
Fehlerbehandlung und Exceptions
Bei unseren Programmierbeispielen sind wir bis jetzt immer vom besten aller User ausgegangen – einem der keine Fehler macht. Die Realität sieht
jedoch anders aus. Wir müssen bei allen unseren Programmen immer davon ausgehen, dass der Fehlerfall eintritt. Egal wie unwahrscheinlich der
Fall sein mag; früher oder später wird er eintreten. Also müssen wir uns zwingend immer über das Errorhandling Gedanken machen.

Die Problemstellung bei Fehlermeldungen
Hierbei gibt es aber ein kleines Problem. Sehen wir uns hierfür folgendes Programm an:
Listing 1: Flächenberechnung ohne Errorhandling
Die Funktion gibt uns die Fläche eines Rechteckes mit den Kantenlängen
a und
b zurück. Was ist aber, wenn die übergebenen Werte fehlerhaft sind. Bspw. ist ein Wert kleiner oder gleich 0 – dann haben wir keinen sinnvollen
Wert zu erwarten. Ein oft genutzter Wert für Fehlersituationen ist die -1. Wir könnten also unseren Code wie folgt ändern:
Listing 2: Flächenberechnung mit Errorhandling
Wir müssten an dieser Stelle aber dem Nutzer unserer Funktion immer mitteilen, dass er das Ergebnis auf -1 prüfen muss, damit er weiß, ob er das
Ergebnis weiterverwenden kann.
Was ist aber, wenn wir eine Funktion ohne einen Rückgabewert haben. Dies wäre beispielsweise bei einem Konstruktor der Fall. Wenn wir uns an den
Konstruktor der Dreiecksklasse aus
Kapitel 13 erinnern, mussten wir dort erstmal die Konsistenz der drei
Seitenangaben prüfen, bevor wir die übergebenen Parameter übernehmen konnten. Wenn sie fehlerhaft waren, sind einfach nur die Standardwerte
übernommen worden und der Aufrufer hat dies im Zweifelsfall überhaupt nicht gemerkt. Aber auch wenn wir Rückgabewerte haben, können wir nicht
immer einen Wert für den Fehlerfall definieren. Was ist beispielsweise, wenn -1 als sinnvoller Wert erwartbar ist? In der folgenden Funktion müssten
wir den Fall
ganz == 0 als Fehlermöglichkeit abfangen:
Listing 3: Funktion ohne Möglichkeit des Errorhandlings
Das Problem hier ist, dass jeder mögliche
int Wert ein gültiges Ergebnis dieser Funktion sein kann. Es gibt also keine Möglichkeit dem Aufrufenden mitzuteilen, dass er einen fehlerhaften
Parameter übergeben hat. Es fehlt also ein „Informationskanal“, welcher diese Problematik als Fehler weiterleitet.
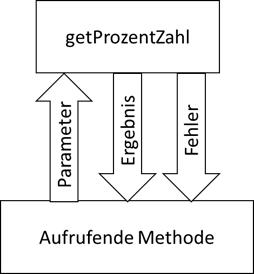
Abb.: 1: Fehlerkanal für Funktionsaufrufe
Das Problem dabei ist aber, dass unser Prozessor immer nur Zeile für Zeile abarbeiten kann. Er wird – Multithreading mal außen vor gelassen –
immer nur eine Sache zu einem Zeitpunkt machen können. Entweder er gibt also das Ergebnis zurück oder die Fehlermeldung. Das ist aber genau das,
was wir eingentlich haben wollen. Eine normale Abarbeitung des Codes ist im Fehlerfall ohnehin fragwürdig. Insofern ist es sinnvoll, dass der
Fehler zum Stopp der normalen Verarbeitung führt und das Programm in einem „Fehlermodus“ läuft – und zwar solange, bis irgendein Code sich um
diesen Fehler kümmert. Wenn wir ein solches Verhalten in C modellieren wollen, so müssen wir diesen „Fehlerkanal“ selbst modellieren. Da
Funktionen nur einen Rückgabewert haben, muss man sich anderweitig helfen. Eine Möglichkeit stellen globale Daten dar, welche mit einem Errorcode
belegt werden.
Listing 4: Einfaches Errorhandling in C
Das Problem hier ist, dass wir uns selbst darum kümmern müssen, die normale Codeverarbeitung zu stoppen und die Fehlerbehandlung in den
Vordergund zu heben. Es wurden hierfür in C diverse Bibliotheken erstellt, welche dem Programmierer bei diesem Problem helfen. Ein Beispiel
wäre
Errno.h, welches das Konzept von zentralen Fehlerinformationen umsetzt. Trotzdem ist die Umsetzung gerade bei komplizierteren Situationen,
in denen bspw. externe Zugriffe auf Files abgefangen werden müssen, nicht trivial und bedarf durchaus einiges an Erfahrung. Microsoft hat
für die Programmiersprache C und C++ ein eigenes Konzept für ein Errorhandling geschaffen, welches einen vom Windows Betriebssystem
bereitgestellten Service namens SEH (Structured Exception Handling) nutzt.
Exception – die Mutter aller Fehler
Bei den anderen objektorientierten Sprachen geht man nun einen anderen Weg. Hier hat man die Exceptions eingeführt. Eine Exception ist im Wesentlichen ein Transportbehälter für
Fehlerinformationen, welcher bei Erzeugung automatisch den normalen Verarbeitungszweig stoppt. In diesen Behälter können wir nun Details über die Fehlerursache legen. Sehen wir
uns das Ganze in Java an:
Listing 5: Exceptionhandling in Java
Kurze Erklärung der Codezeilen:Die Methode
getProzentZahl() prüft wieder den Wert von ganz auf 0. Sollte dies der Fall sein, wird eine Exception „geworfen“.
Dies stoppt sofort die Verarbeitung – das bedeutet, dass alle darauf folgenden Codezeilen dieser Methode nicht mehr
abgearbeitet werden. Die Exception ist ein Objekt, welches (optional) eine Zusatznachricht als String akzeptiert.
Wenn jedoch in Java eine Exception mit
throw geworfen wird, muss bei der Methodendeklaration die Ergänzung
„throws Exception“ hinzugefügt werden. Dadurch weiß der Nutzer, dass die Methode auch über eine Exception beendet
werden kann. Da die Exception bis jetzt nirgends behandelt (sprich „abgefangen“) wird, muss dies Ergänzung in allen
Methoden, welche im Aufrufstack von
getProzentZahl() liegen, eingefügt werden.
Wenn wir das Programm starten und für den Wert
„teil“ die 10 eingeben und
„ganz“ mit 20, funktioniert unser Programm erwartungsgemäß. Setzen wir
„ganz“ aber auf 0, so erhalten wir folgende Meldung:
Zuerst finden wir die Info, dass eine Exception aufgetreten ist mit der Nachricht „Fehlerhafte Daten!“. Nun folgen
drei Zeilen mit der Info, wo die Exception jeweils aufgetreten ist. Ganz oben steht die eigentliche Ursache –
nämlich in der Methode
getProzentZahl() und dort in Zeile 8. Der Aufruf dieser Methode liegt jedoch in der methode
handleUserData() in Zeile 16, welche wiederum in der
main() Methode in Zeile 21 aufgerufen wurde. Dies spiegelt also die interne Aufrufstruktur wieder, welche so auch
im Stack Speicher abgelegt wurde. Aus diesem Grunde nennt man diese Ausgabe auch den Stack-Trace. Die Struktur
kann man sich also wie einen Stapel (engl. „stack“) von aufgerufenen Methoden vorstellen, welche mit dem Fehlerereignis
abrupt abbrechen, da der Fehlerkanal nun bedient wird. Dieser wird in unserem Programm von keiner der Methoden auf
dem Weg zurück behandelt, weshalb er bis zur ausführenden Einheit – bei Java die Virtuelle Maschine JVM – durchgereicht
wird. Dort „schlägt sie auf“ und das gesamte Programm bricht ab.
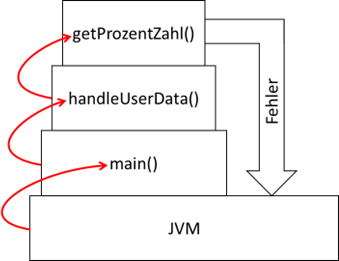
Abb.: 2: Stacktrace mit Exceptionpfad
Da die JVM keine speziellen Informationen zur Behandlung unseres Fehlers haben kann – schließlich wurde sie ja nicht
von uns geschrieben – gibt sie lediglich die in der Exception hinterlegte Nachricht und den Stack-Trace aus und wird
anschließend beendet. Nun können wir diese Fehlermeldung aber auch „abfangen“. Hierzu benötigen wir einen
try-catch Block. Diesen stellen wir uns tatsächlich wie einen Fänger vor, der alle Exceptions fängt und dann
analysieren kann. Passen wir hierzu unser Programm entsprechend an:
Listing 6: Abfangen einer Exception in Java
Kurze Erklärung der Codezeilen: Da wir nun in der Methode
handleUserData() den Fehler abfangen, müssen wir nicht mehr
throws Exception in der Definition dieser und der
main() Methode hinterlegen. Das Abfangen erfolgt in einen überwachten Codebereich, der mit
try {…} abgegrenzt wird. Wenn irgendwo zwischen den beiden Klammern eine Exception auftritt, wird sie „gefangen“.
Das eigentliche „fangen“ erfolgt nun im
catch(). Hier wird die Exception in den Parameter eingetragen und kann zwischen den folgenden geschweiften
Klammern ausgewertet und verarbeitet werden. In unserem Fall wird die Nachricht ausgelesen und in der Konsole
angezeigt. Damit der User nun die Möglichkeit hat die Eingabe korrekt durchzuführen, wird ein Flag
error gesetzt, um die
do/while Schleife zu wiederholen, bis das Flag auf
false gesetzt bleibt.
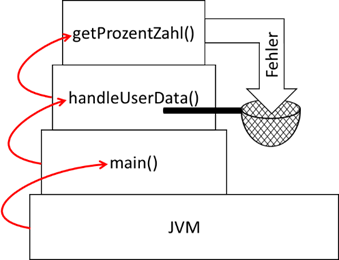
Abb.: 3: Abfangen eines Fehlers
Der Fehler schlägt also nicht mehr bis zur JVM durch, sondern wird vorher abgefangen und verarbeitet. Wo der Fehler
nun letztendlich abgefangen wird, hängt von der notwendigen Fehlerbehandlung ab. Er hätte auch in der
main() Methode gefangen werden können, wobei in unserem Code die Fehleingabe in
handleUserData() erfolgt ist und es am sinnvollsten erscheint, hier die Behandlung auch durchzuführen. Nun gibt es
aber bei dem plötzlichen Abbruch einer Methode noch ein kleines Problem. Wenn beispielsweise irgendwelche Ressourcen
innerhalb der Methode reserviert werden und vor allem auch wieder freigegeben werden müssen, ist ein Abbruch vor der
Freigabe problematisch. Hier bietet Java ein weiteres Feature an, den
finally Block. Dieser wird auf jeden Fall abgearbeitet, bevor die Methode durch
throw oder andere Mechanismen terminiert. Dieses gehört immer zu dem entsprechenden
catch Block – es darf also kein Code zwischen dem
catch – Rumpf und
finally stehen. Dies ist insofern sinnvoll, als dass die Reservierung von Ressourcen meist ohnehin in einem
try/catch Block stehen muss. Dies werden wir bei den Filezugriffen deutlich sehen. Sehen wir uns ein Beispiel mit
finally an, wobei ich hier (noch) auf die Freigabe von Ressourcen verzichte:
Listing 7: Finally Block in Java
Kurze Erklärung der Codezeilen: In dieser Variante brechen wir im
catch Block die Methode einfach ab, indem wir
return aufrufen. Wir geben dem User also keine Möglichkeit, die Eingabe zu wiederholen. Nun wird aber vor der
Beendigung der Methode noch der
finally Block ausgeführt – und zwar auch, wenn
return durchlaufen wird.
Bei der Eingabe von 10 und 20 erhalten wir folgende Ausgabe:
Geben wir aber 10 und 0 ein erhalten wir:
Der
finally Block wird also immer durchlaufen. Dies würde übrigens auch dann gelten, wenn im
try/catch Block eine nicht aufgefangene Exception auftreten würde. Hier stellt sich aber die Frage, warum bzw.
wie eine Exception nicht aufgefangen werden sollte. Hierzu müssen wir unser Wissen über Vererbung wieder bemühen.
Wir haben ja festgestellt, dass eine Exception eigentlich zwei Dinge erledigt. Zum einen fungiert sie als
„Transportbehälter“ für Informationen, welche uns Aufschluss über die Fehlerursache geben soll. Zum anderen
sorgt eine Exception dafür, dass der Prozessor die Verarbeitung des eigentlichen Codes abbricht und sich nur noch um
die Exception bzw. des Abfangens dieser kümmert. Wenn wir nur diese Funktionalität haben wollen, so können wir
(wie in
Listing 5 gezeigt) eine Objekt der Klasse
Exception instanziieren. Wenn uns das aber nicht genügt, so können wir diese
Exception erweitern.
Vererbung – wenn wir es genauer haben wollen
Gehen wir mal davon aus, dass wir drei Typen von Exceptions haben wollen. Eine, welche neben dem Grund des Fehlerfalls
noch den Schweregrad (engl. „severity“) mitführt. Diese soll die Grundstruktur aller unserer individuellen Exceptions
darstellen. Weiterhin soll sie noch die Methode
„doLog()“ vorsehen, welche auf der Konsole eine Lognachricht platziert. Diese kann man später in einer weiteren
Ausbaustufe noch in ein File oder in eine Datenbank loggen lassen. Danach benötigen wir noch zwei angepasste
Exceptions. Eine, welche für mathematische Probleme vorgesehen ist. Diese sollte noch einen Lösungsvorschlag mitführen.
Die letzte fungiert als ein Wrapper um andere Exceptions, so dass wir beliebige Exceptions in unser Errorkonzept einbinden
können:
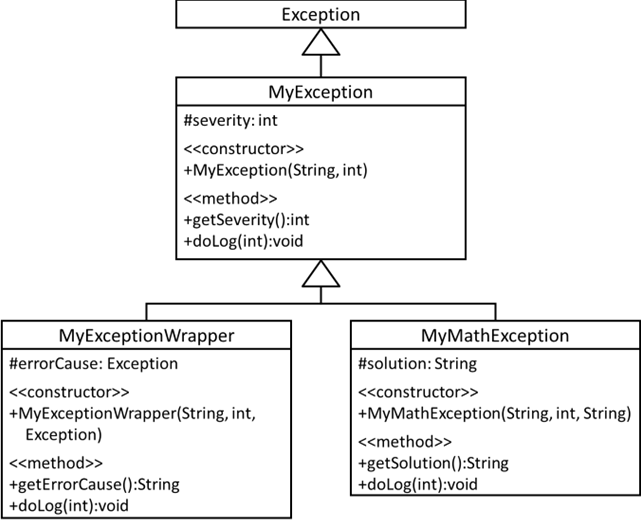
Abb.: 4: Klassendiagramm eigener Exceptions
Da alle unserer Exeptions Nachfahren von
Exception sind, handelt es sich hier um sogenannte checked Exceptions – sprich sie müssen gefangen oder mit
throws weitergeleitet werden. Es gibt zwar auch unchecked Exceptions, diese spielen aber für ein durchgängiges
Errorhandling eine untergeordnete Rolle. Wir wollen nun die
MyMathException werfen, wenn die Division durch 0 erkannt wurde. In allen anderen Fehlerfällen kommt
MyException zum Tragen. Dies können wir aber nur für die Fehlerfälle implementieren, welche wir vorhersehen.
Sollten wir jedoch einen Fehlerfall übersehen haben, so fangen wir noch eine allgemeine Exception ab. Das ist zwar
nicht unbedingt der beste Programmierstil – für das Erlernen der Exceptionstrukturen aber an dieser Stelle sinnvoll.
Gehen wir erst durch die Exceptions durch, obwohl es für unseren aktuellen Wissensstand eher trivial sein müsste:
Listing 8: Eigene Exception für allgemeine Fehler
Kurze Erklärung der Codezeilen: Da Exceptions den primären Zweck des Informationstransportes haben, werden die einzelnen Infos
üblicherweise über den Konstruktor übergeben, wodurch keine Setter erzeugt werden müssen. Exceptions werden normalerweise
sofort nach der Instanziierung „geworfen“. Die Ausgabe erfolgt hier nicht über
System.out.println(), sondern über
System.err.println(), da über diesen Ausgabestrom die Systemfehler ausgegeben werden. Dies ist im Standardfall jedoch auch
„nur“ die Konsole.
Listing 9: Eigene Exception für mathematische Fehler
Listing 10: Eigene Exception als Wrapper für beliebige Exceptions
Bauen wir nun die Exceptions in unseren Code ein. Beginnen wir mit
getProzentzahl():
Listing 11: Einbau der mathematischen Exception
Kurze Erklärung der Codezeilen: Wir haben nun lediglich die Exception mit
MyMathException ausgetauscht. Dies wurde sowohl bei der Erzeugung, als auch beim
thorws in der Methodendefinition berücksichtigt.
Die Frage ist nun, warum wir bei
throws nicht dabei bleiben, einfach nur
Exception zu hinterlegen. Theoretisch würde es ja gehen, da die
Exception ein „Vorfahre“ von
MyMathException ist und somit ein Typecast möglich wäre. Der Grund liegt darin, dass wenn wir mit
throws eine dezidierte Exception angeben, so muss diese von der verarbeitenden Methode (in unserem Fall wird dies
handleUserData() sein) behandelt werden. Entweder durch ein
catch(MyMathException e) oder durch ein
throws. Wir dürfen die nach
throws angegebene Exception also nicht ignorieren. Sollten wir nun in einer Methode unterschiedliche Exceptions
werfen, so können wir entweder einen gemeinsamen „Vorfahren“ hinter
throws schreiben, oder die geworfenen Exceptions kommasepariert hintereinander schreiben – wir können also steuern,
wie unsere Exceptions vom Nutzer unserer Methoden abgefangen werden müssen. Gehen wir nun in die für das
Errorhandling zentrale Methode:
Listing 12: Errorhandling bei unterschiedlichen Exceptions
Kurze Erklärung der Codezeilen: Die Methode behandelt zwar Exceptions, gibt sie aber am Ende an den Aufrufer
weiter, da die Exceptions einheitlich eine Ebene höher abgearbeitet werden sollen. Dies dient in diesem Code
primär zu Demonstrationszwecken! Die hier behandelten Fehler sind entweder ein zu langer
String (wir gehen davon aus, dies soll eine Anforderung der Software sein). Die zweite behandelte Fehlersituation
ist eine
NumberFormatException – sprich der eingegebene String lässt sich nicht in eine Zahl umwandeln. Der dritte Fehler
ist das 1:1 Durchreichen der
MyMathException, indem wir sie einfach ignorieren. Da sie aber ein Nachfahre von
MyException ist, wird sie durch das
throws MyException an den Aufrufer weitergereicht.
Die eigentliche Auswertung erfolgt nun in der
main() Methode:
Listing 13: Letztendliche Verarbeitung der Excepitons
Auf dieser Ebene müssen wir nun lediglich die
MyException fangen, da diese auch nur in
handleUserData() geworfen wird. Das Einzige was wir hier durchführen, ist der Logaufruf mit der Severity 2, sprich alle
Exceptions mit Loglevel größer oder gleich 2 werden gelogged. Da alle
MyException (Sub-)Klassen die Methode
doLog() aufweisen, ist dies an dieser Stelle auch möglich. Nun können wir aber das Fangen von Exceptions auch
kaskadieren, indem wir weitere Exceptions unten anhängen – in unserem Fall die allgemeine
Exception. Dies soll hier auch „nur“ als Beispiel dienen. Wir sollten immer ganz bewusst alle möglichen
Fehlerursachen erkennen und individuell abfangen. Wichtig bei diesem kaskadierten Abfangen ist, dass wir immer von
speziellen hin zu allgemeinen Exceptions vorgehen. Würden wir die
Exception vor
MyException abfangen, würde letztere nie abgearbeitet werden, da sie eine Untermenge von
Excption ist. Wenn wir unseren Code nun ausprobieren, können wir alle Fälle provozieren. Geben wir bspw. 10 und 2
ein erhalten wir:
Die Eingabe 123456 für das Ganze erzeugt:
Geben wir hallo ein:
Wir können aber noch eine „vergessene“ Exception provozieren, indem wir auf „Cancel“ klicken:
Abb.: 5: Eingabemaske mit "Cancel" Button
Dadurch gibt uns
showInputDialog() einen null-Wert zurück und die Längenbestimmung
„sGanz.length()“ würde zu einer
NullPointerException führen, was wir in unserem Code nicht explizit prüfen:
In solch einer Situation müssten wir sinnvollerweise unseren Code anpassen, um auch diese Fehlersituation sauber
abfangen zu können, um dem User eine detailliertere Begründung für die Fehleingabe zu liefern.
Bevor wir nun auf die anderen Programmiersrpachen blicken noch ein kleiner Hinweis für die dynamisch typisierten
Sprachen wie bspw. JavaScript. In Java können wir aufgrund der Vererbungsstruktur und der Typisierung eine
Catch-Kaskade aufbauen, wodurch wir exakt die Exceptions abfangen können, die wir benötigen. Dies geht eigentlich
in dynamisch typisierten Sprachen nicht. Um nun trotzdem eine Information zu erhalten, welche Exception den Fehler
hervorgebracht hat, gehen die drei hier besprochenen Skriptsrpachen unterschiedliche Wege. In JavaScript müssen wir
den Instanztyp der einzelnen Objekte explizit mit
instanceof abfragen:
Listing 14: Identifikation unterschiedlicher Fehler in JavaScript
PHP und Python wiederum führen an dieser Stelle die Typisierung nun doch ein und unterscheiden wie Java einzelne
Klassen in einem kaskadierten catch Block. PHP ist aufgrund der Nutzung von geschweiften Klammern vergleichbar mit
Java und Co., weshalb ich hier auf Codebeispiele verzichten kann. Anders sieht es bei Python aus – insofern hier ein
kurzes Beispiel:
Listing 15: Exception Handling in Python
Umsetzungsvarianten der einzelnen Programmiersprachen
Sehen wir uns nun die Optionen an, welche uns die unterschiedlichen objektorientierten Sprachen in Puncto Exceptions bieten:
| Was: | Wie: | Bemerkung: | |
|---|---|---|---|
| Java | try | try{...} | |
| catch | catch(...){...} | Parameter ist Exception (oder Nachfahre) | |
| finally | finally{...} | ||
| throw | throw ... | ... new Exception() (oder Nachfahre) | |
| throws | throws ... | Es dürfen mehrere Exceptions kommasepariert folgen. | |
| Elternklasse | Exception | ||
| C++ | try | try{...} | |
| catch | catch(...){...} | ||
| finally | Wird nicht unterstützt, kann aber durch den Destruktor der fehlerhaften Klasse erfolgen(1). | ||
| throw | throw(...) | ||
| throws | throw(...) | Wird nicht erzwungen und meist weggelassen. | |
| Elternklasse | std::exception | ||
| C# | try | try{...} | |
| catch | catch(...){...} | ||
| finally | finally{...} | ||
| throw | throw ... | ||
| throws | Wird nicht unterstützt. | ||
| Elternklasse | Exception | ||
| JavaScript | try | try{...} | |
| catch | catch(...){...} | ||
| finally | finally{...} | ||
| throw | throw ... | ||
| throws | Wird nicht unterstützt. | ||
| Elternklasse | Error | ||
| PHP | try | try{...} | |
| catch | catch(...){...} | ||
| finally | finally{...} | ||
| throw | throw ... | ||
| throws | Wird nicht unterstützt. | ||
| Elternklasse | Exception | ||
| Python | try | try: | |
| catch | except ... : | Variablenzuweisung mit Klasse as Variable | |
| finally | finally: | ||
| throw | raise | ||
| throws | Wird nicht unterstützt. | ||
| Elternklasse | Exception |
Tabelle 1: Syntaxvarianten von Exceptionhandling
(1)SEH wird nur in Windows Systemen unterstützt.

CC Lizenz (BY NC SA)