Erklärung der Codezeilen: Ich habe hier auf die
import Statements verzichtet (wenn mit VSCode gearbeitet wird und alles in einem Projekt zusammengefasst wurde, muss darüberhinaus noch der Gesamtpfad
hinterlegt werden). Um nun auf den
ConsoleLogger des
mygraphs Paktes zuzugreifen, muss man den Paketnamen mit einem Punkt vor die Klasse schreiben. Sollten die Pakete Unterordner aufweisen, werden diese ebenfalls durch Punkte getrennt.
Wenn wir den Code ausführen, sehen wir:
In den vorausgegangenen Listings konnten wir jeweils mit Hilfe des import Statements auf die explizite Angabe des Pakets bei der Klassennutzung verzichten. Dies geht allerdings nur dann, wenn wir keine
Namensgleichheit haben. Wenn wir nun die Klasse
ConsoleLogger des Paktes
mygraph in unserem Code relativ häufig nutzen und die Klasse in
mylogger eher selten, könnten wir nur
mygraph importieren und die explizite Angabe entfernen:
Listing 53: Testcode für den Zugriff auf Namespaces mit import
Wenn wir allerdings beide Pakete importieren, dann müssten wir beim Zugriff auf
ConsoleLogger wieder explizite Angaben machen, da der Compiler nicht weiß, welche der beiden Klassen wir meinen. Die Paktenamen bilden also die Namespaces, wodurch wir Eindeutigkeit bei den
Zugriffen erlangen. Es liegt zwar nun wieder an uns, diese Paktestrukturen selbst zu benennen – hier haben sich aber ein paar Grundregeln etabliert, wenn wir den Programmcode anderen Personen zur Verfügung stellen möchten.
Der wichtigste Punkt ist die Eindeutigkeit. Da (fast) alle Firmen, welche professionellen Code produzieren, einen Webauftritt und somit eine eindeutige Webadresse haben, orientieren wir uns an der URL. Die Pakete legen wir
nun in Unterstrukturen an und setzen die Ordnersturktur basierend auf der URL in folgender Form um:
URL: www.codeconcert.de
Projektname: buchprojekt
Teilpaket: grafikbeispiel
Paketname: de.codeconcert.buchprojekt.grafikbeispiel
Projektname: buchprojekt
Teilpaket: grafikbeispiel
Paketname: de.codeconcert.buchprojekt.grafikbeispiel
Generics – bloß nicht festlegen
Bevor wir uns auf die Syntaxdetails der einzelnen Programmiersprachen stürzen, gehen wir noch kurz auf eine Konsequenz von statisch typisierten Programmiersprachen ein. Hierfür erinnern wir uns nochmal an dynamische Arras in Java, den
„ArrayList“ Objekten aus
Kapitel 7. Wir wollen nun diese Klasse „nachbauen“, um das Konzept von Generics zu verstehen. Eine
ArrayList ist ein Objekt, welches intern ein Array vorsieht (daher der Name), welches bei Bedarf erweitert werden kann. Hierbei haben wir folgende Methoden dieser Klasse kennengelernt:
- „ArrayList“ als Konstruktor für die Vorbereitung der inneren Datenhaltung.
- „add(newElement)“, welche das Element newElement hinten anstellt und ggf. das interne Ar-ray erweitert.
- „add(position, newElement)“, welche an position das newElement einfügt und alle ande-ren Elemente um eins nach hinten schiebt.
- „set(position, newElement)“ ersetzt an der gegebenen position das Element mit newEle-ment.
- „remove(position)“ löscht an position das Element und schiebt alle folgenden Element um eins nach vorne.
- „size()“ gibt die Anzahl der Elemente zurück.
- „get(position)“ gibt das Element an der Position position zurück.
Beginnen wir mit der internen Datenhaltung. Wir benötigen ein Array vom Typ
„Object“, damit wir nicht für jedes Objekt einer anderen Klasse eine eigene
„MyArrayList“ bauen müssen. Weiterhin wird die Anzahl der bereits gesetzten Objekte benötigt:
Listing 54: Grundgerüst für MyArrayList in Java
Als nächstes erstellen wir eine Methode, welche das Array um 10 Elemente erweitert. Hierzu müssen wir ein neues, entsprechend vergrößertes Array erzeugen, die Daten umkopieren und dieses dann anstelle des alten Arrays platzieren:
Listing 55: Hilfsmethode für die Erweiterung des inneren Arrays in Java
Nun können wir die
add und
set Methoden realisieren. Bei
„add“ müssen wir zuerst von rechts nach links bis zur gewünschten Position alle Elemente um eins nach rechts schieben. Hierzu beginnen wir bei
„size“, was ja der erste freie Platz im Array ist, da das Array von 0 bis size-1 belegt ist und übernehmen jeweils den links stehenden Wert. Sollte das Array jedoch zu klein sein (also wenn das
innerArray die Größe von
size hat), müssen wir es mit einem Aufruf von
increaseSize() erweitern. Die set Methode setzt einfach nur den Übergabewert an die gewünschte Position des
innerArray.
Listing 56: Implementierung für „add“ und „set“ in Java
Nun fehlen noch
size(), was einfach nur ein Getter für die Variable
size ist und
remove. Bei
remove gehen wir genau umgekehrt wie in
add vor, indem wir von
position ausgehend das jeweils rechte Element um eins nach links schieben. Am Schluss setzen wir das letzte Element auf
null, da es sonst doppelt referenziert wird.
Listing 57: Implementierung für „size“ und „remove“ in Java
Die letzte – und für das Thema „Generics“ wichtigste – Methode ist
get, welche von der gegebenen Position das Element zurückgibt. Da wir intern das Array vom Typ
„Object[]“ implementiert haben, muss die
get Methode auch ein Element vom Typ
„Object“ zurückgeben:
Listing 58: Implementierung für „get“ in Java
Nun können wir unser Programm genauso testen, wie in
Kapitel 7. Hierzu übernehmen wir 1:1 den Code und tauschen
ArrayList<String> bzw.
ArrayList<> mit
MyArrayList aus:
Listing 59: Test unsere MyArrayList Klasse
Soweit ist also alles erstmal gut. Nun haben wir jedoch ein Problem. Wenn wir bspw. in der ersten Ausgabezeile den Code
myList.get(1) in
myList.get(1).toUpperCase() ändern, erhalten wir einen Compilerfehler! Bei statisch typisierten Programmiersprachen müssen die angewendeten Methoden zum Datentyp der Variablen passen – anders
wie bei den dynamisch typisierten Skriptsprachen, in denen wir mangels Datentyp der Variablen, die Methoden auf den Datentyp des Objektes anwenden. Um nun doch
„toUpperCase“ anwenden zu können, müssten wir einen Typecast einbauen:
((String)myList.get(1)).toUpperCase()
Das widerspricht aber dem Grundgedanken von statischer Typisierung. Als Programmierer möchte ich mir nicht merken müssen, von welcher Klasse die verarbeiteten Objekte nun sind.
Genau diese Information möchte man nun als „Klassenparameter“ in die Definition unserer Klasse einbauen, welche durch die spitzen Klammern bei der Deklaration der Variablen für
MyArrayList eingetragen werden soll. Sehen wir uns hierzu die angepasste Klassendeklaration und die get Methode an:
Listing 60: Implementierung eines Typparameters in einer Klasse in Java
Kurze Erklärung der Codezeilen: Die Klassendeklaration wird um
<ParType> ergänzt – also einem Parameter, welcher einen Datentyp übergibt. Der Name des Parameters kann wie jeder andere Variablenname gewählt werden, wobei man ihn in Java
gemäß der Konvention, Klassen in Großbuchstaben zu benennen, auch groß schreibt. Benötigt man mehrere Klassentypen als Parameter, so kann man diese per Komma trennen. Nun können wir intern mit
ParType genauso arbeiten, wie mit jeder anderer Klasse auch (mit Ausnahme von speicherallokierenden Funktionalitäten wie bspw. dem Anlegen von Arrays – hier müssen wir bei
Object[] bleiben). Die Methode
get() wird nun so ergänzt, dass sie den Datentyp
ParType zurückgibt, weshalb wir beim
return Statement den Typecast auf
ParType durchführen müssen. Der Einfachheit verzichten wir auf eine Typüberprüfung und ignorieren das Warning. Wenn wir nun die Klasse für eine Variablendeklaration nutzen, können wir einen
Klassennamen als Parameter hinterlegen. Wollen wir bspw.
String in
MyArrayList verarbeiten, so würden wir schreiben:
MyArrayList<String> myList = new MyArray-List<>(); wodurch intern in der Klasse
ParType durch
String ersetzt wird. Der notwendige Typecast, wie wir ihn weiter oben für
toUpperCase() benötigt haben, fällt dadurch weg.
Hinweis: Bis jetzt habe ich den parameter für den Klassentyp
„ParTyp“ genannt, um den Sinn dieses Parameters hervorzuheben. Dieser Name ist aber eher unüblich – im Regelfall wird er mit
„T“ benannt, weshalb ich mich ab jetzt auch an diese Konvention halte. Sehen wir uns das Ganze mal in C# an. Die Grundidee ist erstmal die gleiche – wir parametrieren einfach die Klasse.
Im Gegensatz zu Java, können wir hier auch ein Array vom Typ
ParType erzeugen, weshalb wir auf das Array vom Typ
object verzichten:
Listing 61: Implementierung eines Typparameters in einer Klasse in C#
Kurze Erklärung der Codezeilen: Der Code ist größtenteils identisch mit Java. Lediglich die Nutzung von
Object wurde durch die direkte Nutzung von
T ersetzt. Dadurch ändert sich in gewissen Grenzen das Verhalten von Arrays, weshalb wir hier anstatt auf
„Length“, auf
Count() umstellen müssen. Dadurch, dass das innere Array nun gleich vom Typ
T ist, können wir bei der
get() Methode auf den Typecast verzichten.
Beim Konstruktoraufruf müssen wir im Gegensatz zu Java den Typparameter nicht nur bei der Variable, sondern auch beim Konstruktor eintragen:
MyArrayList<string> myList = new MyArrayList<string>();
An dieser Stelle könnten wir noch auf C++ eingehen – da die Generics hier aufgrund der komplizierteren Speicherverwaltung etwas aufwändiger sind und dies meines Erachtens den Scope dieses Buches sprengen würde,
verzichte ich hier auf eine nähere Betrachtungsweise von C++. Wer sich hier trotzdem ein Bild machen möchte, sollte sich das Thema „Generics“ und „Templates“ für C++ in den diversen Internetquellen näher ansehen.
Syntaxüberblick
Da wir die einzelnen Elemente und Konzepte bis jetzt auf Basis von Java Code kennengelernt haben, sehen wir uns nun die Syntaxvarianten der anderen objektorientierten Programmiersprachen an.
Nachdem manche Programmiersprachen extrem viele „Extras“ anbieten – allen voran C# - könnte man dieses Kapitel noch ewig fortführen. Ziel dieses Buches ist es aber nicht, alle Programmiersprachen vollumfänglich zu
dokumentieren, sondern vielmehr die grundsätzlichen Ideen und Konzepte aufzuzeigen und diese anhand der wichtigsten Sprachen zu demonstrieren. Insofern sind die folgenden Ausführungen als grober Überblick und nicht
als vollständige Aufstellung zu verstehen. Die Syntaxspezifikationen werden tabellarisch aufgeführt und eventuelle „Spezialfälle“ danach noch mit aufgenommen.
Java
Damit der Vergleich zu Java möglichst einfach durchzuführen ist, wird der Java Syntax auf die gleiche Art nochmal wiederholt:
| Was? | Wie? | Bemerkung |
|---|---|---|
| Klassendefinition | public class Kreis { } |
Klassen müssen je in einem eigenen File liegen (außer nested Classes). |
| Erweitern | public class Kreis extends ZweiDElm { } |
Es gibt keine Mehrfachvererbung. |
| Klasse versiegeln | public final class Kreis { } |
|
| Abstrakte Klasse | abstract public class Kreis extends ZweiDElm { } | |
| Abstrakte Methode | abstract void berechneUmfang(); | |
| Konstruktor | public Kreis (int rf, int ff, double radius) { … } |
Standardkonstruktor existiert immer. Es dürfen mehrere Konstruktoren existieren. |
| Superkonstruktor | public Kreis (int rf, int ff, double radius) { super(rf, ff); } |
Der Superkonstruktoraufruf muss an erster Stelle des Konstruktorcodes stehen. |
| Überschreiben | public void berechneUmfang() { … } |
Es muss lediglich die Signatur übereinstimmen. Mit final wird dies unterbunden. |
| Interfacedefinition | public interface Jsonifyable { public String getJsonString(); } |
Muss ebenfalls in einem eigenen File stehen. |
| IF Implementierung | public class Kreis implements Jsonifyable { … } |
Es können mehrere Interfaces gleichzeitig implementiert werden (kommasepariert). |
| Anonyme Klasse | Jsonifyable myObj = new Jsonifyable() { … }; |
Methoden des Interfaces müssen komplett umgesetzt werden. |
| Statische Elemente | static public void doSth() { … } |
Ist für Methoden und Eigenschaften möglich. |
| Konstanten | final float MY_PI = 3.14; | |
| Selbstreferenz | this.radius | |
| Referenz | myObject.setRadius(1.0); | |
| Elternreferenz | super.umfang | |
| Namensraum | package myproject; | Referenziert wird über import. |
| Destruktor | Werden nicht unterstützt (bzw. sind nicht notwendig). |
Tabelle 6: Objektorientierte Sprachelemente von Java
C#
Sehen wir uns nach Java einer der wichtigsten objektorientierten Programmiersprache an, nämlich C#:
| Was? | Wie? | Bemerkung |
|---|---|---|
| Klassendefinition | public class Kreis { } |
Klassen sollten je in einem File liegen, müssen aber nicht. |
| Erweitern | public class Kreis : ZweiDElm { } |
Es gibt keine Mehrfachvererbung. |
| Klasse versiegeln | public sealed class Kreis { } |
|
| Abstrakte Klasse | abstract public class Kreis extends ZweiDElm { } | |
| Abstrakte Methode | abstract void berechneUmfang(); | |
| Konstruktor | public Kreis (int rf, int ff, double radius) { … } |
Standardkonstruktor existiert immer. Es dürfen mehrere Konstruktoren existieren. |
| Superkonstruktor | public Kreis (int rf, int ff, double radius) : base(rf, ff);{ … } |
Die Superklasse heißt hier Basisklasse. |
| Überschreiben | public override void berechneUmfang() { … } |
Ohne override gibt es ein Warning bzw. Fehler. Die 1. überschriebene Methode der Vererbungskette muss virutal sein. Mit zusätzlich sealed wird weiteres Überschreiben verhindert. |
| Interfacedefinition | public interface Jsonifyable { public String getJsonString(); } |
Sollte in einem eigenen File stehen. |
| IF Implementierung | public class Kreis : Jsonifyable { … } |
Gleicher Syntax wie Erweiterung, bei mehreren Interfaces kommasepariert. |
| Anonyme Klasse | Wird nicht unterstützt. | |
| Statische Elemente | static public void doSth() { … } |
Ist für Methoden und Eigenschaften möglich. |
| Konstanten | const float MY_PI = 3.14; | |
| Selbstreferenz | this.radius | |
| Referenz | myObject.setRadius(1.0); | |
| Elternreferenz | base.umfang | |
| Namensraum | namespace myproject { public class MyClass { … } } |
Referenziert wird über using. |
| Destruktor | Werden nicht unterstützt (bzw. sind nicht notwendig). |
Tabelle 7: Objektorientierte Sprachelemente von C#
Besonderheiten von C#:
C# bietet einen ganzen Strauß an „Besonderheiten“, welche von der mehr oder weniger „reinen Lehre“ objektorientierter Ansätze abweichen bzw. sie ergänzen sollen.
Von allen diesen Besonderheiten sticht zumindest auf den ersten Blick eine Sache besonders im täglichen Gebrauch heraus. Die intensive Nutzung von Getter- und Settermethoden hat die C# Entwickler dazu bewegt,
die Getter- und Setterdefinition zu vereinfachen. Im folgenden Beispiel werden die beiden Variablen
laenge und
breite zwar
„public“ deklariert, allerdings automatisch Getter und Settermethoden generiert:
Listing 62: Automatische Getter- und Settergenerierung
Kurze Erklärung der Codezeilen: Trotzdem laenge und breite als public deklariert sind, werden sie vom Compiler als „private“ Variablen erzeugt. Bspw. wird aus
public double breite {get; protected set;}
folgender Code kompiliert:
private double breite;
public double getBreite() { return breite;}
protected void setBreite(double breite) {this.breite = breite;}
public double breite {get; protected set;}
folgender Code kompiliert:
private double breite;
public double getBreite() { return breite;}
protected void setBreite(double breite) {this.breite = breite;}
Hiermit wird der Vorteil gerade von Settern im Sinne der Kontrolle im Rahmen von Programmen jedoch etwas ad absurdum geführt, da wir ja keine Kontrolle des eigentlichen Codes haben.
Um nun doch wieder einen eigenen Settercode zu realisieren, können wir folgenden Syntax verwenden:
Listing 63: Automatische Getter- und Setter mit custom Code
Kurze Erklärung der Codezeilen: Die
private Instanzvariable wird nun mit einem Kleinbuchstaben am Anfnag notiert. Der Getter/Setterbereich wiederum groß. Nun können wir, ohne die beiden Methodensignaturen
explizit zu notieren, die Getter- und Settermethode lediglich als „Rumpf“ implementieren. Die Zuweisung erfolgt nun über die
private Instanzvariable
breite und der Parameter des Setters ist standardmäßig
value. Manchen Entwicklern passt jedoch die Nutzung von Klein/Großbuchstaben nicht in ihre Namenskonventionen, weshalb sie die
private Instanzvariable mit einem Unterstrich beginnen (also
_breite) und den Getter/Setterbereich mit einem Kleinbuchstaben beginnen. Wichtig ist aus Syntaxsicht lediglich, dass sie unterschiedlich sind.
Nun mag man fragen, was das eigentlich soll – schließlich haben wir nun im Vergleich zur klassischen Notation keinen Code wirklich gespart. Der Unterschied liegt nun darin,
dass C# den Lese- und Schreibzugriff auf diese Methoden nun ebenfalls „versteckt“. Wenn wir im Hauptprogramm nun die Breite mit -3 setzen wollen, können wir das mit folgendem
Code realisieren:
Listing 64: Setzen der Breite mit fehlerhaften Wert
Lassen wir den Code nun laufen, sehen wir auf der Konsole:
Das bedeutet, dass C# trotz einer „normalen“ Zuweisung über den Setter geht. Nun mag der eine das als Erleichterung im Code verstehen und der andere als ein Verstecken des eigentlichen Geschehens –
insofern muss hier wieder jeder für sich selbst entscheiden, ob er diesen Weg geht oder nicht.
Ein weiterer auffälliger Unterschied zu Java ist, dass Methoden, welche überschrieben werden dürfen, mit
virtual gekennzeichnet werden müssen. Wenn also Klasse A eine Methode vorsieht (die nicht abstrakt ist), darf sie von einer Kindklasse B nur überschrieben werden,
wenn sie
„virtual“ ist. Wenn B nun von einer Kindklasse C erweitert wird und die Methode wiederum überschrieben wird, muss in B kein
virtual stehen. Sollte die Überschreibungskette unterbrochen werden, muss bei der letzten möglichen Überschreibung
„sealed“ stehen.
C++
Die nächste wichtige objektorientierte Programmiersprache ist C++. Sie ist insofern wichtig, als dass sie nach wie vor für performante Implementierungen eine sehr gute Wahl ist und einer der ersten breit eingesetzten
objektorientierten Sprachen ist. Das soll aber nicht darüber hinwegtäuschen, dass im Vergleich zu Java und C# es auf jeden Fall aufwändiger und komplizierter ist, C++ zu lernen. Dies liegt natürlich an der Tatsache,
dass sich die Programmieransätze in den moderneren Sprachen weiterentwickelt haben. Hier wäre beispielsweise der gesamte Kompilierprozess, der bei mehreren zu kompilierenden Files diese sinnvoll zusammenfassen muss.
Während vor allem Java in diesem Punkt sehr unkritisch ist und der Compiler externe Abhängigkeiten sehr gut erkennt und auflöst und – noch wichtiger- bei der Ausführung der „Class Loader“ sich um die Konzertierung
der einzelnen Bausteine kümmert, müssen bei C++ viele Abhängigkeiten manuell in den „Buildprozess“ eingebaut werden, damit der „Linker“ die kompilierten Elemente zu einem File zusammensetzt.
In unserem Beispielcode für die Grafikelemente unter https://github.com/maikaicher/book1 habe ich bspw. den Compilerbefehl in einem eigenen Build.cmd hinterlegt. Das spiegelt zwar
immer noch nicht die Realität von „echten“ Projekten wieder, gibt aber schon mal einen kurzen Vorgeschmack. Aber auch, dass C++ sehr
viel „hardwarenäher“ ist und bspw. das Speichermanagement zum großen Teil „per Hand“ programmiert werden muss, schreckt viele Neulinge ab. Trotzdem ist es ganz hilfreich, sich das ein- oder andere Konzept in C++
anzusehen. Wer dann hier weitermachen möchte, dem empfehle ich dann die entsprechenden Tutorials im Netz, die recht umfangreichen Informationsseiten im Internet oder entsprechende Bücher, wie bspw.
„The C++ Programming Language“ von Bjarne Stroustrup.
| Was? | Wie? | Bemerkung |
|---|---|---|
| Klassendefinition | class Kreis { } |
Mehrere Klassen werden üblicherweise in einem File editiert. |
| Erweitern | class Kreis : public ZweiDElm, public MyClass { } |
Es gibt Mehrfachvererbung. Vererbungen können private sein, sind in der Regel aber public, sprich man kann auf die Elemente der Elternkasse zugreifen. |
| Klasse versiegeln | Wird nicht mit eigenem Keyword unterstützt. | |
| Abstrakte Klasse | Kann nur durch abstrakte Methoden geschehen – es gibt keine abstrakten Klassen ohne abstrakte Methoden. | |
| Abstrakte Methode | virtual void berechneUmfang(){}; | Geschweifte Klammern sind notwendig. |
| Konstruktor | Kreis (int rf, int ff, double radius) { … } |
Standardkonstruktor existiert immer. Es dürfen mehrere Konstruktoren existieren. |
| Superkonstruktor | public Kreis (int rf, int ff, double radius) : ZweiDElm(rf, ff);{ … } |
Die Superklasse(n) müssen benannt werden, es gibt kein „base“ oder „super“. |
| Überschreiben | public void berechneUmfang() { … } |
Es muss die Signatur übereinstimmen. |
| Interfacedefinition | Interfaces werden mit rein abstrakten Klassen realisiert. | |
| IF Implementierung | Wird nicht unterstützt. | |
| Anonyme Klasse | Wird nicht unterstützt. | |
| Statische Elemente | const static int version = 1; | Statische Variablen müssen konstant sein. |
| Konstanten | const float MY_PI = 3.14; | |
| Selbstreferenz | this->radius | |
| Referenz | myObject->setRadius(1.0); | |
| Elternreferenz | ZweiDElm::printInfo() | |
| Namensraum | Wird nicht unterstützt. | |
| Destruktor | ~Kreis() { … } |
Notwendig um allokierte Ressourcen wie-der freizugeben. Wird automatisch oder durch delete aufgerufen. |
Tabelle 8: Objektorientierte Sprachelemente von C++
Besonderheiten von C++:
Im Vergleich zu Java und C# macht aus Sicht des Syntax C++ relativ viel auf eine andere Art und Weise, wobei man bei einer zeitlichen Betrachtung sagen muss, dass es eigentlich andersherum ist. Java und C# haben viele
neue Ansätze im Vergleich zu C++ eingeführt. Wie auch bei C# gilt hier, dass ich nur auf einige wenige Details eingehen kann und werde. Die grundlegende Basis können wir hier aber schaffen. Auf die Notwendigkeit der manuellen
Speicherverwaltung bin ich ja schon zur Genüge eingegangen. In diesem Zusammenhang sei nochmal auf die Notwendigkeit des Destruktors hinweisen, welche bei den Programmiersprachen mit einem Garbage Collector nicht
vonnöten war. Eine weitere Besonderheit im Vergleich zu den neueren Sprachen ist die Möglichkeit, die Klassenstruktur unabhängig von der Implementierung zu formulieren. Somit können die Definitionen in ein eigenes
Header File ausgelagert werden. Dieses „Feature“ ist jedoch bei C++ zwingend notwendig, da die Verarbeitung beim kompilieren von Oben nach Unten erfolgt und somit die Klassen bzw. deren Eigenschaften und Methoden dem
Compiler vorab bekannt sein müssen, bevor er einen Aufruf verarbeiten kann. Sehen wir uns hierzu folgenden Code an:
Listing 65: Trennung von Klassendeklaration und Implementierung
Kurze Erklärung der Codezeilen: Ganz oben steht der Import, damit wir
cout verwenden können. Danach wird lediglich die Klasse spezifiziert. Hierbei sind nur die Instanzvariablen und Methodensignaturen samt Modifier notwendig. Diese müssen übrigens nicht vor jeder Variablen und Methode stehen.
Man kann nach
„public:“ auch mehrere Variablen hintereinander deklarieren, wodurch sie alle
public sind. Die Implementierung kann dann an einer beliebigen Stelle stehen. Wichtig ist, dass die Klassenspezifikation vor der Nutzung – in unserem Fall vor der Main Methode steht. Die Implementierung erfolgt in unserem Beispiel am
Ende. Da sie von der Spezifikation getrennt ist, muss nun für jede implementierte Methode die Klasse gefolgt von zwei Doppelpunkten angegeben werden. Die Spezifikation der Klassen kann auch in eigene „Headerfiles“ ausgelagert werden.
Damit ist es möglich, Spezifikation und Implementierung zu trennen. Wer sich dies ansehen möchte, kann unter
https://github.com/maikaicher/book1 die C++ Implementierung unseres Grafikprogramms ansehen. Dort wurde der Logger ausgelagert und in einem
Logger.h und
Logger.cpp File realisiert.
Noch ein Hinweis – die Objekte habe ich hier in einer Pointervariablen hinterlegt. Dies ist durchaus üblich. Es ist jedoch auch möglich, sie in eine normale Variable zu legen, wodurch der Konstruktoraufruf ohne das
new erfolgen würde. In der Grafikprogramm-Implementierung kann diese Variante eingesehen werden.
Nun ist es aber auch möglich, die Spezifikation und Implementierung in einem Bereich durchzuführen, wodurch dies natürlich wiederum vor der Nutzung erfolgen muss. Im Folgenden sehen wir die gleiche Funktionalität ohne getrennte
Spezifikation und Implementierung. Man erkennt, dass dies schon etwas näher an die Konzepte von Java und C++ erinnert:
Listing 66: Kombinierte Klassendeklaration und Implementierung
Soweit zu den C++ Besonderheiten, welche in diesem Rahmen sinnvoll zu besprechen wären.
PHP
Die nächste objektorientierte Sprache ist PHP. Sie wurde anfangs eher als prozedurale Sprache aufgesetzt, welche versuchte die C und Pearl Entwickler zu binden. Dies erklärt bspw. die explizite
„call by value“ und „call by reference“ Implementierung auf die bspw. Java und C# verzichtet. Später entwickelte man jedoch zunehmend objektorientierte Features hinzu. Die für Puristen mitunter als
„bunte“ Mischung aus objektorientierten und prozeduralen Features belächelte Vielfalt hat aber durchaus zur gesteigerten Beliebtheit von PHP für die serverseitige Webentwicklung geführt.
Die objektorientierten Umsetzungen bieten trotz allem mehr, als man beispielsweise von JavaScript erwarten kann. Insofern ist die Handhabung von PHP aus objektorientierter Sicht durchaus als „gewohnt“ zu
verstehen, wenn man davon absieht, dass einige Hilfsfunktionen nicht als statische Klassenmethoden umgesetzt wurden. Was dem ein oder anderen Programmierer aus der Welt von Java & Co. eventuell fehlt
sind die Überladungen. PHP kennt dies aufgrund der fehlenden Datentypen und der Möglichkeit Funktionen auf Variablen zuzuweisen nicht – dies haben wir bereits im
Kapitel 8 angesprochen. Wenn man jedoch durch die PHP Manuals blättert, findet man trotzdem den Begriff „überladen“ als Feature.
Dies gilt jedoch nur für die sogenannten „magischen Methoden“. Dies sind Methoden, welche implizit in PHP existieren und mitunter automatisch aufgerufen werden und immer mit zwei Unterstrichen beginnen.
Ein Beispiel ist der Konstruktor. PHP kennt, genauso wie bspw. Java den Standardkonstruktor, den wir nicht explizit schreiben müssen. Bei Instanziierung wird dieser automatisch aufgerufen. In PHP heißt dieser
Konstruktor nun nicht so wie die Klasse, sondern einfach nur
__constructor(); Diesen wiederum können wir nun überschreiben:
Listing 67: Überschreibung mit Überladung des Standardkonstruktors
Bis auf die Besonderheit, dass der Konstruktor
__construct() heißt, gibt es aus Sicht eines Java Entwicklers nichts auffallendes. Aus Sicht von PHP jedoch sehr wohl, da der implizit existierende Standardkonstruktor ja
__construct() heißt und unserer überschriebener Konstruktor zusätzlich mit einem neuen Parameter versehen – also nun doch „überladen“ wurde.
PHP kennt neben dem Konstruktor einige weitere „magische Methoden“ und ich werde hier nur noch auf eine weitere interessante, die
__call() Methode eingehen. Diese Methode wird immer dann aufgerufen, wenn für das Objekt ein nicht definierter Methodenaufruf erfolgt:
Listing 68: Überschreiben von __call()
Kurze Erklärung der Codezeilen: Das Objekt überschreibt die
__call() Methode. Hierbei müssen zwei Parameter existieren. Der erste wird mit dem Methodennamen des Aufrufes belegt. Im zweiten finden wir alle Aufrufparameter als Array. Beide Werte geben wir
hier lediglich mit
echo aus. Beim Objekt
$myObj wird nun die nicht vorhandene Methode
doSomething() mit dem Parameter „hello“ aufgerufen.
Die Ausgabe erfolgt dann erwartungsgemäß:
Mit diesem Konstrukt können wir nun – wenn auch etwas umständlicher – eine Art Überladungsverhalten realisieren. Alle weiteren in diesem Rahmen relevanten Syntaxelemente für die Objektorientierung in PHP sind in der folgenden Tabelle.
| Was? | Wie? | Bemerkung |
|---|---|---|
| Klassendefinition | class Kreis { } |
Es werden oft mehrere Klassen in einem File formuliert. |
| Erweitern | class Kreis extends ZweiDElm { } |
Es gibt keine Mehrfachvererbung. |
| Klasse versiegeln | final class Kreis { } |
|
| Abstrakte Klasse | abstract class ZweiDElm { } |
|
| Abstrakte Methode | abstract public function berechneUmfang(); | Geschweifte Klammern sind notwendig. |
| Konstruktor | public function __construct ($rf, $ff, $radius) { … } |
Standardkonstruktor existiert immer. Es dürfen mehrere Konstruktoren existieren. |
| Superkonstruktor | public function __construct($rf, $ff, $radius) { parent::__construct($rf, $ff); … } } |
Der Superkonstruktoraufruf sollte an erster Stelle des Konstruktorcodes stehen. |
| Überschreiben | public void berechneUmfang() { … } |
Es muss die Signatur übereinstimmen. |
| Interfacedefinition | interface Jsonifyable { public function getJsonString(); } |
|
| IF Implementierung | public class Kreis implements Jsonifyable { … } |
Es können mehrere Interfaces gleichzeitig implementiert werden. Parameter sollten genauso benannt werden, wie im Interface. |
| Anonyme Klasse | Logger myObj = new class {…}; | Anonyme Klassen benötigen keine Methodenbeschreibung via Interface. |
| Statische Elemente | public static function doSth(){ … } |
Ist für Methoden und Eigenschaften möglich. Zugriff erfolgt über „::“Kreis::doSth(). |
| Konstanten | define("MY_PI", 3.14); | |
| Selbstreferenz | $this->radius | |
| Referenz | $myObject->setRadius(1.0); | |
| Elternreferenz | parent::printInfo() | |
| Namensraum | namespace mygraphs; | Auflösung:
…new \mygraphs\Kreis(…) oder: use mygraphs\Kreis as MyKreis; …new Kreis(…) |
| Destruktor | public function __destruct() { … } |
Wird bei Beendigung des Skripts oder bei Aufruf von unset($myObjVar); aufgerufen |
Tabelle 9: Objektorientierte Sprachelemente von PHP
Python
Python zählt wie PHP ebenfalls zu den dynamisch typisierten und nicht kompilierten Sprachen. Während PHP jedoch versucht, den klassischen Programmierern möglichst entgegenzukommen, hat dies in Python keine Priorität.
Beispielsweise sind Interfaces bei nicht typisierten Sprachen nicht wirklich sinnvoll einsetzbar, da wir hier ja eigentlich „nur“ die Struktur des zu erwarteten Objekts festlegen. Wir machen also eine Art Typisierung
des Objektes – und gleiches gilt natürlich auch für die Typecasts in Richtung Elternklassen um die Vorteile der Polymorphie auszunutzen. Wenn wir aber keine Typen haben, können wir auch keine Typecasts durchführen.
Wir wissen also basierend auf der Variablen nicht, welche Objekte wir vorfinden – da dies in Sprachen wie Java durch den Datentypen der Variable bestimmt wird. Das ist nun aber eine enorme Einschränkung! Die Lösung
dieses Dilemmas ist, dass bei nicht typisierten Skriptsprachen einfach niemand vorab prüft, ob die Methode überhaupt vorhanden ist. Wenn also eine aufgerufene Methode eines Objektes nicht existiert, wird zur Laufzeit
einfach ein Fehler erzeugt. Man nutzt also ein Objekt nicht nach seiner Definition, sondern einfach nur danach, welche Methoden vorhanden sind. Dieses Vorgehen nennt man auch „Ducktyping“, nach einem amerikanischen
Gedicht von James Whitcomb Riley: „When I see a bird that walks like a duck and swims like a duck and quacks like a duck, I call that bird a duck.“ – also die Eigenschaften und Methoden bestimmen den Typen, nicht
andersherum. Dies führt zwar dazu, dass Fehler mitunter erst zur Laufzeit gefunden werden können, aber auch zu einer erhöhten Flexibilität.
Weiterhin waren sich die Python Entwickler wohl ziemlich im Klaren darüber, dass Python eine Skriptsprache ist und somit eingebundene Bibliotheken jederzeit vom Entwickler abgeändert werden können. Somit haben die
Python Macher vermutlich keinen wirklichen Sinn mehr in solchen Dingen wie Zugriffsmodifikatoren gesehen. Wenn ich eine Klasse von einer Bibliothek nutze und mir der private Zugriffsmodifikator einer Variablen nicht passt,
kann mich niemand daran hindern, den Modifikator einfach auszutauschen. Also hat man einfach darauf verzichtet, die Zugriffsmodifikatoren in Python vorzusehen. Um den Code trotzdem in Bezug auf die Modifikatoren „lesbarer“
zu machen hat man einfach die Konvention eingeführt, private mit zwei und protected mit einem Unterstrich vor der Variable zu markieren. Dies hat – wie oben bereits erwähnt – zwar keinerlei Einfluss auf das Zugriffsverhalten,
zeigt aber dem Nutzer von Klassen, welche Variable wofür gedacht ist.
Ein weiterer Punkt bei den objektorientierten Elementen von Python ist – wie bei Python ja häufig – der reduzierte Ansatz was Codeelemente angeht. Sehen wir uns hierzu mal zwei Klassen an, bei denen eine von der anderen erbt:
Listing 69: Klassendefinition und Instanziierung in Python
Wir sehen hier bekannte Konzepte wieder. Python verzichtet weitestgehend auf geschweifte Klammern, welche durch Einrückungen ersetzt werden. Der Konstruktor heißt in Python
__init__(). Erweiterungen kommen lediglich in eine Klammer nach dem Klassennamen – hier dürfen auch mehrere Elternklassen stehen – Python unterstützt Mehrfachvererbung. Die Elternklasse wird als
„super“ bezeichnet, wobei wir hier über eine Methode
„super()“ auf die Elternklassenelemente zugreifen. Wenn wir mehrere Elternklassen haben, sucht
super().Methode() die Elternklassen von links nach rechts ab, bis eine passende Methode
„Methode()“ gefunden wurde. Was weiterhin auffällt ist, dass Python nicht
„this“ kennt, sondern dies als
„self“ bezeichnet. Da diese Selbstreferenz jedoch bei jeder Instanzmethode in der Parameterliste am Anfang steht, könnten wir sie theoretisch auch anders bezeichnen – wovon aus Übersichtsgründen aber abzuraten ist.
Der Pythoninterpreter schreibt also automatisch bei jedem Methodenaufruf am Anfang der Parameterliste die Referenz des eigenen Objektes hinein. Dies ist auf jeden Fall für „nicht Python Entwickler“ ungewohnt.
Dieses „self“ hat nun noch eine wichtige Eigenschaft. Instanzvariablen werden immer mit dem
„self“ Keyword definiert. Wir erzeugen diese Variablen auch nicht außerhalb der Methoden, sondern innerhalb. Theoretisch geht das in jeder beliebigen Methode, wobei ich aber empfehle, dies im
Konstruktor zu tun – sprich die erstmalige Erzeugung und Initialisierung der Variablen im Konstruktor durchzuführen, womit man die Garantie hat, dass sie mit einem definierten Wert existieren.
Hier ist noch ein kleiner Hinweis auf Python sinnvoll. Python kennt den Zustand
„null“ nicht, sondern nutzt
„None“ – was lediglich ein „Markerobjekt“ für „nicht definiert“ ist. Dies bringt mit sich, dass es explizit gesetzt werden muss. Eine Variablendeklaration in Python ist immer mit einer Zuweisung verbunden – wenn ich also eine Variable
ohne Inhalt erzeugen muss, dann muss ich das eben definieren mit
myVar = None.
Ungewohnt ist auch, dass Python auf das Schlüsselwort
„new“ verzichtet, sondern der Aufruf des Konstruktors ausreicht. Dies ist vor dem Hintergrund des Verzichts auf alles „nicht zwingend Notwendige“ allerdings konsequent.
Bei abstrakten Klassen müssen wir in Python einen bis jetzt ungewohnten Weg gehen. Für Abstraktionen hat Python ein Modul namens
„abc“ (Abstract Base Class) geschaffen. Wenn wir nun eine abstrakte Klasse benötigen, so erben wir von der
ABCMeta Klasse über den Zusatz
„metaclass=ABCMeta“). Mit dem „Dekorierer“
@abc.abstractmethod über einer Methode verhindern wir nun, dass die entsprechende Methode direkt aufgerufen wird. Wenn dieser nun vor dem Konstruktor steht, ist die Klasse damit nicht mehr instanziierbar.
Listing 70: Abstrakte Klasse in Python
Fehlt dieser Dekorierer, dann können wir die Klasse instanziieren. Wir könnten aber theoretisch diesen Dekorierer auch über jede beliebige Methode schreiben, was auch zur Verhinderung der Instanziierung führt. Anders als
bspw. in Java können wir aber als abstrakt geflaggte Methoden durchaus mit Funktionalität belegen. Diese Funktionalität können wir somit lediglich über den
super() Aufruf nutzen:
Kurze Erklärung der Codezeilen: Die Klasse
GarikElm ist abstrakt, da sie
ABCMeta erweitert und eine abstrakte Methode
printInfo() aufweist. Diese Methode hat jedoch einen Rumpf und somit Funktionalität. In der Kindklasse kann nun diese über
super().printInfo() aufgerufen werden. Da in Python jedoch jede Methode einen Rumpf benötigt, müssen wir bei abstrakten Methoden ohne jegliche Funktionalität mindestens
„return“ eintragen.
| Was? | Wie? | Bemerkung |
|---|---|---|
| Klassendefinition | class Kreis: … |
Es werden oft mehrere Klassen in einem File formuliert. Klassenelemente müssen vier Spaces nach rechts eingerückt stehen. |
| Erweitern | class Kreis(ZweiDElm): … |
Es gibt Mehrfachvererbung (kommasepariert). |
| Klasse versiegeln | Nur über Workarounds machbar und in einer Skriptsprache eigentlich nicht sinnvoll. | |
| Abstrakte Klasse | @abc.abstractmethod def __init__(self, …): |
Details siehe oben. |
| Abstrakte Methode | @abc.abstractmethod | Details siehe oben. |
| Konstruktor | def __init__(self, randfarbe): … |
Standardkonstruktor existiert immer. Es darf nur ein Konstruktor formuliert werden. |
| Superkonstruktor | def __init__(self, randfarbe): super().__init__(randfarbe) … |
Der Superkonstruktoraufruf sollte an erster Stelle des Konstruktorcodes stehen. Bei mehreren Elternklassen „super()“ durch Elternklassenname ersetzen. |
| Überschreiben | def printInfo(self): | Es muss die Signatur übereinstimmen. |
| Interfacedefinition | Wird nicht unterstützt, bzw. muss als abs-trakte Klasse erfolgen. | |
| IF Implementierung | Über Mehrfachvererbung von abstrakten Klassen möglich. | |
| Anonyme Klasse | Wird eigentlich nicht unterstützt, es gibt aber die Möglichkeit über type(name, bases, dict) Funktion. | |
| Statische Elemente | @staticmethod def doSomething(): … |
Der Decorator sorgt dafür, dass „self“ nicht als Parameter akzeptiert wird. Dadurch sind keine Referenzen auf Instanzvariablen und Methoden mehr möglich. |
| Konstanten | Wird nicht unterstützt – es gilt die Konvention: Wenn nur Großbuchstaben verwendet werden, soll die Variable nicht neu belegt werden. | |
| Selbstreferenz | self.breiteradius | Nur, wenn „self“ in Parameterliste so genannt wurde. |
| Referenz | myObject.setBreite(1.0); | |
| Elternreferenz | super().umfang | |
| Namensraum | import mygraphs.MyClasses as myg | Namensräume werden durch die Datei („Modul“) gebildet. Beim Import kann ein individueller Name (bspw. myg) vergeben werden. Zugriff erfolgt dann über myg.GrafikElm |
| Destruktor | def __del__(): … |
Wird aufgerufen, wenn keine Referenz auf das Objekt mehr existiert. aufgerufen |
Tabelle 10: Objektorientierte Sprachelemente von Python
JavaScript
Kommen wir zum nächsten Kandidaten in unserer objektorientierten Sprachsammlung, nämlich JavaScript (bzw. ECMA Script). Diese Sprache unterscheidet sich in puncto Objektorientierung wesentlich von den bisher besprochenen Sprachen
C++, C# und Java. Kennen diese Sprachen das Konzept einer Klasse – sprich dem Plan eines Objektes, welches zu instanziieren gilt, gibt es soetwas in JavaScript nicht! Wir werden zwar das Schlüsselwort
„class“ kennenlernen, welches aber ein eher jüngeres Konstrukt im Rahmen von ES6 eingeführt wurde und lediglich zur besseren „Akzeptanz“ dieser Sprache führen soll. Hiermit wird das Konzept der Klasse lediglich
„simuliert“(7). JavaScript gehört nämlich zu den prototypbasierten Programmiersprachen. Dies bedeutet vereinfacht gesagt, dass man nicht eine Klasse erstellt und aus dieser die Objekte erzeugt, sondern
dass man ein Objekt erzeugt und dieser dann zu einem neuen Objekt geklont wird (wodurch der geklonte Teil des Elternobjekts zum Prototypen des Kindobjektes wird). In diesem Klonvorgang kann man dann wieder neue Eigenschaften und
Methoden hinzufügen. Dadurch können solche Konzepte wie abstrakte Klassen und Interfaces nicht Teil dieser Sprache sein.
Syntaktische Erweiterungen zur einfacheren Handhabung, welche jedoch das dahinterliegende Grundprinzip nicht ändern, nennt man auch „syntaktischer Zucker“
Da JavaScript ständig weiterentwickelt wird um die Flexibilität und Nutzbarkeit zu erhöhen, gibt es für viele Techniken mehrere Wege, diese zu implementieren. Dies ist vor allem für Neueinsteiger meist verwirrend. Liest man
sich zu verschiedenen Aufgaben unterschiedliche Tutorials durch kann es sein, dass jedes Tutorial einen anderen Weg für das gleiche Ergebnis geht. Da der Ansatz von JavaScript ziemlich von dem der klassischen Objektorientierung
abweicht, gehe ich hier etwas intensiver auf die Konzepte ein. Sehen wir uns mal verschiedene Wege zur Erzeugung eines Objektes an und beginnen mit der „klassischen“ Variante, welche schon sehr früh von JavaScript unterstützt wurde.
Diese ähnelt sehr des Konzepts der anonymen Klasse von Java, wo wir ein Objekt ohne Klasse erzeugt haben. Da Java aber kompiliert wird, mussten wir die Klassenstruktur in einem Interface vorab hinterlegen, was bei JavaScript als
zur Laufzeit interpretierten Sprache nicht notwendig ist:
Listing 72: Klassische Objekterzeugung in JavaScript
Kurze Erklärung der Codezeilen: Die Variable myObject wurde anstatt mit
let oder
var, mit
const deklariert, was bedeutet, wir können ihr keinen anderen Wert mehr zuweisen. Wenn wir also irgendwo
myObject = 2; schreiben würden, erhalten wir einen Laufzeitfehler. Da wir üblicherweise Objekte nicht neu belegen, ist
const hier sinnvoller als
let oder
var. Die einzelnen Instanzvariablen wie bspw.
myName werden über einen Doppelpunkt direkt mit einem Wert zugewiesen. Aus diesem Grund wird (erstmal) kein Konstruktor benötigt. Die Funktionen werden ebenso mit Doppelpunkt und dem Schlüsselwort
function hinzugefügt – Funktionen werden in JavaScript ja genauso behandelt wie Objekte. Wenn wir nun innerhalb einer Funktion auf eine Instanzvariable zugreifen wollen, müssen wir immer das Schlüsselwort
this davor schreiben. Anders als in Java ist this hier also Pflicht. Das liegt im Wesentlichen daran, dass ausschließlich anhand
this erkannt wird, dass es sich um eine Instanzvariable handelt. Der Zugriff auf die Methoden und Eigenschaften eines Objektes erfolgt wie in Java über den Punktoperator.
Nun können wir jedoch einen alternativen Zugriff auf die Instanzvariablen eines Objektes umsetzen. Anstatt der Zeile
console.log(myObject.myName); können wir auch
console.log(myObject['myName']); schreiben. Die Objekte funktionieren also ähnlich einem assoziativen Array. Dies erklärt auch, warum wir zur Laufzeit dynamisch neue Instanzvariablen hinzufügen können. Wir ergänzen unseren Code aus
Listing 72 um folgenden Code:
Listing 73: Erweiterung des Objektes zur Laufzeit um eine Eigenschaft
Dies ist eine „Stärke“ von prototypbasierten Sprachen – sie sind sehr flexibel. Hartgesottene C++ Programmierer hingegen sehen diese Flexibilität als ein Einfallstor für unsaubere Codefragmente an, da es sehr
schwierig wird, die eigentliche Struktur eines Objektes irgendwo zentral zu begutachten. Aber gehen wir noch einen Schritt weiter! Wenn die Eigenschaften dynamisch erweiterbar sind, müssten es die Funktionen
nicht auch sein? Probieren wir es aus:
Listing 74: Erweiterung des Objektes zur Laufzeit um eine Methode
Objekte sind in JavaScript also hochdynamische Elemente, welche jederzeit angepasst werden können. Kommen wir hier aber nochmal auf einen wichtigen Aspekt der Skriptsprachen, welcher sich aus der fehlenden
Notwendigkeit der Deklarationen heraus ergibt. Sehen wir uns folgenden Code an und achten auf die Variable
innerText:
Listing 75: Globale Gültigkeit von Variablen
Wenn wir diesen Code laufen lassen, sehen wir auf der Konsole:
Die Variable
innerText ist also innerhalb und außerhalb des Objektes gültig, da sie einen globalen Charakter hat. Dies ist natürlich aus Sicht der Kapselung eine sehr unvorteilhafter Vorgehensweise. Aus diesem Grunde wurde
das uns bereits bekannte Schlüsselwort
„let“ bzw.
„var“ eingeführt, wodurch die Variable nun innerhalb der Funktion nochmal parallel erzeugt wird. Wenn wir also innerhalb der Funktion
var innerText = "Logging: "; schreiben, so sehen wir trotzdem als letzte Ausgabe "Äußerer Text". Neben
var kennt aber JavaScript ja noch
let, was bewirkt, dass die Variable innerhalb des Scopes nicht nochmal neu deklariert werden kann und den Scope nur bis innerhalb des Blocks setzt – also innerhalb der einschließenden geschweiften Klammern und
in unserem Fall bis zur schließenden geschweiften Klammer der Funktion. Dieses Verhalten wäre wie eine normale Deklaration einer lokalen Variablen in Java und sollte dem „var“ auf jeden Fall vorgezogen werden.
Sehen wir uns einen weiteren Weg an, Objekte zu erzeugen. Diesmal ausschließlich über einen Konstruktor:
Listing 76: Objekterzeugung via Konstruktor in JavaScript
Kurze Erklärung der Codezeilen: Wir definieren hier lediglich eine Funktion, welche ein Objekt erzeugt. Da diese Funktion somit einem Konstruktor gleichkommt, können wir sie auch gleich wie eine Klasse benennen.
Nun können wir das Objekt auch mit Hilfe von new erzeugen. Die restlichen Eigenschaften und Vorgehensweisen decken sich mit denen aus den vorausgegangenen Listings.
Das nächste Verfahren ein Objekt zu erzeugen ist durch die Nutzung des
„create“ Befehls des Standardobjekts Object.
Listing 77: Objekterzeugung via Object.create() in JavaScript
Die Deklaration der Klasse
MyClass ist wiederum nichts anderes als die Objektdeklaration aus
Listing 72. Dies ist deshalb einleuchtend, weil es in der prototypbasierten Sprache keine Klassen gibt. Wir behandeln im
Listing 77 das Objekt
MyClass lediglich wie eine Klasse. Prinzipiell können wir als Parameter der
create() Methode jedes Objekt eintragen. Wir erstellen somit einen „Klon“ des Objektes, den wir anschließend erweitern können, was wiederum einer Vererbung gleichkommt. Der Klon des Originalobjektes wird damit zur
„Elternklasse“ (oder hier besser zum Elternobjekt bzw. noch besser zum Prototypen) und der Rest des Klons zum Erweiterungsteil der Kindklasse. Intern löst dies JavaScript mit Listen, in denen die Eigenschaften
und Methoden eingetragen werden. Eine Liste existiert für die selbst erzeugten Eigenschaften und Methoden, eine für den Prototypen, eine für den Prototypen des Prototypen usw., bis kein Prototyp mehr vorhanden ist
(bzw. die Referenz auf den Prototypen
null ist).
Die letzte hier vorgestellte Methodik ist erst seit ES6 möglich. Hier hat man (zumindest aus Sicht des Syntax) ähnliche Methodiken vorgesehen wie bei den klassischen objektorientierten Sprachen wie C# oder Java,
wenngleich der interne Aufbau in JavaScript sich nicht verändert hat. Man kommt hier im Wesentlichen denjenigen entgegen, welche in diesen Sprachen das Programmieren gelernt haben. Sehen wir uns dies im Code an:
Listing 78: Objekterzeugung via Object.create() in JavaScript
Dieses Konstrukt erinnert am ehesten an die Konzepte von C# und Java. Sollte eine Methode einen Wert zurückgeben müssen, so wird dies auch mit
„return“ erledigt. Ansonsten ist zu beachten, dass mangels Deklaration die Instanzvariablen immer dann existieren, wenn sie mit
„this.“ belegt wurden und der Interpreter diese Stelle auch verarbeitet hat. Ergänzen wir bspw. die Methode
printValue() wie folgt:
Listing 79: Ergänzung um Instanzvariable in JavaScript
Wenn wir nun das Objekt erzeugen und vor dem Aufruf
myObject.printValue("Hello!"); versuchen auf
myObject.aValue zuzugreifen, ist der Inhalt nicht definiert. Rufen wir die
printValue() Methode jedoch vorher auf, existiert die Variable
aValue. Insofern ist es eine gute Idee, alle Instanzvariablen wie auch bei Python im Konstruktor erstmal festzulegen, oder sie wie im folgenden Beispiel als eine Art Instanzvariable zu platzieren:
Listing 80: Variableninitialisierung auf Objektebene
Gehen wir nun nochmal auf den Begriff des Prototypen ein. Die Idee ist, dass jede Klasse – genaugenom-men jeder Konstruktor – auf
eine Liste von Eigenschaften und Methoden eines sogenannten „Prototypen“ eine Referenz hat. Um dies zu verstehen, sehen wir
uns folgenden Code an:
Listing 81: Erzeugung von Objekten aus Vererbungshierarchie
Kurze Erklärung der Codezeilen: Der grundsätzliche Code sollte klar sein – wir erzeugen eine Elternklasse mit einer
Instanzvariablen
aValue und erweitern sie durch eine Kindklasse, welche eine weitere Instanzvariable
bValue ins Spiel bringt. Neu ist nun, dass wir nachträglich in der
ChildClass einen Prototypenwert
cValue definieren. Danach erzeugen wir zwei Objekte vom Typ
ChildClass und geben die drei Variablen
aValue,
bValue und
cValue aus.
Wir führen den Code aus und sehen die zugewiesenen Werte. Soweit ist erstmal nichts Besonderes am Code zu entdecken.
Nun ergänzen wir den Code um folgende Zeilen:
Listing 82: Manipulation des prototype Wertes
Bei der Ausgabe sehen wir nun:
Dies bedeutet, dass beide Objekte die gleiche prototype Eigenschaft
„cValue“ teilen. Gehen wir nun einen Schritt weiter und verändern bei
child1 das Attribut cValue:
Listing 83: Shadowing eines Prototypenwertes
Das Ergebnis mag jetzt auf den ersten Blick überraschen:
Was hier passiert ist Folgendes:
child1 und
child2 sind beide vom Typ
ChildClass. Diese Klasse wiederum hat die
prototype Eigenschaft
cValue. Mit dem Code
child1.cValue = 5 fügen wir nun eine weiter Eigenschaft mit dem Namen
cValue zu dem Objekt hinzu. Es existieren nun also zwei
cValue, eine vom Prototypen und eine vom Objekt. Beim Lesezugriff sucht nun der JavaScript Interpreter vom „nahen“ zum „fernen“ –
also er beginnt beim Objekt und sucht danach erst beim Prototypen. Da
child1 keine Instanzvariable
cValue, sondern nur die Prototyp Eigenschaft
cValue hat, wird hier noch die 4 ausgegeben. Dies ist eine Form der Überschreibung, welche man in JavaScript in Bezug auf den
Prototypen „shadowing“ nennt.
Gehen wir nun noch einen Schritt weiter. Die Prototypen werden ja weitervererbt. Wir können also nun bei der
ParentClass ebenfalls einen Prototypenwert festlegen:
Listing 84: Schaffung eines neuen Prototypenwertes bei der Elternklasse
Die Ausgabe ist tatsächlich der Wert 6. Es gibt also eine sogenannte „Prototypenkette“, welche von unten nach oben durchsucht wird.
Jede Klasse hat eine Referenz auf den Prototypen der Eltern. Diese liegt in der Variablen
__proto__:
Listing 85: Zugriff auf Elternprototyp über Kindklasse
Wir haben also mit
ChildClass.__proto__.prototype.eValue auf das Prototypenobjekt der Elternklasse zugegriffen und dort ein Attribut hinterlegt.
Somit können wir vom Kind über die
__proto__ Variable auf die Elterndefinition zugreifen, wodurch automatisch alle Erben von
ParentClass diese Eigenschaft erhalten. Diese Prototypenkette hat als vorletztes Glied
„Object“ und als letztes
„null“. Nun können wir dieses Wissen für ein Experiment nutzen, welches für C# oder Java Entwickler undenkbar wäre:
Listing 86: Manipulation des prototype Wertes der Object Klasse
Wir können also tatsächlich eine Funktion für alle Objekte innerhalb unserer Interpretersession hinzufügen. Jedes beliebige
Objekt hat nun die Funktion
sayHi(). Wir sehen also, das Konzept des Prototypen ist durchaus mächtig, sollte aber auf jeden Fall sehr gut geplant sein,
damit der Code noch verständlich bleibt. Insgesamt gäbe es noch sehr viel mehr über Prototypen zu sagen – da dies aber kein
JavaScript Buch ist, sondern die grundsätzlichen Gedanken von Programmierung abdecken soll, belasse ich es bei den hier
beschriebenen Grundlagen.
Nun ist es an der Zeit, über die Access-Modifier zu sprechen. Wir haben bis jetzt alle Eigenschaften und Methoden
public angelegt, da wir keinerlei Modifikatoren formuliert haben. Da wir aber bei JavaScript keine Deklaration haben, müssen die Access-Modifier anderweitig hinterlegt werden. JavaScript kennt neben
public nur noch
private, also hat man kurzerhand das
private mit einem Hashzeichen
# als Präfix festgelegt(8) . Eine
private Variable namens
myVar wird also
#myVar geschrieben. Damit wir das Ganze nun übersichtlich testen können, erzeugen wir ein eigenes File
MyClass.js, in der die Klasse exportiert wird:
(8) Ja – man hat tatsächlich das Hashzeichen für private genommen! Aus UML Sicht ist dies eine extrem schlechte Wahl, da in UML das Hashzeichen für protected steht.
Listing 87: Klassendeklaration mit export und privaten Eigenschaften und Methoden
Im Hauptprogramm können wir nun diese Klasse nutzen:
Listing 88: Nutzung einer Klasse in JavaScript
Ein Zugriffsversuch auf die privaten Eigenschaften und Methoden im „Hauptprogramm“ würde nun zu einem Fehler führen. Da wir inzwischen den Unterschied von
private und
public kennen, dürfte die weitere Interpretation des Codes keine Schwierigkeiten bereiten. Alternativ kann man den Export und Import auch über Module durchführen, wie es in
Kapitel 10 beschrieben wurde.
Die folgenden Syntaxvorgaben orientieren sich an der ES6 Klassenimplementierung, da wir hier die aus der objektorientierten Sicht „sauberste“ Annäherung an das eigentliche objektorientierte Arbeiten haben.
| Was? | Wie? | Bemerkung |
|---|---|---|
| Klassendefinition | class Kreis { } |
Klassen sind eigentlich Objektprototypen. |
| Erweitern | class Kreis extends ZweiDElm { } |
Es gibt keine Mehrfachvererbung. |
| Klasse versiegeln | Object.seal(Kreis); | Man kann keine „Klassen“ versiegeln (da es keine gibt), sondern nur Objekte bzw. Objektprototypen. |
| Abstrakte Klasse | constructor() { if (new.target === Kreis) { throw TypeError("Error!"); } … |
Wird nicht unterstützt. Der Code links ist lediglich ein Workaround(9). |
| Abstrakte Methode | berechneUmfang() { throw TypeError("Error!"); } |
Wird nicht unterstützt. Der Code links ist lediglich ein Workaround(9). |
| Konstruktor | constructor (rf, ff, radius) { … } |
Konstruktoren können nicht überladen werden. |
| Superkonstruktor | constructor (rf, ff, radius) { super(rf, ff); … } |
Der Superkonstruktoraufruf muss vor dem Auftauchen des ersten „this“ Schlüsselwort genutzt werden. |
| Überschreiben | berechneUmfang() { … } |
Es muss lediglich die Signatur übereinstimmen. |
| Interfacedefinition | Wird nicht unterstützt - bringt bei nicht typisierten und klassenlosen Sprachen keinen Mehrwert. | |
| IF Implementierung | Wird nicht unterstützt. | |
| Anonyme Klasse | Wird nicht unterstützt – ist bei prototypischen Sprachen nicht sinnvoll. | |
| Statische Elemente | Wird nicht unterstützt – ist bei prototypischen Sprachen nicht sinnvoll. | |
| Konstanten | const MY_PI = 3.14; | |
| Selbstreferenz | this.radius | |
| Referenz | myObject.setRadius(1.0); | |
| Elternreferenz | super.umfang | Bzw. über prototpye (siehe Codebeispiele Oben) |
| Namensraum | Nicht notwendig, da individuelle Namensräume beim Modulimport vergeben werden können. | |
| Destruktor | Werden nicht unterstützt (bzw. sind nicht notwendig). |
Tabelle 11: Objektorientierte Sprachelemente von JavaScript (ES6)
(9) Dieser Workaround sorgt dafür, dass zur Laufzeit ein Fehler ausgelöst wird.
Bevor ich dieses Kapitel abschließe, noch ein kurzer Exkurs zu den JavaScript Modulen. Der Beispielcode für das Grafikprogramm-Projekt wurde in Module zerlegt, so dass die einzelnen Elemente sich möglichst einfach
nutzen lassen. Hierzu ist folgendes notwendig:
1.: Zuerst hinterlegen wir im
package.json die Information, dass wir mit Modulen arbeiten (siehe hierzu das
Kapitel 10 zum Thema
package.json).
2.: Danach platzieren wir die einzelnen Klassen als je ein File in ein
*.mjs File – also bspw. die Klasse
Dreieck in
Dreieck.mjs.
3.: Die Klasse wird dann über
export default class Dreieck extends ZweiDElm { für die Außenstehenden freigegeben.
4.: Bei der Verwendung importieren wir das Modul mittels
import Dreieck from "./mygraphs/Dreieck.mjs";
Grundsätzlich gibt es noch andere Optionen – für mich war die oben beschriebene Vorgehensweise jedoch meist die einfachste und zuverlässigste.

CC Lizenz (BY NC SA)