
Multithreading – gemeinsam sind wir schneller
Wenn die logischen Optimierungsmaßnahmen nicht ausreichend sind, können wir in manchen Situationen noch arbeitsteilig vorgehen. Dies geht aber leider nicht immer – die Primzahlenermittlung aus dem
vorausgegangenen Kapitel wäre ein Kandidat, bei dem die arbeitsteilige Ermittlung nur bedingt möglich ist. Der Grund liegt daran, dass die Berechnungen aufeinander aufbauen. Wir können die höheren
Faktoren erst dann performant bestimmen, wenn wir die niedrigeren ermittelt haben. Rechnungen, welche unabhängig voneinander durchgeführt werden können, sind jedoch ohne weiteres aufteilbar. In diesem
Kapitel werde ich eine Fraktal Berechnung als Beispiel nehmen, da es zum einen ein sehr oft zitiertes Beispiel ist und zum anderen einfach schön aussieht 😊
Doch beginnen wir wie immer mit grundsätzlichen Überlegungen. Bevor wir in die rechenintensive Fraktal Berechnung einsteigen müssen wir uns nochmal vergegenwärtigen, welche Ressourcenbeschränkungen eine
schnellere Abarbeitung unseres Codes verhindern. Die offensichtliche ist natürlich die CPU, welche einfach nur eine gewisse Anzahl an Aktionen pro Zeit durchführen kann. Hier ist schlichtweg die Kapazität
des Rechenkerns ausgeschöpft. Es gibt jedoch in manchen Programmen noch einen zweiten Engpass – und zwar externe Ressourcen, wie bspw. durch die Kommunikation über das Netzwerk. Die sequenzielle Abarbeitung
unseres Codes führt nämlich unweigerlich dazu, dass wenn eine Aktion nicht abgeschlossen ist, die Codeausführung nicht weitergeht. Stellen wir uns bspw. vor wir haben ein Programm, welches Daten von einem
entfernten Server lädt. Wenn der Server nun nicht schnell genug antwortet, muss unser Programm auf diese Antwort warten. Und in genau dieser Zeit könnte unser Programm eventuell sinnvollere Dinge tun.

Begriffe
Wir unterscheiden also zwei verschiedene Situationen, welche die Ausführungsgeschwindigkeit unseres (theoretisch perfekt optimierten) Codes begrenzen – CPU-Last und „warten“. Bei den kompilierten
Programmiersprachen ist die Lösung für beide Fälle meist die gleiche und wird im Regelfall unter dem Begriff „Multithreading“ subsumiert. Bei Skriptsprachen wie Python, wird zwischen diesen beiden
Fällen CPU/warten unterschieden – man spricht (zumindest in Python) von Multithreading und Multiprocessing. Während „Multithreading“ in Python verschiedene Threads bezeichnet, welche aber in einem
Core laufen, versteht man dort unter „Multiprocessing“ die Nutzung verschiedener Cores. Um diesen Zusammenhang nochmal klarzumachen, stellen wir uns folgende Situation vor. Ein Maler hat die Aufgabe,
mehrere Leinwände anzumalen. Da er den Pinsel nicht auswaschen kann und es für ihn tragbar ist mit einer helleren Farbe auf dem Pinsel in einen dunkleren Farbtopf einzutauchen, muss er zuerst die gelbe,
dann die rote und am Schluss die schwarze Leinwand anmalen:

Abb.: 1: Sequenziell zu verrichtende Aufgabe
Wenn nun der gelbe Farbeimer leer ist bevor die Leinwand komplett bemalt wurde, muss er zwangsweise warten, bis ein neuer geliefert wird. Der gesamte Prozess ist also blockiert, obwohl der eigentliche
Prozessor (also unser Maler) nichts macht, außer warten. Dies wäre ein „singlethreaded“ Programm, welches „synchron“ abgearbeitet wird. Wenn er aber nun für jede Farbe einen eigenen Pinsel hätte, so
könnte er während der Wartezeit auf den neuen gelben Eimer anfangen, die rote und schwarze Leinwand anzumalen. Sobald der gelbe Eimer da ist, könnte er mit der gelben Leinwand weitermachen. Dies wäre
aus Python Sicht ein „multithreaded“ Programm, in anderen Programmiersprachen würde man hierzu „asynchron“ sagen. Hätte unser Maler aber Unterstützung von zwei weiteren Malern, so könnten alle drei
Leinwände parallel bemalt werden – zumindest solange Farbe da ist. Dies wäre aus Python Sicht ein „multiprocessing“ Programm. Aus Sicht von Java oder C# würde man auch letzteres als „multithreaded“
Programm bezeichnen, da dort Threads immer unabhängig laufen. Wie wir sehen, werden die Begriffe leider bei den unterschiedlichen Programmiersprachen unterschiedlich belegt. Um diesen Umstand etwas
besser in Worte zu fassen, können wir mit unserem kleinen „Malbeispiel“ drei geeignetere, weil interpretationsfreie, Begriffe erklären. Die Umsetzung unserer Malaufgabe mit nur einem Pinsel wäre ja
ein Beispiel für synchrones Abarbeiten. Sobald wir mehr als einen Pinsel verwenden, sprechen wir hier von einer asynchronen Abarbeitung – wir sind also mehr oder weniger frei in unserer Entscheidung,
in welcher Reihenfolge wir abarbeiten. Sobald wir nun mit mehr als einem Maler agieren, würden wir von einer parallelen Abarbeitung sprechen, welche in sich wiederum zwingend asynchron ist. So viel
ist anfangs zur Terminologie wichtig, damit alle Leser vom Gleichen ausgehen.
Gehen wir nun in die Details der Verarbeitung. Wie wir in den ersten Kapiteln des Buches geklärt haben, ist die CPU in der Lage, an einer zentralen Stelle binäre Daten miteinander zu verknüpfen.
Die Taktfrequenz bestimmt nun, wie viele solche Verknüpfungen pro Sekunde möglich sind. Wenn man schnellere Prozessoren haben möchte, dann hatte man früher im Wesentlichen zwei Optionen. Erstens
kann man die Aktion pro Takt effektiver gestalten. Wir haben in
Kapitel 4 beispielsweise gesehen, dass wir ganze Zahlen relativ einfach mit Hilfe von Hardwarelogik addieren und basierend auf mehreren Additionen hintereinander eine Multiplikation realisieren können.
Diese Multiplikation kann man aber effektiver gestalten, wenn man sie bereits hardwareseitig in einem Schritt durchführt. Gleiches gilt für die komplizierteren Gleitkommaoperationen. Man könnte sie
aus einzelnen Operationen mit ganzen Zahlen aufbauen, oder eine FPU (Floating Point Unit) auf dem Prozessor hinterlegen, die sich hierum kümmert. Diese Optionen sind aber irgendwann ausgeschöpft,
da man früher oder später alle logisch möglichen Optimierungen implementiert hat. Die zweite Möglichkeit der Performancesteigerung ist schlichtweg die Erhöhung der Taktrate – man versucht also pro
Sekunde mehr Operationen durchzuführen. Hier gibt es jedoch physikalische Grenzen. Die wahrscheinlich wichtigste ist die Wärmeentwicklung, welche pro elektrischer Aktion entsteht. Steigt die Anzahl
der Aktionen pro Sekunde, steigt auch die kumulierte Wärmeentwicklung pro Zeit, welche irgendwie abgeführt werden muss. Mit speziellen Kühlvorkehrungen kann man Prozessoren zwar „hochtakten“ – also
die Taktrate über das empfohlene Maß erhöhen, was aber ein vergleichsweise hoher Aufwand ist. Die derzeitig maximal möglichen Prozessortakte bei klassischen CPUs für den PC Einsatz liegen bei 3-4 GHz im Normalbetrieb,
was so etwas wie eine „natürliche“ Grenze für den Betrieb in realistischen Betriebsumgebungen ist. Man sieht dies sehr schön daran, dass sich dieser Wert seit 2005 nicht wirklich geändert hat. Um
nun den Trend der immer leistungsfähigeren CPUs fortzusetzen, haben zu diesem Zeitpunkt die Multicore Prozessoren Einzug in die PCs gehalten, wodurch das Thema Multithreading (oder im Fall von
Python Multiprocessing) interessant wurde. Multicore bedeutet, dass man in einen Prozessorchip einfach mehrere parallel arbeitende Rechenkerne einbaut – vereinfacht gesprochen, mehrere CPUs auf einem Chip.
Wenn wir als Programmierer dieses Potential nun ausnutzen wollen, müssen wir unser Programm genau darauf ausrichten. Das zentrale Problem ist hier, dass unser Code sequenziell abgearbeitet wird – Zeile für
Zeile. Alle Programme, welche wir bis hier in diesem Buch durchgearbeitet haben, folgen diesem Paradigma. Unser Prozessor (oder Interpreter) hat sich die main-Methode gesucht, diese gestartet und ist
dann Schritt für Schritt dem Code gefolgt. Dieses Durcharbeiten unseres Programms erfolgt in einem sogenannten „Thread“. Unser Betriebssystem zeigt uns dann auch in den Ressourcenmonitoren an, wie viele
Threads der Rechner derzeit verwaltet. Unser Programm wäre dann einer dieser Threads. Wenn wir nun den Rechner in die Lage versetzen wollen, unser Programm parallel abzuarbeiten, müssen wir ihm
irgendwie die Möglichkeit geben, mehrere „Handlungsstränge“ zu verfolgen, er muss also in mehreren Threads laufen. Diese Art der Programme nennen wir im allgemeinen „multithreaded“. Allen multithreaded
Programmen ist jedoch gemein, dass wir mit einem Hauptthread starten, der wiederum Subthreads initiiert. Die Notwendigkeit einer main-Methode bleibt also bestehen.
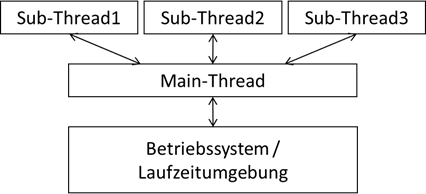
Abb.: 2: Starten von Threads
Der untere Teil der
Abbildung 2 ist das bis jetzt bekannte Konzept. Die oberen Sub-Threads kommen nun neu hinzu. Jeder dieser Threads (und natürlich auch die einzelnen Threads des Betriebssystems und wenn wir mit Java, C# oder
einer Skriptsprache arbeiten auch die der Laufzeitumgebung) muss von einem CPU-Kern abgearbeitet werden. Das Betriebssystem kümmert sich unter anderem darum, dass jeder Thread entsprechend einer CPU zugewiesen wird.
Da aber fast immer weniger Kerne als Threads vorhanden sind, muss ein Kern mehrere Threads bedienen. Dies geht aber nur sequenziell (genauso wie unser Farbeimerbeispiel mit mehreren Pinseln, aber nur einem Maler).
Das heißt ein Kern verarbeitet einen Teil des ersten Threads, dann einen Teil des zweiten und so weiter, bis er wieder Zeit für den ersten Thread hat. Wenn wir als Programmierer nun Performancegewinne durch
Parallelisierung erreichen wollen, ist es hilfreich zu wissen, wie viele Cores ein Prozessor aufweist. Bei der Ermittlung der Kernanzahl muss man noch wissen, dass vor allem bei Intel Prozessoren ein Hardwarekern
noch in virtuelle Kerne aufgeteilt wird – sprich der Prozessor bietet dem Betriebssystem meist doppelt so viele Kerne an, als hardwareseitig implementiert sind, was man als „Hyperthreading“ bezeichnet.
Die Technologie dahinter ist aber so gestaltet, dass eine Aufteilung auf zwei virtuelle Kerne tatsächlich einen Performancegewinn bringt, obwohl beide auf dem gleichen Hardwarekern laufen. Insofern unterscheiden
wir als Programmierer hier nicht zwischen logischen und realen Kernen. Nun hat das Betriebssystem noch die Aufgabe zu verhindern, dass zwei Programme auf den gleichen Speicherbereich zugreifen können. Das hat
zum einen natürlich seinen Grund in der Sicherheit, damit die Programme sich nicht gegenseitig „ausspionieren“ können, aber auch einen ganz einfachen technischen Grund. Wenn ein Thread gerade Daten verändert und der
andere sie auslesen möchte, entstehen mitunter nicht konsistente Datenkonstellationen. Da die Programme aufgrund der genannten Sicherheitsbedenken „Herr“ über ihre Datenbereiche sind, ist das bei einem singlethreaded Szenario kein Problem.
Bei Programmen, welche mehrere Threads nutzen aber sehr wohl! Das Betriebssystem muss also wissen, dass zu einem Programm mehrere Threads gehören und sie sich Speicherplatz teilen, bzw. gegenseitig auf die Daten
zugreifen dürfen. Das ist in den einzelnen Sprachen unterschiedlich gelöst und bedarf im Regelfall einige Codeelemente, welche auf den ersten Blick „nervig“ sind, aber genau auf diese Problematik hin ausgerichtet sind.
Mit dem Paradigmenwechsel, Code nun parallel in mehreren Threads abzuarbeiten, handeln wir uns aber eine ganz neue Art von möglichen Fehlerquellen ein, nämlich die Zeit! Hierzu überlegen wir mal ein Beispiel außerhalb
der Computerwelt. Gehen wir mal davon aus, Kinder wollen bunte Papierflieger bauen. Nun haben sie die Möglichkeit, dies mit einem „Thread“ durchzuführen, sprich ein Kind baut die Flieger und malt sie anschließend an:

Abb.: 3: Sequenzielle Abarbeitung
Der Algorithmus wäre also, dass der erste Arbeitsvorgang „die Flieger zu bauen“ bestimmt, wie viele Flieger benötigt werden. Der zweite Arbeitsgang arbeitet dann einfach alle Flieger ab und bemalt sie. Sobald kein weißer
Flieger mehr zu sehen ist, bricht der Malvorgang ab. Nun könnten die Kinder auf die Idee kommen, die beiden Aktivitäten an zwei Kinder aufzuteilen und sie zu parallelisieren:
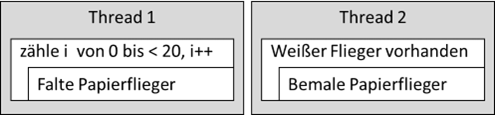
Abb.: 4: Parallele Abarbeitung
Das Kind für das Bemalen der Flieger darf nun natürlich erst beginnen, wenn der erste Flieger gefaltet wurde. Die Frage ist nun was passiert, wenn das Falten des Fliegers mehr Zeit in Anspruch nimmt als das Bemalen.
Natürlich wären die Kinder jetzt so schlau und würden aufeinander warten – aber wenn wir uns mal wieder den Titel des Buches in Erinnerung rufen – der Computer ist nun mal nicht „schlau“ – sieht die Sache wieder anders
aus. Er würde schlichtweg nach dem Bemalen des ersten Fliegers keinen weißen Flieger mehr finden (der zweite Flieger wird ja gerade erst gefaltet) und den zweiten Thread einfach beenden. Wir hätten 19 weiße und einen
bunten Flieger. Wenn allerdings das Bemalen länger dauert als das Falten, dann kommen 20 bunte Flieger heraus. In der sequenziellen Abarbeitung haben wir dieses Problem nicht – wir erhalten immer 20 bunte Flieger, egal
welcher Vorgang länger dauert. In der Programmierung kommt nun ein weiteres Problem hinzu. Natürlich kann man davon ausgehen, dass im Test schon herauskommt, was länger dauert – Bemalen oder Falten. Es kann aber durchaus
sein, dass auf einem anderen Rechner die Situation genau andersherum ist. Somit kann der Test auf einem Testrechner ein richtiges Ergebnis hervorbringen, auf einem Kundenrechner aber ein falsches. Weiterhin bieten einem
alle Entwicklungsumgebungen die Möglichkeit, Programmabarbeitungen temporär anzuhalten, um sich den Zustand des Programms anzusehen. Wir werden hierüber später nochmal beim Thema „Debuggen“ sprechen. Das heißt, dass wir
durch das temporäre Anhalten des multithreaded Programms im Zweifelsfall ein fundamental anderes Ergebnis erhalten, als wenn wir es normal durchlaufen lassen würden – das Anhalten verändert ja die Durchlaufzeit eines
Vorgangs. Diese Situation darf aber auf keinen Fall akzeptiert werden! Ein Programm muss unabhängig von der Zeit immer das gleiche Ergebnis liefern. Ein weiteres Problem ist, wenn zwei Threads plötzlich zum gleichen
Zeitpunkt auf eine Ressource zugreifen möchten. In unserem Papierfliegerbeispiel wäre es, wenn beide parallel arbeitenden Kinder eine gemeinsame Ablage für ihre Flieger hätten und sich darüber streiten, wer nun seinen
Flieger ablegen darf. Auch solche Probleme können bei multithreaded Programmen auftreten.
Threadsafe
Wenn unsere Programme, oder auch Teilmodule von Programmen (bspw. Klassen), dies Problemstellungen umgehen – sprich zeitunabhängig immer gleich fehlerfrei funktionieren, so sind sie „threadsafe“. Wir sehen uns nun mal
ein programmiertes Beispiel an, welches nicht threadsafe oder zu Deutsch nicht „threadsicher“ ist. Hierzu müssen wir erstmal die Grundlagen für Multithreading legen. Unterschiedlich lange Ausführungen simulieren wir hier
einfach mit einem Pause-Befehl, welchen die meisten Programmiersprachen unterstützen. Machen wir das Ganze mal in C# und beginnen mit dem Hauptprogramm:
Listing 1: Hauptprogramm für Multithreading in C#
Kurze Erklärung der Codezeilen: Hier passiert noch nicht sehr viel – lediglich eine Instanz des „Handlers“ wird erzeugt und die gesamte multithreaded Logik wird gestartet. Wichtig ist hier lediglich, dass wir eine
Ausgabe haben, sobald die Main Methode endet.
Als nächstes schreiben wir die Klasse, die sich um den Start des zusätzlichen Threads kümmert, welche ich
MyMainHandler getauft habe:
Listing 2: Erzeugung eines Threads in C#
Kurze Erklärung der Codezeilen: Die Klasse implementiert zwei Methoden. Die erste ist dafür zuständig, den
Thread zu starten, wofür eine eigene Klasse
MyThreadClass instanziiert wird. Diese soll die Arbeit wiederum in einem eigenen
Thread verrichten. Die Threadklasse
„Thread“ liegt in der Bibliothek
„System.Threading“, weshalb sie mit
using bekannt gemacht werden muss. Diese Threadklasse ist ein Behälter, in den wir unsere Threadklasse legen – bzw. eigentlich nur die Methode, welche aufzurufen ist – in unserem Fall
doYourWork. Sobald der Thread gestartet wurde, meldet die Methode auf der Konsole, dass dies erfolgt ist. Die zweite Methode empfängt von außen einfach eine Nachricht. Diese wird später vom
Thread für eine Mitteilung genutzt.
Die eigentliche Threadklasse soll nun die Methode
doYourWork() umsetzen:
Listing 3: Klasse für die threaded ausführung in C#
Kurze Erklärung der Codezeilen: Die Klasse erwartet zwei Parameter im Konstruktor, welche in die gleichnamigen Instanzvariablen geschrieben werden.
mainProg ist die Referenz auf den aufrufenden Handler und
someInfo ein beispielhafter Wert, welcher später der Ausgabe dient. Die Methode
doYourWork() hat keine Parameter – die von außen bereitgestellten Informationen (wie bspw.
someInfo) wurde ja über den Konstruktor (bzw. könnten über Settermethoden) geliefert werden. Innerhalb der Methode wird eine Schleife 5 mal wiederholt, und mit Hilfe von
Thread.Sleep(2000); eine 2 Sekunden Pause eingelegt, was eine aufwändige Verarbeitung simulieren soll. Nachdem die Pause vorbei ist, wird auf der Konsole eine entsprechende Meldung ausgegeben.
Am Ende der Schleife ruft der Thread durch unsere
MyThreadClass Klasse nochmal in
MyMainHandler die Methode
threadFinishInfo() auf, damit in unserem Beispiel auch eine Kommunikation vom
Thread zum Aufrufenden gezeigt werden kann.
Wenn wir den Code laufen lassen, sehen wir nach einer gewissen Zeit folgende Nachrichten:
Das ist auf den ersten Blick überraschend. Das Programm wird zuerst beendet und dann werden die Thread Ausgaben gemacht. Dies liegt streng genommen daran, dass die Ausgabe „Programmende“ nicht ganz korrekt ist.
Was endet, ist die Main Methode. Die Threads laufen weiter und erst wenn der letzte Thread beendet ist, dann stoppt das Gesamtprogramm, was im Wesentlichen die .NET Laufzeitumgebung ist. Dies können wir sehr
viel besser sehen, wenn wir unser Programm nicht über VSCode laufen lassen, sondern es direkt mit einem Doppelklick im FileExplorer starten. Dies trägt den Namen
csharp.exe und befindet sich im Projektunterordner
bin\Debug\net5.0:

Abb.: 5: Ordner der ausführbaren Files unseres C# Projektes
Wenn wir es mit einem Doppelklick starten, dann sehen wir, dass die Konsole erst schließt, wenn die letzte Ausgabe getätigt wurde:
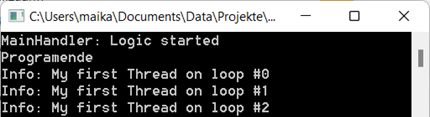
Abb.: 6: Ausführung unseres Programms unter Windows
Wenn wir unsere Main Methode nun so laufen lassen wollen, dass sie erst zusammen mit dem gesamten Programmausführung endet, müssen wir unser kleines Programm etwas anpassen. Wir merken uns in der Klasse
MyMainHandler, dass wir gerade einen
Thread gestartet haben und können die Methode
startLogic() dazu erweitern erst dann zu stoppen, wenn kein
Thread mehr läuft:
Listing 4: Blockieren von startLogic() während Thread läuft
Kurze Erklärung der Codezeilen: Die Variable
threadRunning hält nun die Information, ob der
Thread gerade aktiv ist. Sobald wir unseren
Thread starten, setzen wir die Variable auf
true. Am Ende von
startLogic() laufen wir solange durch eine Schleife, bis
threadRunning wieder auf
false ist. Dadurch endet diese Methode erst, wenn der
Thread fertig ist. Im Rumpf der Schleife machen wir eine 10 ms Pause, um den Prozessor nicht unnötig oft die Schleife durchlaufen zu lassen. Obwohl wir nun innerhalb der Schleife die Variable
threadRunning nicht verändern, haben wir keine Endlosschleife realisiert. Der Grund liegt hier am Multithreading. Der parallel laufende
Thread hat nun die Aufgabe, am Ende diese Variable wieder auf
false zu setzen, indem er die Methode
threadFinishInfo() aufruft.
Lassen wir nun das Programm wieder laufen, sehen wir eine „sinnvollere“ Ausgabe:
Nun, da wir die ersten Gehversuche mit Threads gemacht haben, realisieren wir ein Programm, welches eine typische Verletzung der Threadsafe Regeln darstellt. Dieses Verhalten nennen wir auch
„Race condition“, da aufgrund von zeitlichen Konstellationen einzelne Aktionen zu früh oder zu spät erfolgen. Sehen wir uns das Konstrukt erstmal grafisch an. Wir haben ein zentrales Programm, welches
irgendwelche Berechnungen durchführt, die eine gewisse Zeit dauern. Das (kumulierte) Ergebnis wird in einer zentralen Variablen gehalten. In unserem Fall simulieren wir die Rechenzeit mit einer Pause,
und das kumulierte Ergebnis ist einfach nur ein Zähler, der um eins hochgezählt wird:

Abb.: 7: Zentrale Ressource für diverse Threads
Nun realisieren wir eine Logik, welche zwei Threads startet, die wiederum diese zentrale Funktionalität nutzen müssen:
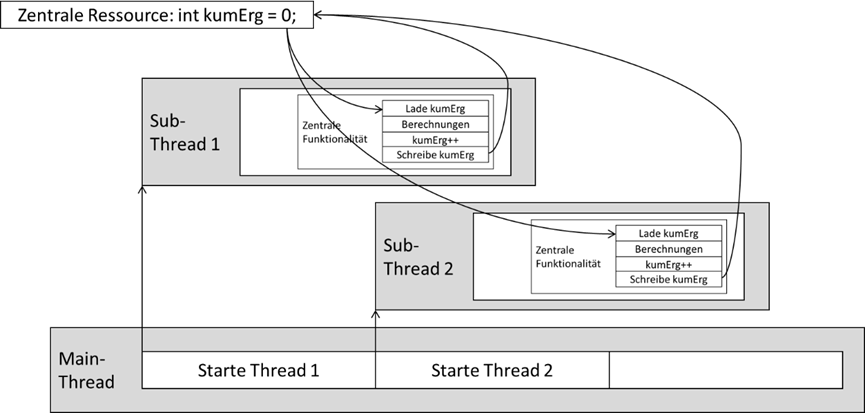
Abb.: 8: Threadaufruf
Sehen wir uns die Belegung der Variable
kumErg mal im Zeitablauf in zwei verschiedenen zeitlichen Konstellationen an.
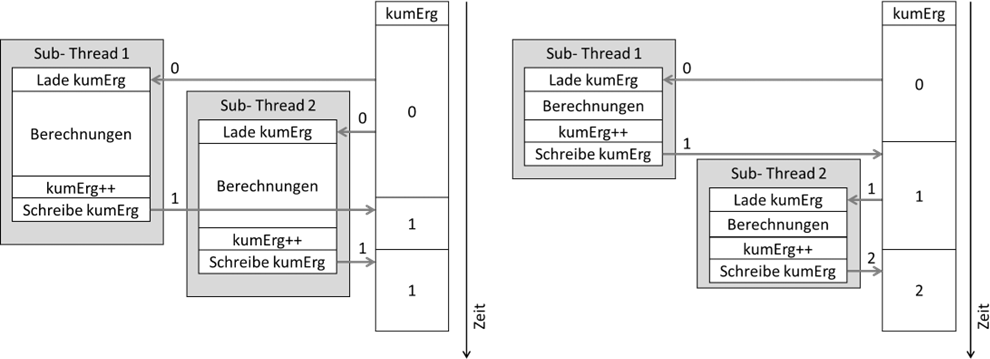
Abb.: 9: Zeitliche Abfolge Möglichkeiten bei Threadaufrufen
In beiden Szenarien wird zuerst Thread 1 gestartet, der wiederum die zentrale Funktionalität aufruft. Diese liest
kumErg, erhöht sie von 0 auf 1 und schreibt sie wieder zurück. Parallel macht Thread 2 das gleiche. Wenn nun, wie im linken Bild, Thread 2 aufgerufen wird, ohne dass
kumErg von Thread 1 zurückgeschrieben wurde, liest Thread 2 ebenfalls die 0 und erhöht auf 1. Somit schreiben beide die 1 zurück. Warten wir wie im rechten Szenario mit dem
Aufruf von Thread 2, liest dieser die von Thread 1 zurückgeschriebene 1, erhöht auf 2 und schreibt sie zurück – wir haben also aufgrund eines zeitlichen Unterschiedes zwei
verschiedene Endergebnisse. Nun wollen wir das Ganze mal in die Tat umsetzen. Dafür schreiben wir unsere Klassen
MyMainHandler und
MyThreadClass um. Beginnen wir mit
MyMainHandler:
Listing 5: Zentrale Funktionalitäten in C# ohne Threadsicherheit
Kurze Erklärung der Codezeilen: Da wir nun zwei Threads haben, zählen wir in
noOfThreads die gestarteten Threads und warten am Ende des Programms solange, bis sich alle wieder zurückgemeldet haben. Danach doe Threads erzeugen wir mit zwei unterschliedlichen Namen.
Den ersten starten wir sofort und zählen
noOfThreads hoch. Jetzt machen wir eine Pause von 50 Millisekunden. Danach starten wir Thread 2 und zählen
noOfThreads ebenfalls hoch. Am Ende warten wir, bis noOfThreads auf 0 zurückgesetzt wurde – sprich alle Threads beendet wurden. Die zentrale Variable
kumErg wird noch zur Kontrolle ausgegeben. Die
threadFinishInfo() Methode wird lediglich auf die
noOfThreads Variable umgeschrieben, so dass bei Rückmeldung diese um 1 reduziert wird.
doConsumngStuff() wiederum ist die Berechnung, welche durch einen
Sleep() simuliert wird. Hier wird zuerst eine Info auf der Konsole ausgegeben um zu sehen, wann im Fortlauf sie aufgerufen wurde. Danach holen wir die zentrale Info aus
kumErg in eine lokale Variable und simulieren dann mit einer Pause von 0.2 Sekunden die Verarbeitung – also länger als die Pausenzeit in
startLogic(). Zum Schluss wird die lokale
kumErg „berechnet“ – in unserem einfachen Beispiel einfach nur hochgezählt – und zurückgeschrieben.
Die Klasse
MyThreadClass wird eigentlich nur noch verschlankt, da die Berechnung ja nun zentral in
doConsumingStuff() liegt:
Listing 6: Aufruf einer nicht threadsicheren Funktionalität in C#
Kurze Erklärung der Codezeilen: Im Wesentlichen hat sich nichts geändert.
doThreadedWork() ruft lediglich die Methode
doConsumingStuff() auf und gibt vor und nach dem Aufruf eine kurze Info auf der Konsole aus.
Wir erkennen, dass die Methode
doConsumingStuff() parallel läuft. Bevor
„Done with call of Thread 1“ ausgegeben wird, finden wir
„Thread 2 called me“. Es ist also genau die Situation wie die linke Seite von
Abbildung 9, weshalb
kumErg auch auf 1 gesetzt wurde. Erhöhen wir nun den Wert von
Sleep() der Methode
doConsumingStuff() von 50 auf 300, dann sieht das Ergebnis wie folgt aus:
Hier endet
doConsumingStuff() aus dem Aufruf des Thread 1, bevor Thread 2 aufruft – wir erhalten also die 2 in
kumErg. Die Frage ist nun, wie wir es schaffen, dass sowohl bei einer
sleep() Zeit von 50, als auch 300 für
kumErg die 2 herauskommt. Der Grund für diese Problematik ist ja der gleichzeitige Zugriff der beiden Threads auf die Funktion
doConsumingStuff(). Eine Möglichkeit wäre, wenn wir eine
bool Variable hätten, welche immer dann auf
true ist, wenn gerade jemand in der Methode
doConsumingStuff() wäre und vor jedem Zugriff diese zyklisch prüfen würde, bis sie freigegeben wurde. In
doConsumingStuff() müsste dann am Anfang diese Variable mit
this.doConsumingStuffIsBlocked = true; gesetzt und am Ende wieder auf
false gesetzt werden. Der Aufruf in
doThreadedWork() müsste dann wie folgt aussehen:
Listing 7: Naive Umsetzung einer einfachen Synchronisation
Die grundsätzliche Funktionalität dieses Vorgehens sollte einleuchten –
doThreadedWork() würde also so lange mit dem Aufruf von
doConsumingStuff() warten, bis die Funktion vom aktuellen Nutzer freigegeben wurde. Allerdings hätten wir das Problem damit immer noch nicht vollständig in den Griff bekommen.
Es wäre zum einen möglich, dass genau in den 10 ms Wartezeit sich ein anderer Thread dazwischenschiebt – wir hätten also kein „first come first serve“ Verhalten. Zweitens ist es nicht
auszuschließen, dass zwischen der
while Schleife und dem Aufruf von
doConsumingStuff() ein anderer Thread ebenfalls
doConsumingStuff() aufruft und wir dann wieder einen parallelen Zugriff haben.
Synchronisierung
Um diese Probleme nun zu lösen, bieten die verschiedenen Programmiersprachen Konzepte an, den Zugriff auf zentrale Funktionen bzw. Objekte zu „synchronisieren“. C# bietet hier einen ganzen Strauß an
Möglichkeiten, von denen ich hier nur eine herauspicken werde. Wer hier tiefer einsteigen will, muss sich mit den einschlägigen Manuals und Büchern auseinandersetzen. Wir verwenden ein C# Konzept,
„Attribute“ vor Methoden zu setzen. Diese stellen eine Art Metainformation für die Laufzeitumgebung und den Compiler dar. Eine dieser Metainformationen ist, dass wir eine gesamte Methode synchronisieren wollen:
Listing 8: Synchronisation einer Methode in C#
Wir ergänzen also vor der Methode ein Attribut, welches in C# in eckigen Klammern notiert wird. Damit der Compiler dies akzeptiert, muss
System.Runtime.CompilerServices über
using bekannt gemacht werden. Wenn wir nun das Programm mit 50 ms Wartezeit laufen lassen, erhalten wir wieder das gleiche Ergebnis wie mit 300 ms – unsere Methode
doConsumingStuff() ist nun threadsicher. Aus Sicht der Performanceoptimierung haben wir damit aber den Vorteil der Arbeitsteilung verspielt:
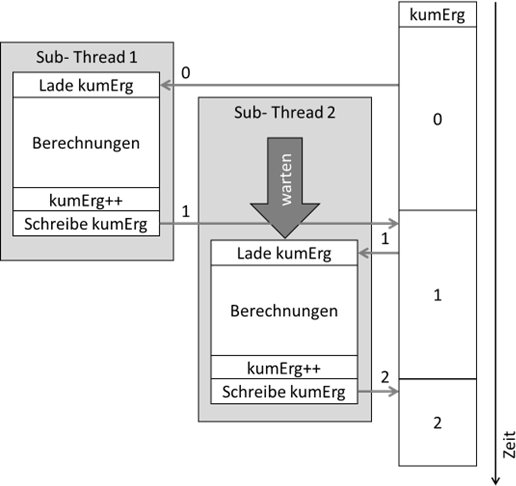
Abb.: 10: Ablauf bei Synchronisation einer Methode
Aufgrund der Nutzung einer zentralen Funktionalität kann keine Parallelisierung mehr erfolgen, was natürlich einleuchtend ist. Nun müssen wir uns nochmal vor Augen führen, was die Notwendigkeit der Synchronisation
in unserem Programm eigentlich bedingt, nämlich der Zugriff auf die Variable
kumErg. Wenn nun in den Berechnungen diese Variable eine Rolle spielt und zwischendurch nicht verändert werden kann, können wir das Programm schlichtweg nicht mit einer Parallelisierung beschleunigen,
da der „Bottleneck“
kumErg ist. Gehen wir nun mal davon aus, dass in unserer mit
Sleep(200) simulierten Berechnung in den ersten 100 ms
kumErg gar keine Rolle spielt, sondern nur in den zweiten 100 ms. Wenn dem so ist, können wir unsere Methode intelligenter gestalten, indem wir die beiden Teile der Simulation aufteilen:
Listing 9: Anpassung des Codes durch die Trennung der abhängigen Elemente der Simulation
Wie erwähnt ist diese Anpassung nur sinnvoll, wenn in der ersten Hälfte der mit
Sleep() simulierten Berechnung
kumErg keine Rolle spielt. Da die ganze Methode aber noch synchronisiert ist, haben wir (noch) nichts gewonnen. Nun haben wir zwei Möglichkeiten. Entweder wir lagern die drei markierten Codezeilen in ein
eigenes Unterprogramm aus und synchronisieren nur dieses Unterprogramm, oder wir synchronisieren nur einen Teil des
doConsumingStuff() Programms, was mit der statischen Klasse
Monitor ermöglicht wird:
Listing 10: Anpassung des Codes für eine effektivere Synchronisation
Kurze Erklärung der Codezeilen: Die
Monitor Klasse merkt sich beim Aufruf der
Enter() Methode das übergebene Objekt und sperrt dies für andere Threads. Mit
Exit() wird diese Sperre wieder aufgehoben.
Wir haben den gesperrten Bereich also auf das minimal notwendige begrenzt. Man spricht hier auf von einer atomaren Befehlssequenz – also ein kleinstmöglicher Codebereich, welcher nicht durch andere
Threads gestört werden darf. Die
Monitor Klasse übernimmt die Funktion einer Ampel, welche die Nutzung von Code freigibt oder blockiert. Solche Konstrukte nennt man in der Programmierung auch „Semaphore“, was eigentlich die Bezeichnung eines mechanischen Zugsignals ist.
Abb.: 11: Semaphore
C# bietet darüber hinaus noch weitere Mechanismen für das Sperren von Codebereichen an – unter anderem auch eine Klasse, welche von Microsoft direkt „Semaphore“ getauft wurde. Ein weiterer gängiger Begriff für
Elemente, welche solche kritischen parallelen Zugriffe regeln ist „Mutex“, was für „mutual exclusive“ (also in etwa „gegenseitig exklusiv“) steht. In C++ wird uns dieser Begriff begegnen. An diesem Punkt können
wir eine Frage klären, die sich vielleicht bei den
String Klassen dem ein oder anderen gestellt hat. Warum sind Strings immutable, also nicht veränderbar? Der Grund liegt unter Anderem in der Threadsicherheit. Wenn wir einen String haben, auf den mehrere Threads
zugreifen müssen, dann möchten wir allen die gleiche „Wahrheit“ bieten. Wenn der
String jedoch von einem
Thread geändert werden kann während der andere gerade darauf zugreift, wird das Ergebnis nicht mehr sicher vorhersagbar.
Mutlithreadingprojekt zur Performancesteigerung in C#
Nun, da wir ein grundsätzliches Verständnis von Threads haben, können wir uns an ein aufwändigeres Projekt wagen, welches von einem multithreaded Ansatz profitiert – die vor allem bei Mathematikern
beliebte Mandelbrotmenge aka. „Apfelmännchen“. Hier handelt es sich um ein sehr anschauliches Beispiel der Chaostheorie. Damit wir das Ganze auch wirklich verstehen, müssen wir ganz kurz in die
Mathematik, und zwar in die Welt der komplexen Zahlen abschweifen. Die Idee der komplexen Zahlen entstammt aus folgender Forderung:
j2=-1
Wer jetzt aber ins Grübeln kommt, der denkt erstmal richtig – eine (reelle) Zahl mit sich selbst multipliziert kann niemals einen negativen Wert ergeben, da eine negative Zahl im Quadrat immer positiv ist
(also bspw. -1 * -1 = +1). Die sogenannte „imaginäre Zahl“ j wurde aber genau so definiert, dass das Quadrat -1 ergibt (deswegen der Name „imaginäre Zahl“). Nun kann man eine Mischung aus imaginären
und reellen Zahlen herstellen, indem man sie einfach zusammenzählt: c = 3j + 5. Die Zahl c hat also den imaginären Wert 3 und den realen Wert 5, was man wiederum grafisch in einem Koordinatensystem darstellen kann:
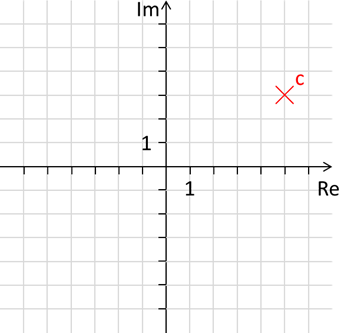
Abb.: 12: Komplexe Zahlenebene
Nun kann man komplexe Zahlen auch miteinander multiplizieren. c1 * c2 ist also
= (Im1 j + Re1) * (Im2 j + Re2)
= Im1 * Im2 j2 + Im1 j * Re2 + Re1 * Im2 j + Re1 * Re2
= (Im1 * Re2 + Re1 * Im2 ) j + (Re1 * Re2 - Im1 * Im2)
= Im1 * Im2 j2 + Im1 j * Re2 + Re1 * Im2 j + Re1 * Re2
= (Im1 * Re2 + Re1 * Im2 ) j + (Re1 * Re2 - Im1 * Im2)
und natürlich auch addieren. c1 + c2 ist:
= (Im1 j + Re1) + (Im2 j + Re2)
= (Im1 + Im2)j + Re1 + Re2
= (Im1 + Im2)j + Re1 + Re2
Eine weitere, wichtige Eigenschaft ist die Entfernung vom Ursprung, was mit dem Pythagoras ermöglicht wird, was wir auch als Betrag bezeichnen. Diese Funktionalitäten können wir nun in eine Klasse gießen:
Listing 11: Implementierung einer komplexen Zahlenklasse in C#
Nun können wir die Zahl 3j + 5 bspw. mit der Zahl 1j – 0.5 multiplizieren:
Listing 12: Multiplikation zweier komplexer Zahlen
Die Ausgabe lautet:
Wenn wir dies einzeichnen sehen wir, dass unser Punkt gedreht und verschoben wurde:
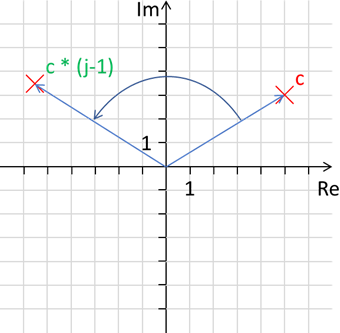
Abb.: 13: Multiplikation zweier komplexer Zahlen
Eine Multiplikation ist also eine Transformation des Ursprungspunktes, bei dem der Betrag die Verschiebung vom bzw. zum Ursprung festlegt und der Winkel zur Re-Achse den Rotationswinkel. Dies ist beispielsweise
für die Programmierung von Rotationen sehr hilfreich. Wenn wir bspw. eine Rotation um 15° benötigen, muss der Imaginärteil sin(15°) = 0.2588190451 und der Realteil cos(15°) = 0.9659258263 betragen. Folgender
Code würde also einen Kreis in 15° Schritten basierend auf unseren Punkt c abbilden:
Listing 13: Rotation des Punktes c in 15° Schritten
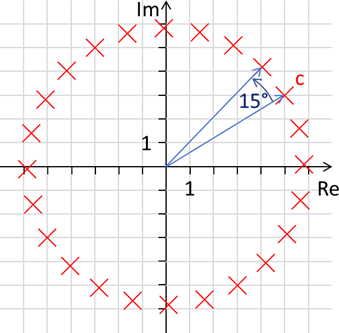
Abb.: 14: Rotation des Punktes c in 23 x 15° Schritten
Gerade für schnelle grafische Applikationen ist dies eine gern genommene Variante, animierte Rotationen zu implementieren, da bei einem zyklischen Update der Rotation nur einmal mit Sinus und Cosinus die Rotationsgeschwindigkeit
festgelegt wird und dann lediglich Multiplikationen und Additionen für die Neupositionierung benötigt werden. Auch die Überlagerung von Rotationen ist mit diesem Konzept sehr einfach machbar. In 3D Applikationen, in denen wir
drei Rotationsachsen kennen, hat man dieses Konzept um zwei imaginäre Werte erweitert – den sogenannten Quaternionen. Der Vollständigkeit halber zeige ich hier noch den Effekt der Verschiebung. In unserem Beispiel ist der
Betrag der multiplizierten komplexen Zahl 0.2588190451 j + 0.9659258263 gleich 1, da nach Pythagoras die Wurzel aus 0.25881904512 + 0.96592582632 eins ergibt. Wenn wir jedoch beide nun um 10 Prozent auf
0.232937141 j + 0.869333244 j reduzieren, erhalten wir folgenden Grafen, in dem die neuen Punkte immer jeweils um 10% in Richtung Ursprung wandern:
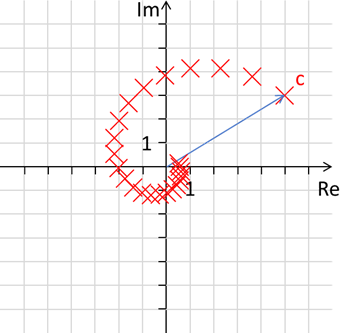
Abb.: 15: Rotation des Punktes c in 23 x 15° Schritten und Annäherung an 0 um je 10%
Ein gewisser Herr Benoît Mandelbrot hat nun entdeckt, dass eine iterative Berechnung folgender Formel:
zn+1=zn2+c
mit dem Startwert z0 = 0 und einem beliebigen Punkt c auf der komplexen Ebene ein chaotisches Verhalten, ähnlich einem Doppelpendel, aufweist. Die Idee ist, dass man c auf einem
beliebigen Punkt auf der komplexen Ebene festlegt, diesen zum Punkt z0 = 0 hinzuaddiert und diesen dann dem Punkt z1 zuordnet. Im nächsten Schritt quadriert man
z1 und addiert den Punkt c wieder hinzu. Das Ganze wiederholt man einige male und beobachtet, ob sich der Ergebnispunkt über eine gewisse Grenze vom Ursprung entfernt. Wenn dem so ist, markiert
man den Punkt mit einer Farbe, welche man abhängig von der Anzahl der Durchläufe wählen kann. Wenn er innerhalb der Grenze bleibt, markiert man den Punkt c einfach schwarz. Im folgenden Bild sehen wir die Abfolge des Punktes
c1=0,25 j + 0,25, welcher irgendwann im Punkt 0,354 j + 0,146 konvergiert. Insofern färben wir den Punkt c1 schwarz ein. Der Punkt
c2=0,3 j - 0,8 hingegen schaukelt sich auf und geht irgendwann über alle Grenzen hinaus, weshalb wir ihn mit einer Farbe belegen:
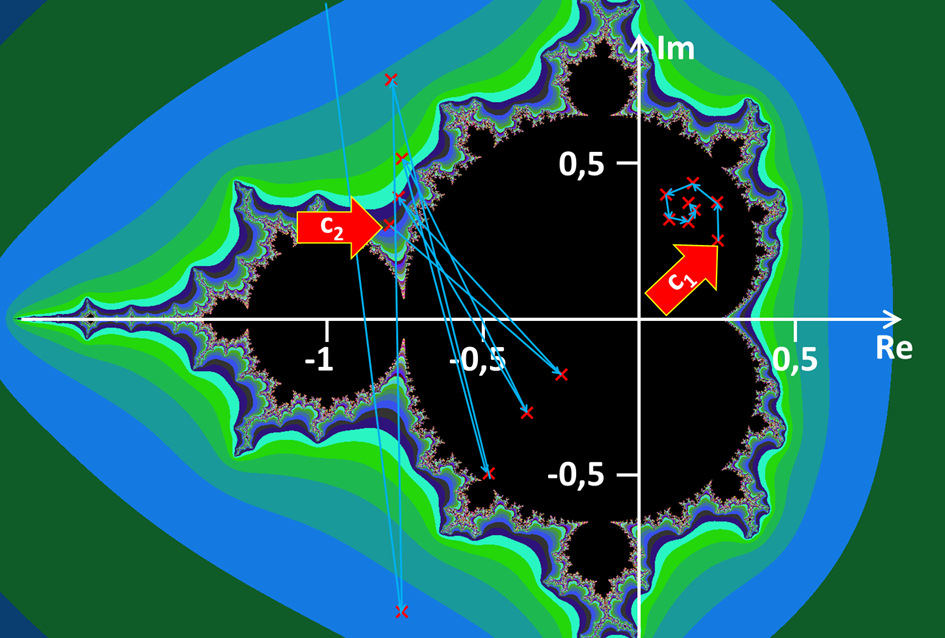
Abb.: 16: Konvergierender und nicht konvergierender Punkt der Mandelbrotmenge
Das Besondere an dieser Grafik ist nun, dass sie einen unendlich langen Umfang besitzt. Man kann also unendlich nah an die Grenze der schwarzen Menge „zoomen“:
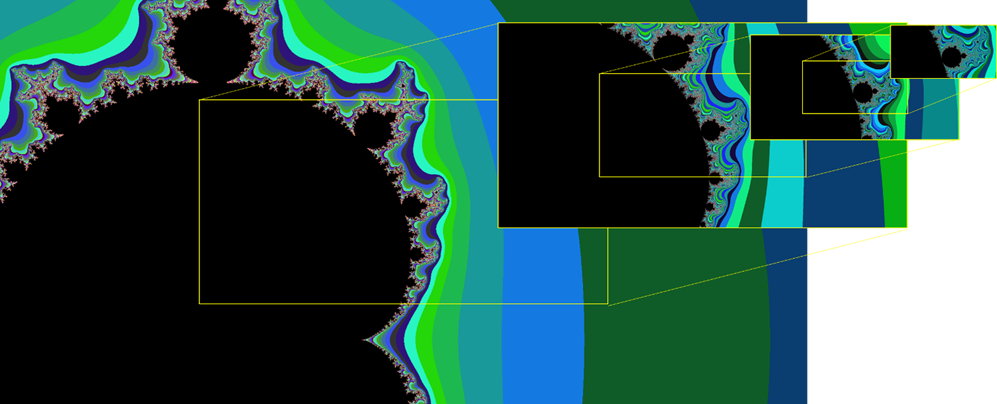
Abb.: 17: Zoom an die Grenze der Mandelbrotmenge
Je näher man an die Grenze geht, umso mehr Iterationen muss man durchführen, um feststellen zu können, ob der entsprechende Punkt konvergiert oder nicht. Aus Sicht des Grafen ist eine Erhöhung der Iterationen eine
Steigerung des Detailgrades. Also ein idealer Showcase für performancefressende Aktionen eines Prozessors. Das Besondere daran ist auch, dass jeder Punkt c unabhängig von allen anderen berechnet werden kann –
perfekt also für ein multithreaded Programm.
Um dieses Projekt zu realisieren, ergänzen wir unsere
ComplexNumber Klasse um ein paar Methoden. Dies dient zum einen dazu, dass wir weniger Code in der aufrufenden Klasse haben und zum anderen der Reduktion von Rechenschritten.
Listing 14: Ergänzungen der ComplexNumber Klasse für die Mandelbrot-Berechnung
Kurze Erklärung der Codezeilen: Die Methode
square() ist für das unkomplizierte Multiplizieren mit sich selbst. Der Vorteil ist, dass wir nicht für jede Multiplikation ein neues Objekt erzeugen müssen. Wichtig ist hier, dass wir das
Ergebnis der Realteilberechnung zuerst in eine Variable
r schreiben, danach den Imaginärteil mit dem „alten“ Realteil
re berechnen und danach erst die Rechenergebnisse in
re und
im überschreiben. Die nächste Methode dient der Rechenzeitoptimierung. Die Berechnung des Betrages benötigt laut Pythagoras eine Wurzel der Seitenquadrate. Es ist jedoch ineffizient
jedes mal die Wurzel zu ziehen – stattdessen quadrieren wir den Vergleichswert (also die zulässige Grenze, ab wann ein Punkt als „nicht konvergierend“ klassifiziert wird). Somit vergleichen wir
nicht den Abstand, sondern den quadrierten Abstand. Die Methode
addC() dient dazu, die Iteration über die verschiedenen
c Punkte zu vereinfachen. Schließlich gibt es noch die
reset() Methode, welche den Punkt zurücksetzt. Dadurch können wir das Objekt immer wieder verwenden und sparen somit das häufige Eingreifen des Garbagecollectors, der ja nicht mehr benötigte Objekte einsammenln muss.
Als nächstes müssen wir uns um ein Konzept der Datenhaltung kümmern. Das Ziel soll sein, in einer Pixelgrafik alle Punkte einzeln zu prüfen. Da dies eine zweidimensionale Datenstruktur ist,
werden wir diese genauso auch aufbauen – mit einem zweidimensionalen Array von
int Werten. Diese können wir dann einfach durch unser Bitmap Schreibprogramm aus dem
Kapitel 15 auf das Filesystem verbannen. Die
0x000000 war hierbei die Farbe Schwarz und Weiß die
0xFFFFFF. Wenn wir also eine Grafik mit 2048 x 1024 Bildpunkten haben möchten, benötigen wir das Array
new int[2048,1024].
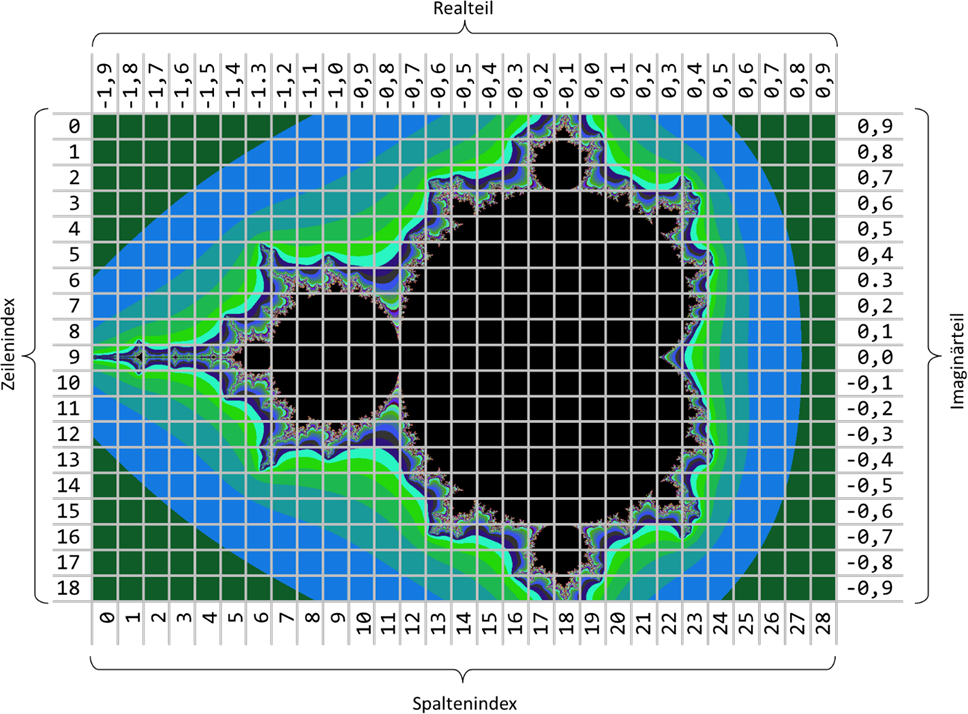
Abb.: 18: Zuordnung der Arraypositionen zur Mandelbrotmenge bei 19x29 Punkten
In der Abbildung sehen wir, dass die Arraypositionen oben links mit 0/0 beginnen und nach rechts die Spalten- und nach unten die Zeilenindizes erhöhen, das Koordinatensystem der komplexen Zahlen sich aber von der Mitte her
ausbreitet. Wir benötigen also noch ein Konzept, wie wir die Arraypositionen in das Koordinatensystem überführen. Hierzu brauchen wir die Größe eines Pixels. Im vereinfachten Bild der Abbildung ist ein Pixel genau
0,1 x 0,1 Längeneinheiten des Koordinatensystems. Diesen Wert speichern wir in einer Variablen
pixelDist vom Typ
double. Die Größe des Bildes ist somit Anzahl Pixel * pixelDist. Da wir meist die halbe Größe benötigen, speichern wir die halbe Breite in
halfDimRe und die halbe Höhe in
halfDimIm ab. Damit wir den Zoom Punkt beliebig verschieben können, wird einfach der Koordinatenwert der Mitte des abgebildeten Ausschnitts in der komplexen Ebene vorgegeben, mit
startRe und
startIm. Dies wird immer die Mitte der Bilddatei sein. Somit können wir den Koordinatenwert jedes Pixel bestimmen, welche durch
r (Row) und
c (Column) gegeben sind:
Pixel(r,c) = -1*(startIm - (halfDimIm - r) * pixelDist) j * startRe - (halfDimRe - c) * pixelDist
Die -1 vor dem Imaginärteil bildet die inverse Richtung der imaginären Achse (zeigt nach oben) und der Reihenfolge der Zeilenindizes (steigen nach unten) ab. Als nächstes überlegen wir uns die Logik für die
Abbildung der Iterationen in einen Farbwert. Die Farben liegen ja im Bereich von 0x000000 bis 0xFFFFFF und die maximalen Iterationen zwischen 0 und den aktuell vorgegebenen maximalen Iterationen.
Diese erhöhen sich aber mit der Erhöhung des Detailgrades. Wir werden später aber noch sehen, dass wir aufgrund der Rechengenauigkeit eine Obergrenze haben werden. Eine gute Annahme für die maximalen Iterationen
könnten wir dann ermitteln – ich greife jedoch vor und setze die maximale Anzahl der Iterationen mit 2500 an. Der ermittelte Iterationswert
i ist genau die Anzahl an Durchläufen, bei denen der Betrag von
z über einer vorgegebenen Grenze liegt. Insofern bietet es sich an, den Farbwert einfach im gleichen Verhältnis zu belegen:






Farbwert = i * 0xFFFFFF / 2500.0
Nachdem der Code natürlich etwas länger ist, gehen wir ihn hier Methode für Methode durch. Beginnen wir mit der Klasse
FractalBuilder und dort mit dem Konstruktor (und den Instanzvariablen):
Listing 15: Konstruktor der Klasse FactalBuilder
Kurze Erklärung der Codezeilen: Der Konstruktor kümmert sich lediglich um die Belegung aller Instanzvariablen. Damit wir innerhalb des Codes weniger rechnen müssen, habe ich sowohl
dimX als auch
dimY, als auch
halfDimRe bzw.
halfDimIm als Instanzvariablen gespeichert, obwohl sie direkt voneinander abhängen. Wie bereits erwähnt, wird der Schwellwert für einen nicht konvergierenden Punkt hier als Quadratzahl gespeichert,
um das Radizieren beim Pythagoras einzusparen. Das Array für die Pixel wird als Matrix erzeugt und trägt somit auf allen Position die 0 – was gleichzeitig die Farbe Schwarz bedeutet.
Die nächste Methode ist das „Herz“ der Applikation – die Berechnung der einzelnen Pixelfarben entsprechend der iterativen Rechenvorschrift von Mandelbrot:
Listing 16: Berechnung der Pixelfarbe der einzelnen Pixel
Kurze Erklärung der Codezeilen: Wie bereits erwähnt, werden die einzelnen
z Objekte nicht immer neu erzeugt, sondern es wird eines erzeugt, welches immer wieder verwendet wird um Garbagecollector Interaktionen zu reduzieren. Die beiden Schleifen gehen Zeilen und Spaltenweise durch das
gesamte Array. Innerhalb der Schleifen wird
z zuerst auf 0/0 zurückgesetzt, was für den ersten Durchlauf zwar unnötig, aber in allen Folgedurchläufen wichtig ist. Danach folgen die Rechenvorschriften für die Ermittlung des Real- bzw. Imaginärteils basierend
auf den Indexpositionen der Spalten bzw. Zeilen. Die folgende Schleife geht bis zur maximalen Anzahl der Iterationen durch. Sobald der quadrierte Betrag größer als der quadrierte Schwellwert ist, wird
i als Anzahl der Iterationen mit dem maximalen Farbwert in das Array entsprechend der Verhältnisbildung eingetragen und die Iterationsschleife beendet. Dies erfolgt nicht direkt im Array, sondern über einen Setter,
welcher später bei der multithreaded Version wichtig wird. Wenn die Schleife bis
maxIteration durchläuft ohne dass der Grenzwert überschritten wird, bleibt der Initialwert 0 auf der entsprechenden Arrayposition.
Die nächsten Methoden sind Supportmethoden, welche entweder bereits bekannt sind oder keine komplizierten Algorithmen umsetzen:
Listing 17: Supportmethoden für die Fraktalerstellung
Kurze Erklärung der Codezeilen: Die Methoden
startCalculation() und
setPixel() haben derzeit keine wirkliche Bedeutung – wir werden sie später bei der multithreaded Lösung benötigen.
writeDataToFile() ruft lediglich die Methodenfolge für die Byteerzeugung und dem Schreiben auf das Filesystem auf.
genBmpData() basiert auf den Erkenntnissen, welche wir im
Kapitel 15 besprochen haben – mit einigen kleineren Anpassungen für die
pixel Übernahme (siehe nächstes Listing).
Die Methoden der
BitmapGenerator Klasse passen wir an dieser Stelle noch ein wenig an, so dass wir lediglich das
pixel Array übernehmen und dort alle notwendigen Informationen herausnehmen. Dies kommt der eigentlichen Idee einer Bitmap Generierung am nächsten,
da wir die (Pixel-)Daten ja innerhalb unseres Programmes ja in einem zweidimensionalen Array vorhalten und hier alle relevanten Informationen bereits enthalten sind. Hierbei können wir demnach die
prepareBmp() gleich in die
genBmpData() Methode integrieren:
Listing 18: Anpassung der prepareBmp Methode auf das Pixel Array
Kurze Erklärung der Codezeilen: Die Parameterliste benötigt nun lediglich das
pixel Array. Ansonsten brauchen wir wieder die Presets des Headers, welche wir an den notwendigen Stellen mit den berechneten Werten überschreiben. Die Berechnung benötigt lediglich die Breite und Höhe,
was wir aus dem
pixel Array ermitteln. Die restlichen Berechnungen sind wie im
Kapitel 15. Neu ist nun lediglich die Übernahme der Farbdaten, welche wir nun Pixel für Pixel aus dem
pixel Array entnehmen und direkt ohne Umwege in das data Array schreiben
Nun können wir die Funktionalität starten, indem wir in der Main Methode ein Objekt der Klasse
FractalBuilder instanziieren, die Daten berechnen und als File schreiben:
Listing 19: Aufruf der Fraktalberechnung
Kurze Erklärung der Codezeilen: Die Bildgröße wird auf 2048x1024 Pixel gesetzt. Die Grenze für nicht konvergierende Punkte setzen wir auf 10 – also sobald ein Punkt mehr als die Länge 10 vom Ursprung entfernt ist,
sehen wir in als „nicht schwarzen Punkt“. Die angegebenen
startRe und
startIm Werte sind ein guter Startpunkt für spätere Zooms. Für’s erste beginnen wir mit dem „Zoom Faktor“ 0.001. Diesen werden wir später noch verändern. Bei diesem Zoom Faktor genügt eine Iterationszahl von 50
(sprich Detailgrad) vollkommen aus. Nun instanziieren wir das Objekt und übergeben die Werte. Nachdem die Berechnung mit
startCalcualtion() angetriggert wurde, können wir die Daten als Bitmap speichern.
Wenn wir das Programm nun starten, wird nach einer gewissen Zeit das Bitmap geschrieben, welches nach dem Öffnen wie folgt aussieht:
Abb.: 19: Fraktalbild mit den initialen Parametern
Nun wollen wir gleich mehrere Files hintereinanderschreiben und in die Grenze der Mandelbrotmenge hineinzoomen. Hierzu müssen wir mit feineren Zoomwerten auch die Anzahl der Iterationen anpassen:
Listing 20: Erzeugung mehrerer Bilder als Zoomfahrt in die Mandelbrotgrenze
Kurze Erklärung der Codezeilen: Damit wir die Performanceänderungen durch das Multithreading messen können, halten wir die Startzeit fest und bilden am Ende die Laufzeit der Erzeugungen. Die Iteration wird mit einer
Zählschleife von 50 Durchgängen erledigt. Den Zoomfaktor passen wir mit jeweils einer Division von 2 an, wordurch
pixelDist immer kleiner wird. Damit der Detailgrad sich entsprechend anpasst erhöhen wir die Durchlaufzahl um je 50. Das ist zwar kein mathematischer Zusammenhang, hat sich aber empirisch bewährt. Damit der User eine
Information über den aktuellen Status erhält, wird jeweils das zuletzt geschriebene File auf der Konsole erwähnt.
Wenn wir den Code laufen lassen, finden wir im angegebenen Verzeichnis 50 Bitmap Bilder. Die Laufzeit pendelt sich für die Gesamtberechnung auf meinem System auf ca. 2879 Sekunden ein, was ca. 48 Minuten beträgt.
Die Ergebnisse können wieder mit einem Grafikprogramm begutachtet werden. Hier als Beispiel die Files
myFractal_10.bmp und
myFractal_38.bmp:
Abb.: 20: Fraktaldatei Nr. 10 und 38
Interessant ist, dass ab Nummer 46 die Bilder recht pixelig werden – hier die Bilder für
myFractal_46.bmp und
myFractal_49.bmp:
Abb.: 21: Fraktaldatei Nr. 46 und 49
Das Problem ist hier, dass die
double Werte zu ungenau werden und die Details somit nicht mehr auflösen können. Bei 50 Iterationen liegt der Wert für
pixelDist bei ca. 1x10-18. Pro Rechenzyklus werden die komplexen Zahlen einmal quadriert – also bei bspw. vier Rechenzyklen vier mal, was bei
1x10-18 ca.
1x10-286 ergibt. Im nächsten Schritt liegen wir dann bereits außerhalb der darstellbaren Genauigkeit von
1x10-308. Um dieses Problem zu umgehen, müssten wir nun einen anderen Datentyp verwenden, der keine Untergrenze bezüglich Genauigkeit kennt. Für unsere Zwecke reicht die Genauigkeit jedoch erstmal aus.
Hier sehen wir auch den Wert unserer maximalen Iterationen. Wir erhöhen bei jedem Durchgang die Iterationsanzahl um 50 – das Ganze machen wir 50 mal, weshalb wir bei 2500 laden.
Parallelisierung in C#
Nun wollen wir das Ganze mal auf mehrere Threads verteilen. Hierzu brauchen wir erstmal ein paar Vorüberlegungen. Die wichtigste haben wir weiter oben bereits angesprochen – der Algorithmus muss in
voneinander unabhängige Teilaufgaben zerlegbar sein. Da jeder Pixelwert unabhängig von allen anderen berechnet wird, ist diese Voraussetzung hier also schon gegeben. Danach folgt die Überlegung,
wie wir die Aktivitäten schneiden. Wir müssen unsere Grafik also in möglichst gleichgroße Teile zerlegen, welche wir je von einem Thread erledigen lassen:
Abb.: 22: Zerlegung der Pixel in Bereiche
Hierbei sollten wir nun auf folgende Dinge achten:
- Zentrale Datenelemente wie das pixel Array müssen synchronisiert beschrieben werden.
- Die Bereiche sollten zwar möglichst gleichgroß sein, es soll jedoch kein Pixel zweimal berechnet werden.
- Die Methode, welche die Threads startet, sollte wiederum auch warten, bis alle fertig sind.
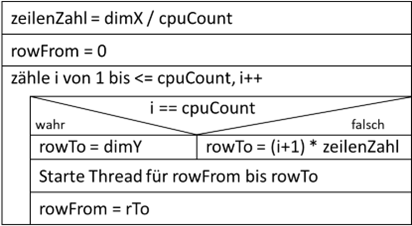
Zuerst überlegen wir uns einen Algorithmus, wie wir die Höhe unserer Grafik in möglichst gleichgroße Teile zerlegen, jedoch keine Überschneidungen erzeugen. Hierzu müssen wir uns um die Sonderfälle kümmern,
bei denen die Anzahl der Zeilen kein Vielfaches der Threadanzahl ist. Gehen wir mal davon aus, wir haben 310 Zeilen und wollen das Ganze mit vier Threads abarbeiten. Ein Thread erhält also
310 / 4 = 77,5 Zeilen. Da aber keine halben Zeilen existieren, erhält jeder Thread 77 Zeilen, was auch bei einer Division von Integer Zahlen herauskommen würde. Vier mal 77 ist aber 308 Zeilen, damit fehlen 2.
Also benötigen wir einen Algorithmus, der dem letzten Thread die verbliebenen 2 Zeilen zusätzlich zuordnet. Hierzu könnten wir folgenden Algorithmus verwenden:
Abb.: 23: Ermittlung Zeilenbereiche für Threads
Diese Logik müssen wir somit in die Methode einbauen, welche den Rechenvorgang startet, was eine Anpassung von
startCalculation() erforderlich macht:
Listing 21: Vorbereitung der Threads
Kurze Erklärung der Codezeilen: Die Anzahl der aktuell laufenden Threads muss in einer eigenen Instanzvariablen gehalten werden. Somit können wir feststellen, ob alle gestarteten Threads terminiert sind.
Da wir nicht immer wissen, wie viele Kerne die CPU hat, übergeben wir den Wert als Parameter. Die Zählschleife ist wie in
Abbildung 23 vorgegeben. Die Verzweigung habe ich mit einem ternären Operator realisiert, da er sich hier aufgrund der Zuweisung eines Wertes in
rTo anbietet – die Lösung mit einer Verzweigung würde jedoch auch gehen. Nun wird eine Hilfsklasse für die multithreaded Ausführung erzeugt, in der wir die für die Teilberechnung notwendigen Informationen
eintragen – von welcher bis zu welcher Zeile soll gerechnet werden. Danach kommt noch die Referenz auf sich selbst (also dem
FractalBuilder Objekt), um den Threads die Möglichkeit zu geben sich bei Fertigstellung zurückzumelden. Schließlich geben wir den Threads noch einen Namen, damit wir während der Entwicklung sehen, wo unsere
Applikation gerade steht. Die Anzahl der gestarteten Threads müssen wir hochzählen, damit wir später sehen, ob sich alle Threads wieder zurückgemeldet haben. Hier wäre es auch denkbar, die Threads in ein
dynamisches Array zu speichern und dieses dann für jeden terminierten Thread zu reduzieren. Wichtig ist, dass wir immer genau wissen, ob noch mindestens ein Thread arbeitet oder ob alle fertig sind. Ich
zähle jedoch einfach die Anzahl der gestarteten Threads hoch, welche durch die terminierten Threads wieder heruntergezählt werden. Da dies aber eine zentrale Variable ist, müssen wir das hoch- und runterzählen
in einer Methode durchführen, welche wir synchronisieren können. Den Zähler der Threads prüfen wir schließlich in der unteren Schleife, welche einfach nur solange wartet, bis alle gestarteten Threads sich zurückgemeldet haben.
In der Klasse
FractalBuilder müssen wir noch zwei weitere Ergänzungen aufgrund notwendiger Synchronisierungen machen. Zum einen muss der Schreibzugriff auf das zentrale
pixel Array synchronisiert werden und zum anderen benötigen wir eine Methode für die Anpassung des
noOfThreads Zähler:
Listing 22: Synchronisierte Methoden
Kurze Erklärung der Codezeilen:
changeNoOfThreads() ist eine zentrale Methode zur Anpassung der Variable
noOfThreads. Da sie sowohl vom Main Thread (hier wird inkrementiert) als auch von den Subthreads angepasst (hier wird dekrementiert) angepasst wird, fasse ich beides in einer Methode zusammen und
synchronisiere sie. Der Parameter bestimmt einfach, ob inkremetiert oder dekrementiert wird.
setPixel() hatten wir bereits in der singlethreaded Version und muss somit lediglich synchronisiert werden.
Nun benötigen wir eine Methode, welche vom Thread aufgerufen werden kann, sobald er mit seiner Arbeit fertig ist. Diese reduziert lediglich den
noOfThreads Zähler mit der
changeNoOfThreads() Methode. Da diese bereits synchronisiert ist, muss
threadDone() nicht mehr synchronisiert werden.
Listing 23: Signal, dass ein Thread beendet wurde
Die wichtigste Methode ist
calcPixel(). Diese haben wir zwar für die singlethreaded Version schon geschrieben, diese muss aber dahingehend angepasst werden, dass wir den zu rechnenden Bereich per Parameter festlegen können:
Listing 24: Anpassung von calcPixel() auf dynamische Rechenbereiche
Kurze Erklärung der Codezeilen: Wir übergeben als Parameter einfach den Zeilenbereich, der von
calcPixel() berechnet werden soll. Dann müssen wir den Zähler für die Zeilen auf die übergebenen Grenzen anpassen, wobei die Untergrenze inklusive ist (
r startet also tatsächlich von
fromY) und die Obergrenze exklusive (also
r < toY). Dadurch konnten wir in
startCalculation() die Zuweisung
rFrom = rTo vornehmen, ohne dass die Grenzen doppelt gerechnet werden.
Nun können wir die Klasse
FractalWorker umsetzen. Sie ist lediglich für den angepassten Aufruf der Methode
calcPixel() zuständig:
Abbildung 24: Threaded Worker Klasse
Kurze Erklärung der Codezeilen: Die Klasse speichert die Rechengrenzen und einen Namen für Debugging Augsaben ab. Weiterhin benötigen wir eine Referenz auf das Objekt der Klasse
FractalBuilder, welches wir bei Vollendung der Arbeit informieren müssen. Die
doWork() Methode wird durch den Thread aufgerufen und gibt erstmal eine kurze Info aus. Danach werden die Pixel berechnet. Über den Aufruf von
threadDone() wird der
FractalBuilder informiert, dass dieser Thread nun zu ende ist.
In unserem Hauptprogramm müssen wir nun den Aufruf von
startCalculation() auf
startCalculation(2) ändern, damit wir zwei Threads mit der Berechnung beauftragen:
Abbildung 25: Aufruf der multithreaded Berechnung im Hauptprogramm
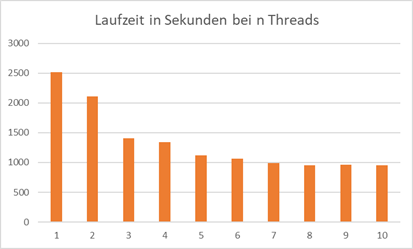
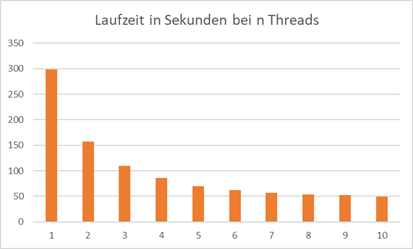
Bei zwei Threads komme ich auf meinem System nun auf eine Laufzeit von ca. 2108 Sekunden, was ca. 35 Minuten beträgt – sprich weniger als die Hälfte der ursprünglichen Bearbeitungszeit.
Die multithreaded Lösung ist also nicht um das n-fache schneller. Hierfür gibt es nun zwei wesentliche Gründe. Zum einen gibt es aufgrund der Synchronisation Zeitverluste und zum anderen
haben wir einen Overhead aufgrund der Threadverwaltung. In der Grafik sehen wir nun die Laufzeiten der multithreaded Lösung mit 1 bis 10 Threads:
Abb.: 24: Laufzeiten bei 1 bis 10 Threads in C#
Ich muss hier allerdings wieder betonen, dass diese Zahlen nicht repräsentativ sind, da ich für die Laufzeitmessung nicht alle Störeffekte ausgeschlossen habe und die Werte lediglich einen
Trendaussage liefern sollen. Ab zwei Threads „lohnt“ es sich aber tatsächlich, einen multithreaded Ansatz zu programmieren. Weiterhin sehen wir, dass wir ab 5 Threads keine große Verbesserung der
Rechenzeiten verbuchen können. Da ich ein System mit 8 Rechenkernen habe und wir aufgrund des Main Threads eigentlich immer einen Thread hinzufügen müssen – auch wenn er nicht viel ausmacht – ist das doch
bemerkenswert. Aber wie gesagt, die Zahlen sind nur eine grobe Trendaussage.
Threads in Java
Sehen wir uns das Ganze mal in Java an. Die Laufzeitumgebung von Java ist in puncto Performance extrem gut aufgestellt. Als erstes müssen wir verstehen, wie Java mit Threads umgeht.
Die Grundideen sind zwar ähnlich zu C#, jedoch finden wir ein paar feine Unterschiede.
Der erste auffallende Unterschied ist, dass wir in Java die Methode, welche durch den
Thread initial aufgerufen wird, nicht frei benennen können. In C# war es möglich, bzw. notwendig, diese Methode im Konstruktor von
Thread() anzugeben. Java geht hier anders vor. Das Konzept deckt sich mit dem fest definierten Namen der Startmethode für den Main Thread. Hier haben wir auch nicht die Möglichkeit festzulegen, wie die
main-Methode heißt. Sie ist festgelegt auf
main(String[] args). Genauso ist die Startmethode eines sub-Threads festgelegt als
run(). Dadurch benötigt der Konstruktor für die Thread Klasse nicht eine Methode, sondern ein Objekt, welches diese
run() Methode implementiert hat. Damit die Thread Klasse dies sicherstellen kann, muss das übergebene Objekt das Interface
Runnable implementieren, wo schlichtweg die
run() Methode gefordert wird. Da wir wieder die wesentlichen Codeelemente von C# übernehmen können, gehe ich hier nur auf die threadbezogenen Unterschiede ein (den gesamten Code findet man wiederum
in https://github.com/maikaicher/book1):
Listing 25: Implementierung des Runnable Interfaces in Java
Kurze Erklärung der Codezeilen: Das Interface
Runnable verlangt lediglich die
run() Methode.
@Override signalisiert lediglich, dass es sich um die Überschreibung einer Interfacemethode handelt.
Java kennt wie C# auch die
sleep() Funktionalität, wobei in Java eine
InterruptedException abgefangen werden muss. Das Starten eines Threads ist wiederum vergleichbar mit C#, lediglich, dass beim
Thread Konstruktor nur das Objekt des Workers mitgegeben werden muss und nicht die Methode (da die Methode in Java ja namentlich fest definiert ist) und der Startbefehl klein geschrieben wird.
Listing 26: Starten und Pausieren des Threads in Java
Nun fehlt nur noch der Java Syntax für die Synchronisation von Methodenaufrufen. Java sieht hier das Schlüsselwort
synchronized für die Methoden vor.
Listing 27: Synchronisation von Methoden in Java
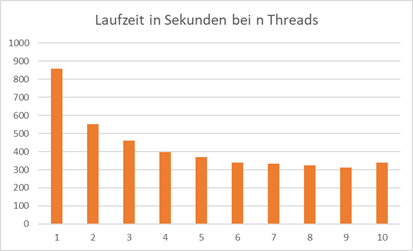
Überraschenderweise kommt Java sehr viel besser mit dieser Aufgabe zurecht. Die Laufzeiten liegen weit unter denen von C#, obwohl der Code im Wesentlichen gleich ist. Singlethreaded benötigt Java 303 Sekunden!
Abb.: 25: Laufzeiten bei 1 bis 10 Threads in Java
Hier sieht man ebenfalls eine deutliche Verbesserung bis ca. 5-6 Threads. Danach können keine wirklichen Performancevorteile mehr identifiziert werden. Eine leichte Präferenz von geraden Threadzahlen könnte
man in die Rohdaten interpretieren, aber im Großen und Ganzen ist 5-6 Threads hier sinnvoll. 8 Threads bringen auf meinem System mit 8 Kernen zwar auch einen leichten Vorteil, dieser ist aber eher gering.
Threads in C++
Realisieren wir das Programm nun in C++. Während wir von C# in Richtung Java den Großteil des Codes einfach kopieren konnten, müssen wir in C++ die Klassenstruktur auf den C++ Syntax anpassen.
Die Funktionen zum Schreiben der Bytes können aus dem C-Codes des
Kapitel 15 mit den üblichen Anpassungen auf das
pixel Array übernehmen. Den Code für das C++ Programm habe ich wie die anderen in GitHub online gestellt – doch auf ein paar Dinge müssen wir hier trotzdem kurz eingehen. C++ ist zusammen mit C die
einzige hier beschriebene Sprache, welche ohne eine spezielle Laufzeitumgebung auskommt. Dies vereinfacht zwar die Einrichtung eines fertigen Programmes auf einem System – es gibt ja keine Abhängigkeiten
zu einer eventuell benötigten Laufzeitumgebung – aber die Tatsache, dass die Laufzeitumgebung nun mal nicht definiert ist, macht die Programmierung komplizierter. Bei den bisherigen Programmen war dies
kein großes Problem, da wir keine speziellen Funktionalitäten genutzt haben. Beim Multithreading ist das schon schwieriger. Die Unterstützung für multithreaded Funktionen bedarf speziellen Bibliotheken,
welche nicht zwingend auf allen Systemen laufen. Für unser Programm verwende ich die Klasse
std::thread. Sie ist zwar eigentlich für Linux Systeme geschaffen worden, funktioniert aber auch bei den meisten Windows Systemen. Wer die POSIX (Portable Operating System Interface) Variante nutzen möchte,
welche extra für flexiblere Einsätze konzipiert wurde, muss noch etwas tiefer in die Konfiguration des Compilers einsteigen. Da wir hier aber nur die grundsätzlichen Konzepte ansehen wollen, gehe ich den aus
Sicht der Installation unserer Entwicklungsumgebung einfacheren Weg.
Um in C++ mit der
std::thread Klasse arbeiten zu können, müssen wir mehrere Dinge beachten. Zuerst benötigen wir eine Funktion, welche im Rahmen eines Threads arbeiten kann.
Diese hat üblicherweise keinen Rückgabewert, kann aber beliebig viele Parameter aufweisen. Für unsere Fraktalberechnung sieht die Funktion wie folgt aus:
Listing 28: "trhreadable" Funktion
Kurze Erklärung der Codezeilen: Im Gegensatz zu C# oder Java müssen wir dieser Funktion keine besonderen Eigenschaften zuweisen. Die Parameter können als Zeiger oder als Wert übergeben werden. Da der
FractalBuilder aber ein Objekt ist und die multithreaded Aktion der Pixelberechnung ausführen soll, benötigen wir die Referenz hierauf als Zeiger.
Die einzelnen Threads speichern wir in einem Vektor (also dynamischen Array) vom Typ
std::thread:
Listing 29: Threadhandling in C++ für Fraktalbildung
Kurze Erklärung der Codezeilen: Die Includes werden für das Threading
(<thread>), die Synchronisation von Zugriffen
(<mutex>) und die Erzeugung eines dynamischen Arrays für die Threads
(<vector>) benötigt. In der Funktion, welche die Threads erzeugt
startMulti() wird zuerst ein Vektor erstellt, welcher alle Threads beinhaltet. Wir benötigen diese Liste, da wir später die Threads "joinen" müssen – mehr dazu gleich. Danach erzeugen wir den
FractalBuilder, genauso wie in C# oder Java und errechnen die Start-und Endpunkte der Berechnungsthreads. Danach wird der Thread mit Hilfe der
std::thread() Funktion erstellt. Als Parameter wird die Methode erwartet, welche im Thread ausgeführt werden soll. Diese hatten wir
threadedMethod getauft. Danach werden noch die Paramter dieser Methode übergeben, der
FractalBuilder fb, der Start und der Endwert der Berechnng. Da wir den
FractalBuilder als Referenz übergeben müssen, zwingt uns
std::thread dies über einen "Referenz Wrapper"
std::ref() zu gehen. Dies ist notwendig, da der Zugriff aus einem eigenen Thread nicht beliebig erfolgen kann. Die Kontrolle über diesen Zugriff übernimmt der Wrapper (wir erinnern uns – die
Verteilung einzelner Aufgaben auf unterschiedliche Hardware Cores erfordert mitunter einen komplizierteren Speicherzugriff). Den Thread platzieren wir im Vektor über
push_back(). Nun gehen wir über die Threads im Vektor joinen sie. "Joinen" bedeutet in diesem Zusammenhang, dass die parallel laufenden Threads wieder sauber in den Main-Thread eingefast werden müssen.
Im Prinzip "wartet" der Main-Thread einfach, bis sich alle parallelen Threads zurückgemeldet haben (dies mussten wir in C# selbst bauen). Tun wir dies nicht, erfolgt eine Exception in der Ausführung.
Da alle Threads beendet sein müssen ist es ok, einfach den Vektor der Reihenach durchzugehen. Wir warten, bis der erste Thread gejoined wurd – also fertig ist und gehen dann auf den nächsten.
Ist dieser längst fertig, müssen wir nicht warten, sondern joinen ihn sofort. Somit gehen wir alle threads durch. Am Schluss leeren wir unseren Vektor und die Prozedur kann für das nächste Image von neuem beginnen.
Zum Schluss müssen wir uns noch um die Synchronisation der Zugriffe auf die zentralen Komponenten kümmern und zwar dem
pixel Array und dem
noOfThreads Zähler. Anders als in Java und C# müssen wir hier den Lock selbst realisieren. Dies erfolgt mit einem
„mutex(1)“, den wir mit Hilfe von
lock() sperren und mit
unlock() wieder freigeben können. Das ist vergleichbar mit den Monitorklassen oder den Semaphoren. Jede Ressource erhält hier seinen eigenen mutex:
(1) „mutual exclusive“ also in etwa „gegenseitig exklusiv“
Listing 30: Synchronisierung auf gemeinsame Ressourcen in C++
Kurze Erklärung der Codezeilen: Die Mutex Objekte finden sich unter
std::mutex und müssen mit
#include <mutex> bekannt gemacht werden. Da wir zwei Ressourcenzugriffe synchronisieren müssen, benötigen wir zwei Objekte. Beim Zugriff, bspw. über den setter, sperren wir den Mutex mit
lock() und am Ende wird er via
unlock() wieder freigegeben.
Lassen wir das Programm in C++ mit unterschiedlicher Threadanzahl laufen, sehen wir folgendes Verhalten:
Abb.: 26: Laufzeiten bei n Threads in C++
Das relative Verhalten ist wieder vergleichbar mit C# bzw. Java. Aber auch hier zeigt sich, dass die Java Ingenieure ihren JIT Compiler sehr gut im Griff haben, da C++ auch hier hinter Java zurückliegt.
Ein eingefleischter C++ Entwickler würde jedoch in der Lage sein, den Code noch weiter zu optimieren – es geht uns hier aber erstmal „nur“ um das Grundsätzliche. Soweit eine Lösung mit C++. Dies ist in der
Tat wörtlich zu nehmen – es handelt sich nur um „eine“ mögliche Lösung, die zu allem Überfluss nicht auf jedem System so funktionieren wird. Es müssen teilweise die korrekten Bibliotheken eingebunden,
teilweise die Compilerbefehle angepasst werden usw. usf. Ich habe auf meinem System die Installation exakt laut
Kapitel 22 durchgeführt und das dürfte somit auf vergleichbaren Systemen zu gleichen Ergebnissen führen. Wenn nicht, muss man den steinigen Weg der
Detailanalyse gehen und alle Eventualitäten ausschließen. Das ist mühsam – aber leider gerade bei C++ (und auch C) ein oft notwendiges Übel. Wie bereits weiter oben erwähnt, haben Programmiersprachen,
welche auf einer Laufzeitumgebung laufen (und das sind nun mal alle anderen hier beschriebenen) dieses Problem nicht, da die Laufzeitumgebung aus Sicht des Programms genormt ist.
Skriptsprachen
Sehen wir nun die Skriptsprachen vor dem Hintergrund des Multithreadings an, wo wir meist eine besondere Herausforderung haben. Der Skriptspracheninterpreter stellt ja ein Programm dar, welches wiederum
die Skriptprogramme laufen lässt. Nun ist das vom Architekturgrundgedanken her erstmal ähnlich wie die Laufzeitumgebungen von Java oder C#, welche ja auch „nur“ Code interpretieren, der zwar kompiliert, aber
nicht direkt auf dem Prozessor ausgeführt wird. Die ursprünglich geplante Nutzungsweise von Skripten war jedoch eine andere als bei C# oder Java. Sie sollten erstmal „nur“ die Abarbeitung von kleineren
Programmen und Aufgaben erledigen. In diesen Fällen ist Multithreading erstmal nicht wirklich relevant, weshalb man die Skriptspracheninterpreter oftmals so gestaltet hat, dass Multithreading nicht
unterstützt wird. JavaScript und Python haben in der Tat einen singlethreaded Interpreter – man kann also erstmal keinen multithreaded Code schreiben. Ein wichtiger Grund liegt darin, dass man den
Problemen von zeitgleichen Speicherzugriffen von vorneherein aus dem Weg gehen wollte.
Mit zunehmender Popularität von Skriptsprachen auch für highperformance Aktionen – ich denke hier an die rechenintensiven Python Programme in der KI-Welt – mussten sich die Entwickler dieser Interpreter
etwas einfallen lassen. Die Ergebnisse dieser Entwicklungen sind jedoch sehr stark von den einzelnen „typischen“ Anwendungsfällen der jeweiligen Sprachen getrieben. PHP wird bspw. fast ausschließlich im
Webbereich für die Programmierung serverseitiger Funktionalitäten genutzt. Die Hauptaufgabe ist also einen Request zu erhalten, diesen zu bearbeiten und ihn anschließend wieder an den Aufrufer zurückzusenden.
Hochkomplexe rechenaufwändige Aktionen sind hier eher nicht zu erwarten. Stand 2022 werden die multithreading Möglichkeiten von PHP auf den Applicationservern somit nicht unterstützt, sondern nur in gewissen
Grenzen in der „Stand Alone“ Nutzung von PHP. Ähnliches gilt für JavaScript. Wir haben hier entweder clientseitige Aufgaben im Webbereich – also das dynamische Aufbauen von HTML Seiten, oder serverseitige Aktionen,
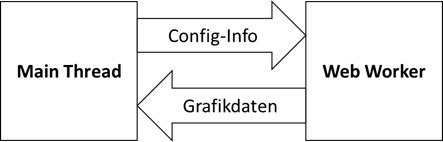
für die wiederum das gleiche gilt wie für PHP. Mit den serverseitigen Worker Threads und den clientseitigen Web Worker hat JavaScript zwar die Möglichkeit für paralleles Arbeiten geschaffen – für solch komplexe
Aufgaben wie die parallele Berechnung von Fraktalen auf mehr als einem Worker Thread muss man aber einige Limitationen umschiffen, welche vor allem in der Problematik des gemeinsamen Speicherbereiches liegen.
Der „Trick“, welchen die Python und JavaScript Ingenieure anwenden ist, dass man einfach mehrere Instanzen des Interpreters laufen lässt. Dadurch ergeben sich jedoch eben die Probleme beim Datenaustausch zwischen
den einzelnen Instanzen, welche sich – zumindest Stand 2022 – nur mit eher umständlichen Konstrukten beheben lassen. Insofern werde ich mich bei den Skriptsprachen nur um die grundsätzlichen Möglichkeiten des
Multithreadings kümmern und versuchen, möglichst viele Aspekte für den „normalen“ Gebrauch der Sprachen zu beleuchten.
Besonderheiten in JavaScript
Beginnen wir also mit JavaScript. Hier müssen wir erstmal etwas weiter „ausholen“, da wir das Verhalten von JavaScript nur mit einem Grundverständnis der Gesamtarchitektur durchdringen können. Dies hat zur
Konsequenz, dass wir uns nun einige Absätze mit Themen beschäftigen müssen, welche eigentlich nichts mit Multithreading zu tun haben. Wenn wir aber die Unterschiede zwischen asynchroner Verarbeitung und
echtem Multithreading in JavaScript nicht exakt verstehen, werden wir große Mühe haben, den Spezifikationen und Erklärungen zu folgen, welche uns bei weiterreichenden Recherchen im Internet begegnen werden.
Ursprünglich war JavaScript ausschließlich für den Webbrowser entworfen worden. Hier gab es zwei wesentliche Aktionen – die Verarbeitung von Befehlen im JavaScript Code und das Rendern von Informationen im
Browserfenster. Letzteres muss nun nicht mit maximaler Geschwindigkeit (oder besser „Frequenz“) erfolgen, sondern nur so schnell, wie die Grafikkarte das Neuzeichnen wiederholt – was im Regelfall 60
mal pro Sekunde ist. Weiterhin hat man sich nun dazu entschlossen, den JavaScript Interpreter als eine singlethreaded Applikation aufzubauen. Ein Grund war, damit man sich um die Probleme von multithreaded
Applikationen wie den gleichzeitigen Zugriffen auf Ressourcen nicht kümmern muss – das Programmieren ist also weniger „Fehleranfällig“. Die Codeabarbeitung und das Rendern sind aber nun doch zwei Aktionen, welche
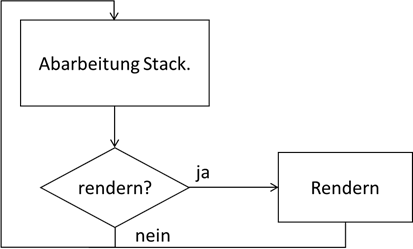
unabhängig voneinander erfolgen müssen. Die prinzipielle technische Lösung ist, dass ein Programm zyklisch durchläuft und eventuell abzuarbeitenden Code in den Zyklus eingefast. Immer, wenn der Browser es für
notwendig hält die Grafiken zu erneuern – also zu „rendern“ – wird dies in den Zyklus eingebaut:
Abb.: 27: Vereinfachte Event Loop
Wenn wir nun ein Programm starten, so wird es in den Stack geladen und ausgeführt – so wie wir es weiter oben schon mal festgestellt haben. Wenn der Stack „abgearbeitet“ wurde – er also leer ist – läuft der
Zyklus wieder weiter und kann sich um das Rendern kümmern. In node.js ist das Verhalten ähnlich – das Rendern fällt jedoch weg. Sehen wir uns trotzdem mal folgendes Programm mal an und starten es unter node.js:
Listing 31: Blockieren der Abarbeitung durch eine rechenaufwändige Funktion
Kurze Erklärung der Codezeilen: Zuerst loggen wir auf die Konsole den Start des Programms. Danach wird eine (zugegebenermaßen funktional eher sinnolse) Funktion aufgerufen, welche einfach nur für eine gewisse vorgegebene
Zeit eine einfache Schleife durchführt und einen Zähler mitlaufen lässt. Der Parameter ist einfach nur die Laufzeit in Millisekunden. Ist die Methode fertig, wird der Zähler zurückgegeben und die durchschnittliche Zykluszeit ausgegeben.
Starten wir das Programm sehen wir, dass zwischen den beiden Loggingausgaben tatsächlich fünf Sekunden vergehen und die Zykluszeit irgendwo im zweistelligen Nanosekundenbereich liegt. Nun wollen wir aber prüfen, ob unser
Thread noch in der Lage ist, andere Dinge zu tun. Dazu portieren wir unseren Code nun in den Browser. Hier haben wir die Möglichkeit während der Ausführung noch mit Hilfe von Interaktionen wie Button Klicks einzugreifen.
Hierfür erzeugen wir das File
LoopTest.html mit folgendem Inhalt:
Abbildung 30: HTML/JavaScript zur Überprüfung des Ausführungsverhalten
Kurze Erklärung der Codezeilen: Der HTML Rahmen ist aus dem
Kapitel 3 übernommen. Ich habe im Body des Files drei Buttons platziert. Der Erste soll den „rechenaufwändigen“ Code starten und die anderen zwei sollen lediglich überprüfen, ob wir noch
interagieren können, indem auf dem Loggingbereich eine Nachricht platziert wird. Am Ende des Bodys ist ein HTML Element
<div> mit der id
„logOut“, in das ich die Logging Informationen schreibe. Die Buttons rufen nun die Methoden
startCode() für den eigentlichen Code aus und
check1() bzw.
check2() für die Interaktionsprüfung. Das Logging wird mit
logInfo() erledigt, welches im HTML das Element mit der id
„logOut“ sucht und dort einen Zeilenumbruch
<br/> und die zu loggende Information anhängt.
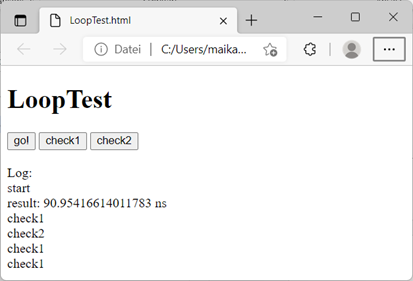
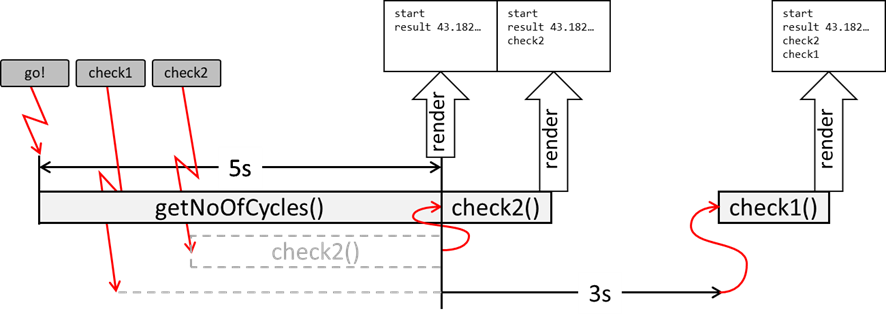
Nun öffnen wir mit einem Doppelklick das File und klicken auf den Button
„go!“. Überraschenderweise passiert erstmal gar nichts. Nicht einmal die Ausgabe
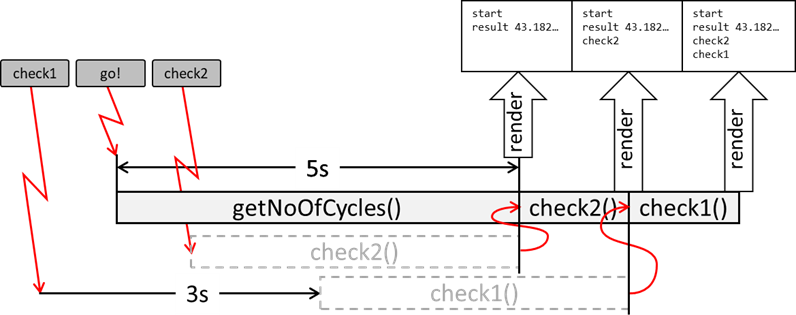
„start“! Auch der mehrmalige Klick auf die anderen beiden Buttons bewirkt nichts. 5 Sekunden nach unserem ersten Klick sehen wir aber folgendes:
Abb.: 28: Browserausgabe nach Interaktionstest
Sämtliche Ausgaben erfolgen auf einmal. Dies können wir nun nur teilweise mit dem Ablaufdiagramm aus
Abbildung 27 erklären. Wir klicken den
go! Button, wodurch die Funktion
startCode() in den Stack geladen wird. Diese wiederum lädt
logInfo() in den Stack. Wurde diese abgearbeitet verschwindet sie aus dem Stack und danach wird
getNoOfCycles() geladen und verarbeitet. Am Schluss wieder
logInfo():
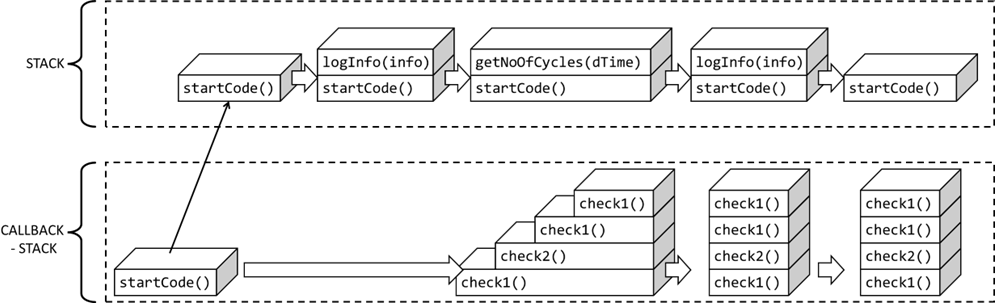
Abb.: 29: Zustand des Stacks während der Ausführung
Nachdem
startCode() dann komplett abgearbeitet wurde, ist der Stack wieder leer und der Zyklus kommt zur Fragestellung, ob gerendert werden muss. In der Zwischenzeit habe ich viermal auf die check Buttons geklickt und das
scheint sich der Browser gemerkt zu haben, da wir nach der Ausgabe
„result:…“ noch viermal eine
„check“ Meldung stehen haben. Dies passt aber jetzt nicht so richtig in unser Ablaufdiagramm. Wir müssen es also noch erweitern. Es kommt hier nun ein Konzept dazu, welches man unter „Callback Stack“ versteht.
Eine Callback Funktion ist eine Funktion, welche „von außen“ aufgerufen wird – die Frage ist nur: von wem? Hier müssen wir die Aussage, dass JavaScript erstmal „nur“ singlethreaded ist, etwas aufweichen. Es gibt
außerhalb des Abarbeitungs-Loops noch weitere Akteure in unserer JavaScript Welt. Im Browser ist das ein eigener Bereich, der streng genommen zum Browser und nicht zum JavaScript Interpreter gehört und lediglich
eine Schnittstelle (sogenannte API – Application Programming Interface) zu JavaScript bietet und welche mit JavaScript interagieren kann. Prinzipiell ist alles das, was zu einer Wartezeit führen
kann, wie bspw. die Kommunikation mit anderen Hardwareelementen, über diese Schnittstelle zugreifbar. Wenn wir uns an unseren Maler vom Anfang dieses Kapitels erinnern, dann musste er im synchronen Fall ja auf den
neuen gelben Farbeimer warten – die Lieferung war also ein Austausch mit Elementen außerhalb seines Wirkungsbereiches – bspw. ein Lieferdienst, der den Eimer an sein Atelier liefert. In JavaScript im Browser oder
auch node.js ist es ähnlich – ich bleibe aber hier mit den Erklärungen beim Browser, da man durch die kontrollierten Aktionen und dem Rendering das Verhalten besser verstehen kann. Dieser „externe“ Bereich ist nun
in der Lage, selbstständig in den Callback Stack Aufträge einzustellen. Wenn wir bspw. den Button
go! anklicken, rufen wir nicht direkt die Funktion
„startCode()“ auf, sondern eigentlich macht dies der Browser außerhalb unserer JavaScript Welt, indem er den Befehl
startCode() in den Callback Stack einstellt. Wenn nun mehrmals auf einen Button – in unserem Fall die check Buttons – geklickt wird, so schreibt der Browser diese Events in den Callback Stack hinein. Dort warten
sie, bis sie abgearbeitet werden können. Nachdem JavaScript aber singlethreaded ist, bleiben die Events hier erstmal unberührt, da er mit der
getNoOfCycles() Funktion beschäftigt ist. Unsere Stack Grafik muss also erweitert werden:
Abb.: 30: Funktionsstack und Callback Stack
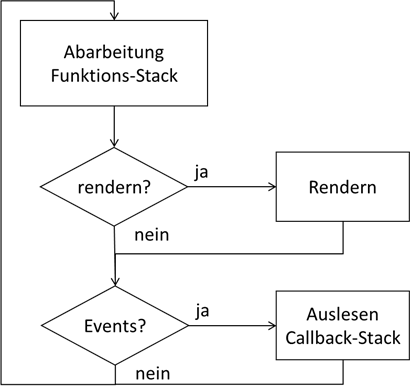
Der Ablauf der Verarbeitung benötigt nun auch diese erweiterte Logik:
Abb.: 31: Erweiterung um Eventverarbeitung
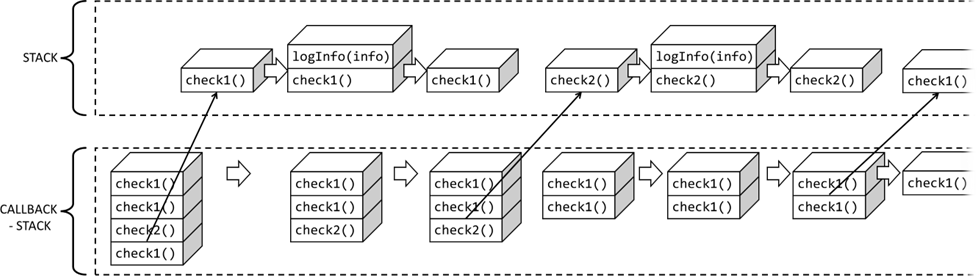
Dieses Auslesen des Callback-Stacks führt nun dazu, dass das zuletzt eingestellte Event aus dem Callback-Stack in den Funktions-Stack verschoben wird. Dadurch hat dieser wieder etwas zu tun und die Verarbeitung läuft weiter.
Abb.: 32: Abarbeitug des Callback-Stacks durch den Funktions-Stack
Die Events, welche in den Callback-Stack eingetragen werden, haben der Schleife auch den Namen gegeben , der sogenannte „Event Loop“. Der Callback-Stack ist ein sogenannter
FIFO (First In First Out) Stapel, bei dem die ältesten Events zuerst abgearbeitet werden. Wichtig ist nun in der hier verwendeten Art von Callback-Events, dass eben immer nur ein einziger Task von dem
Stapel pro Zyklus abgearbeitet wird. Solche Tasks werden Makrotasks genannt. Neben den Makrotasks gibt es noch sogenannte Mikrotasks, welche einen eigenen Stapel haben und immer komplett abgearbeitet werden – wenn also während der
Verarbeitung neue hinzukommen, werden diese ebenfalls vor einem neuen Zyklus abgearbeitet. Dieses Konzept ist für uns an dieser Stelle jedoch zweitrangig, insofern bleiben wir hier bei den Makrotasks. Nach der Verarbeitung im
Funktions-Stack erfolgt also immer ein Rendering. Das geht bei der Verarbeitung unserer vier Events jedoch so schnell, dass wir es optisch als eine Aktion wahrnehmen. Insgesamt haben wir nun also eine asynchrone Verarbeitung der
Buttonklicks vorliegen. Am besten können wir dieses asynchrone Verhalten nun sehen, wenn wir selbst in der Lage wären, Events in den Callback-Stack einzustellen. Und wie könnte es anders sein – natürlich ist das möglich. Hierzu
gibt es eine Funktion namens
setTimeout(), welche sich einen Funktionsaufruf merkt und ihn nach einer einstellbaren Zeit in den Callback-Stack stellt. Passen wir unsere
check1() Funktion nun etwas an:
Verzögerung des logInfo Aufrufs um 3 Sekunden
Kurze Erklärung der Codezeilen: Die
setTimeout() Funktion benötigt zwei zwingende und einen optionalen Parameter. Der erste Parameter ist der Name der Callback Funktion – in unserem Fall
logInfo – aber ohne die runden Klammern! Danach folgt die Zeit in Millisekunden, wie lange der Browser warten soll, bis er
logInfo() in den Callback-Stack ablegt – bzw. wann er ausgefüht werden soll. Der letzte Parameter ist der Wert, welcher in
logInfo() als Parameter abzulegen ist. Sollte die Callback Funktion keinen Parameter erwarten, so kann dies weggelassen werden. Wenn wir aber mehr als einen Wert zu übergeben habem, muss man das in einem
Array oder Objekt erledigen, da die Callback Funktion hier maximal nur einen Parameter erlaubt.
Laden wir unsere Seite nun neu und Klicken nun nur auf
check1, so erscheint nach 3 Sekunden der Logeintrag auf unserer Seite. Klicken wir nun auf
go!, danach auf
check1 und gleich danach auf
check2 sehen wir die Ausgabe:
Was auffällt ist, dass
check1 erst drei Sekunden nach
check2 auftaucht. Dies liegt daran, dass der Klick auf
check1 und
check2 erst nach Abarbeitung von
getNoOfCycles() an den Browser geschickt wird. Danach erst läuft der Timer von 3 Sekunden los.
Abb.: 33: Abarbeitung go!, check1, check2
Wenn wir die Klickfolge auf die Buttons in der Reihenfolge
check1,
go! und
check2 durchführen, so wird der Timer vor
getNoOfCycles() gestartet und nach deren Abarbeitung sehen wir sofort die gesamte oben gezeigte Ausgabe.
Abb.: 34: Abarbeitung check1, go!, check2
Die Frage ist nun, was uns diese Erkenntnis bringt. Nun, unsere
getNoOfCycles() Funktion soll uns ja über einen gewissen Zeitraum die Anzahl der Zyklen mitgeben, um eine Aussage über die durchschnittliche Zykluszeit zu geben. Wir haben nun die Möglichkeit,
diese Aktion in mehrere kleinere asynchrone Zeitabschnitte aufzuteilen, um zwischen diesen Zeitabschnitten dem Browser die Möglichkeit zu geben, das Rendern und andere wichtigen Aufgaben
durchzuführen. Ändern wir unseren Code also etwas ab:
Listing 36: Anpassung der Berechnung auf asynchrone Verarbeitung
Kurze Erklärung der Codezeilen: Da wir die Ermittlung der Durchschnittszeit nun in kleinere „Häppchen“ aufteilen, benötigen wir ein paar globale Kontrollvariablen.
noOfCycles wird zuerst global deklariert, damit der Zählwert über die Grenzen von
getNoOfCycles() hinaus besteht.
time ist die gesamte Zeit in Millisekunden – wieder 5000.
fractions hält die Anzahl der Unterteilungen unserer Zeitspanne – in unserem Fall 100. Dadurch haben wir eine Laufzeit von 50ms pro einzelnem
getNoOfCycles() Aufruf.
countDown zählt von
fractions (also 100) runter bis 0. Dann wissen wir, dass wir insgesamt die 5000 ms „Messzeit“ haben. Den Aufruf von
getNoOfCycles() ersetzen wir nun durch einen
setTimeout() Aufruf, der ohne Verzögerung
getNoOfCycles() aufrufen soll – allerdings aus dem Callback-Stack heraus. Dadurch können wir nach Verarbeitung von
startCode() ein Rendern erlauben. In der Funktion
getNoOfCycles() wiederum prüfen wir, ob wir bei
countDown bei 0 angekommen sind. Wenn ja, dann berechnen wir die Durchschnittszeit und wenn nein, rufen wir
getNoOfCycles() über
setTimeout() wieder auf. Dies ist also eine Art rekursiver Aufruf – eben nur über den Umweg von
setTimeout() um das Rendern zwischenzeitlich zu ermöglichen.
Wenn wir nun unseren Code starten sehen wir, dass alle Klicks sofort in einem Logeintrag sichtbar werden. Wir haben also unseren blockierenden, synchronen Code in einen nicht blockierenden,
asynchronen Code umgebaut, indem wir über
setTimeout() Callback Methoden verwendet haben. Dies ist in JavaScript deshalb möglich, weil wir hier Funktionen als Argumente verwenden können – so wie wir es in
setTimeout() gesehen haben. In komplizierteren Strukturen können diese Callbacks auch „nested“ vorgefunden werden – also ein Callback ruft wieder einen anderen Callback auf usw. Dieses Konzept wird
mitunter auch sehr unübersichtlich, weshalb man solchen Code scherzhaft auch als „callback hell“ bezeichnet. Im Zusammenhang von Callback Methoden taucht oft auch der Begriff der
„Promises“ auf – nicht zuletzt, weil es einen Ausweg aus der Callback Hölle bietet. Um das Promise Konzept zu verstehen ist es sinnvoll, eine Kommunikation mit einem Server aufzubauen. Wir
wollen eine einfache Anfrage an einen Server schicken, welcher wiederum eine Antwort zurückgibt. Hierzu verwenden wir eine Server API, welche keinerlei Registrierung etc. erwartet und
zwar die ip-api.com. Man schickt hier einfach eine Anfrage hin und erhält JSON Informationen über seinen Standort zurück. Das Problem bei solchen Anbietern ist, dass wir die serverseitige
Funktionalität nicht beeinflussen können – also bspw. ist es nicht möglich, einen serverseitigen Fehler zu provozieren. Insofern sehen wir uns erstmal eine echte Kommunikation mit
ip-api.com an und simulieren die gleiche Funktionalität anschließend mit einer Fake-Funktionalität, welche wir dann Schritt für Schritt in einen Promise verwandeln.
Für die „echte“ Kommunikation können wir aus JavaScript heraus mit einem
XMLHttpObject eine Nachricht senden und später wieder empfangen(2). Dies wird wiederum außerhalb der JavaScript Engine ausge-führt und meldet sich über einen Callback zurück. Hier der Code:
(2) Eigentlich führt man solche Anfragen in JavaScript mit „fetch()“ durch – für das Verständnis von inneren Abläu-fen ist der Weg über XMLHttpRequest an dieser Stelle aber erstmal sinnvoller.
Listing 37: Serveranfrage über JavaScript
Kurze Erklärung der Codezeilen: Das Objekt
XMLHttpRequest regelt die Kommunikation mit dem Server und hat diverse Möglichkeiten, Events in den Callback-Stack einzutragen. Hierbei nutzen wir
onreadystatechange(), was immer dann ein Event erzeugt, wenn im Status der http Kommunikation irgendeine Veränderung auftritt. Dort tragen wir unsere Callback Funktion ein, welche einfach prüft, ob die
Kommunikation abgeschlossen ist
(readyState == 4) und kein Fehler aufgetreten ist
(status == 200). Wenn dies der Fall ist, dann holen wir uns die gesendete Information aus
responseText, parsen den JSON String in eine JavaScript Objekt und extrahieren hier das Land, welches schließlich gelogged wird. Beim eigentlichen Sendevorgang
(open()) teilen wir dem
XMLHttpRequest Objekt die Adresse zur Web API mit uns sagen, dass wir eine http GET Anfrage stellen. Diese soll asynchron laufen, weshalb wir den letzten Parameter auf
true stellen. Ist das Objekt soweit vorbereitet, wird der Request gesendet.
Legen wir nun unseren Funktionsaufruf
getLocationInfo() auf unseren Button 1 (also
onclick="getLocationInfo()"), dann können wir die Anfrage stellen:
Abb.: 35: Rückgabe unserer XMLHttpRequest Anfrage
Soweit die „echte“ Kommunikation. Nun schreiben wir eine Simulationsfunktion, welche aus Sicht des Aufrufers das gleiche Ergebnis liefert. Später können wir sie beliebig auf unsere speziellen Situationen anpassen:
Listing 38: Simulation einer Serveranfrage
Kurze Erklärung der Codezeilen: Die Funktionalität simuliert also eine Anfrage, welche nach 100ms eine Funktion auslöst. In dieser Funktion wird einfach das Wort „Germany“ gelogged.
Wenn man sich Informationen über dieses Thema im Internet durchliest, findet man als Syntax für die dynamische Erstellung einer Funktion als Callback oftmals auch die Darstellung mittels Doppelpfeil, was im
Wesentlichen dem Lambda Ausdruck aus Java entspricht:
Listing 39: Simulation einer Serveranfrage mit verkürztem Syntax
Kurze Erklärung der Codezeilen: Man verzichtet lediglich auf den Begriff
function. Eventuelle Parameter werden entsprechend in den (in unserem Beispiel leeren) Klammernpaar eingetragen.
Nun kann man in JavaScript auch Funktionen als Parameter übergeben, was wir weiter Oben schon gesehen haben. Diese Möglichkeit können wir nun auch in unserem Code implementieren, wodurch die Idee der
„Callback“ Methode klarer wird. Gehen wir davon aus, dass die Kommunikation (also unsere Fake-Funktion) nicht von uns, sondern von jemand anderen geschrieben wurde – wir sie also eigentlich nicht „sehen“ können.
Wenn dem so wäre, dann ist es unmöglich, dass die Autoren dieser Funktionalität von meiner
logInfo() Funktion wissen konnten. Das Einzige, was sie wussten ist: jeder Nutzer muss über das Ergebnis der asynchronen Verarbeitung informiert werden. Sie wollen also wissen, mit welcher Funktion der Ausführer der
Kommunikations-Funktion „zurückgerufen“ werden soll, wenn sie fertig ist – eben was die Callback Funktion sein soll. Passen wir unseren Code also noch weiter an. Der folgende Code steht also nicht unter unserer
Kontrolle, da es von externen Personen geschrieben sein soll:
Listing 40: Simulation einer Serveranfrage mit Funktion als Parameter
Kurze Erklärung der Codezeilen: Wir haben in JavaScript die Möglichkeit, Funktionen als Parameter zu übergeben. Da die Autoren der
requestFakeInfo() Funktion die Information benötigen, wen sie bei Erfüllung der Anfrage informieren müssen, erwarten sie nun als Parameter hierfür eine Funktion – eben die Callback Funktion.
Meist wird die Variable, in welcher die Funktion übergeben wird auch
callback genannt. Beim
setTimeout() Aufruf wird nun diese
callback Methode mit dem Parameter „Germany“ aufgerufen. Die Idee ist also ählich eines Interfaces – man erwartet als Übergabeparameter eine Methode mit wiederum einem Parameter, weshalb man
callback("Germany") schreibt. Wenn wir nun diesen
requestFakeInfo() Service nutzen möchten, so ruft man ihn lediglich auf, trägt die Methode ein, welche für den Callback genutzt werden soll – also die
logInfo() Methode, welche ja genau einen Parameter erwartet.
Hinweis: Es wäre auch möglich gewesen, den setTimer() Aufruf ählich wie in Listing 35 zu verschlanken: setTimeout(callback, 100, "Germany"); Der im Listing 40 gezeigte Syntax ist jedoch flexibler.
Hinweis: Es wäre auch möglich gewesen, den setTimer() Aufruf ählich wie in Listing 35 zu verschlanken: setTimeout(callback, 100, "Germany"); Der im Listing 40 gezeigte Syntax ist jedoch flexibler.
Der Aufruf von diesem „externen Code“ wird nun von uns umgesetzt. Wir rufen also diese Funktion mit dem Parameter
„logInfo“ auf, wodurch in der „externen Funktion“ die Methode als callback verarbeitet wird, die wir hier als Parameter übergeben:
Listing 41: Simulation einer Serveranfrage mit Funktion als Parameter
Wenn wir den Button betätigen sehen wir, dass die Anfrage normal verarbeitet wird. Der Vorteil dieses Vorgehens sehen wir, wenn wir den Aufruf wie folgt ändern:
Listing 42: Änderung der Callback Funktion
Kurze Erklärung der Codezeilen: Anstatt das Ergebnis nun zu loggen, lassen wir eine Popup Message anzeigen. Dies wird mit der Funktion
alert() erledigt. Also tauschen wir lediglich den Funktionsparameter von
logInfo zu
alert aus und das Ergebnis wird per Popup angezeigt, ohne dass wir in
requestFakeInfo() etwas ändern müssen.
Jetzt, da wir eine Vorstellung von Callbacks haben, werden wir unsere
requestFakeInfo() Funktion etwas erweitern. Gehen wir davon aus, dass unser Fake-Server etwas unzuverlässig ist, und im Schnitt jede zweite Anfrage mit einem Fehler quittiert.
In unserem Fall übernimmt das einfach ein Zufallsgenerator. Nun möchten wir, dass im Erfolgsfall das Programm so funktioniert wie vorher und im Fehlerfall einfach eine andere Funktion aufgerufen wird:
Listing 43: Callback für Erfolgs- und Fehlerfall
Kurze Erklärung der Codezeilen: Unser
requestFakeInfo() erwartet nun zwei Funktionen: eine für den Erfolgsfall – also wenn die Anfrage erfüllt wurde
(resolve), und eine für den Fehlerfall – also wenn sie abgewiesen wurde
(reject).
Listing 44: Asynchroner Aufruf mit Promise
Kurze Erklärung der Codezeilen: Die Funktion
requestFakeInfo() hat nun keine Parameter mehr und gibt lediglich einen
Promise zurück. Man hätte also auch auf die Funktion verzichten können und anstatt dem Aufruf selbst den
Promise erzeugen können (alos anstatt Aufruf
requestFakeInfo()… in
getFakeInfo() als
let myP = new Promise((resolve… ). Der
Promise Konstruktor erwartet nun zwingend eine Funktion mit zwei Parameter,
resolve und
reject. Hier hiterlegen wir wiederum eine Funktion (in unserem Fall über den Pfeiloperator), welche identisch mit unserer „alten“
requestFakeInfo() Funktion ist. Wir haben Sie somit in einen
Promise eigebettet. Entscheidend für uns ist nun die Nutzung, da
requestFakeInfo() ja außerhalb unseres Codes bereits für uns vorbereitet sein soll. Wir rufen die Funktion – diesmal ohne Parameter – auf und ergänzen nun mit Hilfe des Punktoperators ein
then, gefolgt von der
resolve Funktion – in unserem Fall
logInfo. Die Reject Funktion folgt im
catch(), was nun kein
try/catch Block ist, sondern lediglich eine Syntaxparallele hierzu ist um klar zu machen, dass der
reject Zweig ein Errorhandling darstellt.
Wenn man sich tiefer mit der Thematik beschäftigt, wird man früher oder später auf mehrfach hintereinander liegenden Promise Ketten stoßen, welche mit einfachen Callbacks unübersichtlicher als mit
Promises zu lösen sind. Weiter möchte ich an dieser Stelle jedoch nicht gehen, da aus meiner Sicht die wichtigsten Konzepte nun soweit verstanden wurden, dass man bei Bedarf hier gut anknüpfen kann.
Unser eigentliches Thema in diesem Kapitel ist ja, das Thema Multithreading zu realisieren. Bis jetzt haben wir uns im Rahmen von JavaScript aber lediglich um asynchrone Verarbeitung gekümmert, welche auf ein und
demselben Thread läuft. Aus Sicht der meisten JavaScript Programme ist das zwar der hauptsächliche Usecase, unserem Ziel, die einen parallelen Thread zu nutzen sind wir aber trotzdem noch nicht näher gekommen.
Also, Zeit sich um die Threads zu kümmern. Hier müssen wir nun wieder wissen, ob wir browserseitiges oder serverseitiges JavaScript schreiben wollen. Auf dem Browser heißen die Threads „Web Worker“ und in node.js
„Worker Threads“. Die grundsätzliche Idee ist bei beiden jedoch die gleiche. Beim Start eines „Workers“ wird im Wesentlichen eine komplett neue Instanz eines Interpreters gestartet, weshalb wir hier das erste Mal
in JavaScript gezwungen werden, Funktionalitäten in ein eigenes File zu hinterlegen. Also – legen wir los. Da wir gerade ohnehin auf dem Browser arbeiten, können wir hier auch gleich unsere Fraktale anzeigen lassen,
wofür wir die Option „Web Worker“ umsetzen müssen. Zur besseren Vergleichbarkeit – vor allem auch bezüglich der Interaktionsmöglichkeit während der Fraktalberech-nung – realisieren wir hier sowohl die single- als
auch die multithreaded Variante. Für die Anzeige im Browser benötigen wir eine HTML-Element, welches Pixeldaten anzeigen kann – das
canvas Element. Wir bauen unsere Webseite also etwas um, so dass wir gleich die Ergebnisse unserer Grafikberechnung anzeigen können:
Listing 45: HTML Seite für Anzeige von Fraktalgrafiken
Kurze Erklärung der Codezeilen: Der Skriptbereich wurde um eine Referenz auf ein externen Skript
fractalThread.js ergänzt. Hier werden wir später den threaded Code eintragen. Er muss in einem eigenen File sein, da er ja in einer eigenen Instanz laufen wird. Den zweiten Skriptbereich zwischen den beiden
<script$gt; Tags werden wir gleich näher ansehen. Weiterhin sind drei Buttons vorgesehen. Einer für die Berechnung im Main-Thread, einen für die Berechnung in einem oder mehreren Web Worker und der dritte soll
lediglich die Interaktionsfähigkeit der Webseite testen. Weiterhin haben wir den
canvas, welcher die gleiche Pixelgröße aufweist, wie unsere Files aus den vorausgegangenen Beispielen. Die Seite ruft beim Neuladen die Funktion
prepareCanvas() auf, wo alle notwendigen Vorbereitungen zur
canvas Nutzung getroffen werden.
Kümmern wir uns also um den canvas. Hierzu gehen wir folgenden Code durch:
Listing 46: Vorbereitung des canvas zum Aufnehmen von Pixeldaten
Kurze Erklärung der Codezeilen: Der
canvas ist dazu gedacht, Grafikelemente wie Kreise, Linien aber auch ganze Grafiken oder einzelne Pixel anzuzeigen. Damit dies möglich ist, müssen wir eine Referenz auf genau die Schnittstelle erhalten, welche
diese Zeichnungsfunktionalitäten anbietet – den „Kontext“. Danach erstellen wir ein Objekt
„subGraph“, welches in der Lage ist Pixeldaten zu platzieren. Wir werden diese Daten Zeilenweise in unsere Grafik eintragen, weshalb die Breite auf
dimX (das Objekt hierzu werden wir gleich besprechen) und Höhe gleich 1 gehen – also die gesamte Breite x 1 Zeile. Dadurch wird intern ein Array aufgebaut, welches für die angegebene Dimmension Pixeldaten aufnehmen kann.
Diese Objekte benötigen wir pro HTML
canvas genau einmal, weshalb wir sie als gobale Variablen außerhalb von Funktionen deklarieren. Weiterhin lassen wir noch einen Counter mitlaufen, welcher den aktuellen „Zoombereich“ indizieren soll, so dass wir
wieder in unser Fraktal „hineinzoomen“ können.
Als nächstes müssen wir uns um die zentralen (sprich globalen) Elemente kümmern:
Listing 47: Vorbereitung des canvas zum Aufnehmen von Pixeldaten
Kurze Erklärung der Codezeilen: Die Breite und Höhe, sowie die Anzahl der Threads halte ich zur besseren Übersicht global.
pixelDist und
maxIteration müssen ebenfalls zentral gehalten werden, da wir sie nach jedem vollständigen Rechenzyklus für die Zoomanpassung neu belegen müssen. Die Worker-Threads werden in einem Array vorgehalten,
damit wir später die einzelnen Arbeitspakete einfach zuordnen können. Für die Erzeugung eines Worker-Threads geben wir das js-File an, welches im Rahmen des Threads laufen soll (also
fractalThread.js. Danach fügen wir einen Event-Listener hinzu, der die Methode
drawImage() aufrufen soll. Wenn wir also ein Event an den Thread über
postMessage() senden, wird
drawImage() mit der geposteten Nachricht aufgerufen – was bei uns ein JSON-String mit den Grafikinformationen sein wir.
Wie weiter oben schon erwähnt, wird der Datenaustausch zwischen unserem Main-Thread und dem Worker etwas umständlicher werden, da wir keinen gemeinsamen Datenbereich im Speicher haben – es handelt sich ja um unabhängige
Instanzen des JavaScript Interpreters. Es gibt zwar die Möglichkeit, über einen
SharedArrayBuffer(3) diesen Graben zu überwinden, wobei dies den Rahmen dieses Buches sprengen würde. Wer tatsächlich dieses Konstrukt verwenden möchte oder muss, sollte sich vorab entsprechend
tiefer einlesen. Wir werden den Datenaustausch zwischen unseren beiden Threads einfach mit Messages erledigen, welche wiederum „nur“ Strings austauschen. Da wir aber schon mit JSON vertraut sind, können wir unseren
Datenaustausch durch JavaScript Objekte vorbereiten, welche anschließend in JSON-Strings umgewandelt und versendet werden können. Im Wesentlichen wird unser Konstrukt wie folgt aussehen:
(3)https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/SharedArrayBuffer
Abb.: 36: Datenaustausch zwischen Threads
Die Grafikdaten beinhalten alle Notwendigen Informationen, um die Pixel im
canvas zeichnen zu können – allen voran unser altbekanntes zweidimensionales Array der Farbwerte. Die Konfigurationsinformationen wiederum erstellen wir als JavaScript Objekt, welches alle wichtigen Eckdaten unserer Berechnung
enthält. Es wird direkt in den Skriptbereich der HTML-Seite eingetragen. Die Werte sind ebenso wieder „alte Bekannte“ aus den vorausgegangenen Fraktalberechnungen.
Listing 48: Konfigurationsobjekt für Fraktalberechnungen
Kurze Erklärung der Codezeilen: Lediglich
sendMessage ist neu. Hier wollen wir einstellen, ob die spätere Berechnungsfunktion das Ergebnis über eine Message im multithreaded Fall, oder über ein
return im singlethreaded Fall zurückgeben soll. Das eigentliche Konfigurationsobjekt wird für jeden Thrad einzeln erzeugt und zugewiesen. Alle festen Werte versehen wir mit Konstanten, der Rest wird über die Parameterliste übergeben.
Bevor wir uns nun um die eigentliche Berechnung kümmern, sehen wir uns noch die restlichen Funktionen im HTML-Skriptbereich an.
Listing 49: Vorbereitung der Fraktalberechnung – zeichnen der einzelnen Pixel
Kurze Erklärung der Codezeilen:Die Funktion
drawImage() ist für das Platzieren der einzelnen Teilbilder im
canvas zuständig. Hierzu erhält es die Pixeldaten – wegen der späteren Nutzung aus einem Thread heraus als JSON String. Hätten wir diese Anforderung nicht, könnten wir gleich das Array mit den Pixeldaten übergeben.
Da wir bei der threaded Lösung unterschiedliche Bildbereiche unabhängig voneinander berechnen, müssen hier noch zusätzliche Informationen platziert werden, wie bspw. von welcher bis welcher Zeile die Daten auszulesen
sind. Als erstes müssen wir nun den JSON String in eine JavaScript Objekt mittels
parse() umwandeln. Danach holen wir uns das
pixel Array und übertragen es in das Array des
subGraph Objektes, welches die Pixeldaten pro Zeile aufnehmen soll. Dieses Array erwartet pro Pixel vier Bytes, jeweils für die Rot-, Grün- und Blauwerte und dem Alfawert, welchen wir immer auf
0xff setzen. Wenn nun die Zeile belegt wurde, platzieren wir es auf die entsprechende Zeile y und der X-Position 0. Da der
canvas anders aufgebaut wird als unsere Files aus den vorausgegangenen Fraktalprogrammen, müssen wir unseren Zeilenaufbau invertieren – der Zeilenzähler zählt also rückwärts. Danach passen wir
wie in den anderen Fraktalprogrammen auch die Parameter für den Zoom an und geben die neue Zählerinformation im Logbereich mit einem Zeilenumbruch aus. Auch hier müssen wir wieder mit merheren
parallelen Threads planen – also dürfen wir das Hochzählen erst durchführen, wenn die letzte Pixelzeile platziert wurde, was wir über den Vergleich von
rTo mit
dimY erreichen. Als Hilfsmethoden loggen wir wieder in den HTML
div – diesmal ohne Zeilenumbruch direkt in der Ausgabe (den Zeilenumbruch müssen wir also in den
info Parameter bereits einfügen).
Der Algorithmus wird über
startFractal() bzw.
startFractalThread() aufgerufen.
Listing 50: Starten der Fraktalberechnung
Kurze Erklärung der Codezeilen: Der Algorithmus wird über
startFractal() bzw.
startFractalThread() angestoßen. Im nicht treaded Fall rufen wir die
calcPixel() Funktion auf, welche die Berechnung durchführt, die wir gleich im Anschluss besprechen. Wichtig ist auch hier, dass die Parameter ausschließlich über JSON Strings übergeben werden,
damit wir die Funktionalität auch im multithreaded Ansatz wiederverwenden können. Dies erfolgt über
startFractalThread(). Hier teilen wir wie in den anderen multithreaded Ansätzen auch die zu berechnenden Zeilen in möglichst gleichgroße Bereiche auf und übertragen jedem Thread den
jeweiligen Teilbereich zur Berechnung. Der Unterschied zum nicht treaded Ansatz ist, dass wir die Informationen nun über
postMessage() an den Thread übertragen müssen (weshalb wir das Konfigurationsobjekt ja als JSON vorliegen haben müssen). Der Eventlistener, welcher den
postMessage() Call verarbeiten soll, wird dann in
fractalThread.js registriert.
Soweit haben wir nun den Rahmen vorbereitet. Der folgende Code muss nun in einem eigenen JavaScript File ausgelagert werden, damit der Thread später in der Lage ist, diesen Code unabhängig von
der HTML-Seite zu laden. Dieses File habe ich
fractalThread.js getauft, welches in der HTML-Seite ja bereits über
<script src="fractalThread.js"> referenziert wird. Hier lagere ich nun alle für die Fraktalberechnung relevanten Funktionalitäten aus:
Listing 51: Threadable Code für die Fraktalberechnung
Kurze Erklärung der Codezeilen: Den Code für die komplexen Zahlen habe ich lediglich der Vollständigkeit halber hinzugefügt – die Logik ist exakt wie in den vorausgegangenen Codes. Gleiches gilt für
die Pixelberechnung. Hier müssen wir lediglich die Konfigurationsinformationen aus dem JSON String wieder mit
parse() extrahieren und die Kalkulation wie in Java oder C# durchführen. Die Konfigurationsdaten entnehmen wir aus dem
config Objekt. Am Schluss der Berechnung müssen wir prüfen, ob wir gerade singlethreaded arbeiten – sprich über return die Ergebnisdaten senden, oder multithreaded. In diesem Fall senden wir mit
postMessage() die Grafik-Rechenergebnisse an den registrierten Eventlistener von Oben, welcher
drawImage() aufruft. Am Schluss müssen wir uns nun noch darum kümmern, dass der Thread über einen
postMessage() Call aufgerufen werden kann – was wir über einen eigenen Eventlistener realisieren. Dieser besagt, dass bei einem
postMessage() Call die Funktion
calcPixel() aufgerufen wird, was wir ja in der Funktion
startFractalThread() anstoßen.
Nun können wir die Seite neu laden und auf den
no Thread Button klicken. Nach kurzer Zeit sehen wir das Fraktal auf der HTML Seite.
Abb.: 37: Fraktal auf der HTML Seite
Drücken wir nochmal auf den Button, zoomen wir in das Fraktal hinein. Da die Iterationszahl mit jedem Klick um 50 Zyklen erhöht wird, dauert die Berechnung nach jedem Klick länger. Klicken wir auf den
check Button, so sehen wir im Logbereich pro Klick einen Punkt. Wird gerade nicht ein neues Fraktal gerechnet, erscheinen die Punkte sofort nach dem Klick. Rechnet JavaScript jedoch ein Fraktal aus,
erscheinen sie erst nach dessen Fertigstellung. Wir arbeiten also auf einem Thread.
Versuchen wir nun auf den
Thread Button zu klicken, erhalten wir eine Fehlermeldung – bzw. reagiert die Seite nicht. Hier müssen wir vorab noch ein „Sicherheitsfeature“ umgehen. Bei einem lokalen Test der Threadfunktionalität unterdrücken die
Sicherheitseinstellungen der Browser die Erzeugung von Threads auf Basis eines lokalen Files – in unserem Fall
fractalThread.js. Bei den Browsern Edge und Chrome kann man dieses Feature relativ einfach temporär „ausschalten“. Hierbei müssen alle Instanzen von Chrome bzw. Edge gestoppt werden. Achtung – bei Edge verstecken
sich diese Instanzen mitunter und man muss sie manuell über den Taskmanager beenden, oder den Rechner einfach komplett neu starten, damit keine „alten“ Instanzen dieses Programms laufen. Danach öffnet man eine Kommandozeile,
wechselt in den Pfad, in dem Chrome bzw. Edge installiert sind (also das
.exe File sich befindet(4)) und startet den Browser mit einem Flag. Für Chrome:
(4) Bei meinem Rechner befindet sich bspw. chrome.exe unter C:\Program Files\Google\Chrome\Application
und für Edge:
Bei Firefox müsste man einen Eintrag in den Securitysettings verändern. Hierauf verzichten wir an dieser Stelle da wir in Gefahr laufen, es später vergessen wieder herauszunehmen. Würden wir die
Seiten über einen Webserver bereitstellen, wird diese Einstellung nicht benötigt, da ja das File nun nicht mehr lokal existiert, sondern über den Webserver geladen wurde.
Starten wir nun unser Skript nun mit dem
Thread Button, so sehen wir nach kurzer Zeit wieder unser altbekanntes Fraktal. Klicken wir nochmals darauf und betätigen während der Rechnung den
check Button, so sehen wir die Punkte im Logbereich sofort nach jedem Klick. Wir arbeiten also in verschiedenen Threads. Drehen wir die Threadzahl hoch, so sehen wir auch eine merkliche Performancesteigerung unserer Fraktalberechnung.
Python
Gehen wir nun auf die letzte in diesem Kapitel behandelte Sprache ein – Python. Hier „hört“ man oft, dass Python singlethreaded sein soll, was jedoch bei genauerem Hinsehen falsch ist. Python bietet wie andere
Sprachen auch die Erstellung von einzelnen Threads an, welche dann tatsächlich als eigene Threads im Betriebssystem wiederzufinden sind. Allerdings laufen diese immer auf einem Core bzw. es existiert ein Mechanismus
in Python welcher sicherstellt, dass zu einem Zeitpunkt immer nur ein Thread läuft – der Global Interpreter Lock, kurz GIL. Diese Funktionalität hat man kurzerhand eingebaut, da die im Hintergrund
laufenden C-Programme nicht thread-safe sind, was für eine Programmiersprache natürlich nicht tragbar ist. Der GIL kümmert sich nun darum, dass über einen „scheduling“ Algorithmus (also eine Art Ablaufplanung) die
entsprechenden Threads alle verarbeitet werden – allerdings nicht parallel, sondern abwechselnd. Somit ist sichergestellt, dass bei verschiedenen Threads der dahinterliegende Speicher nicht gleichzeitig genutzt wird.
Die Frage ist nun, warum man dann überhaupt Threads erstellen kann. Dies liegt daran, dass Python nicht wie JavaScript die Anfragen an externe Systeme (welche ja Wartezeiten verursachen können) außerhalb des Interpreters
ausführt und mit Hilfe des Event Loops die Rückmeldungen verarbeitet. Python verarbeitet die Anfragen innerhalb des Interpreters. Wenn nun bspw. eine http Anfrage Wartezeiten verursacht, dann legt man sie in einen
eigenen Thread, wodurch das „Warten“ nicht die Verarbeitung des Main-Threads blockiert. Threads eigenen sich in Python also für die Reduktion von Wartezeiten, nicht aber zur parallelen Verarbeitung von CPU-intensiven Berechnungen.
Wir werden uns im Anschluss an die Thread-Beispiele noch die Optionen für die parallele Verarbeitung ansehen, dem sogenannten „Multiprocessing“. Beginnen wir aber mit den Threads. Hierzu bauen wir uns zuerst mal eine
Funktion, welche einfach nur eine vorgegebene Zeit wartet und starten diese.
Listing 52: Synchrone Verarbeitung einer Wartefunktion
Kurze Erklärung der Codezeilen: Die
doWait() Funktion gibt vor und nach dem Warten lediglich eine kurze Info aus. Die Wartezeit wird über einen Parameter übergeben. Den Aufruf habe ich ebenfalls in eine eigene Funktion gepackt.
Dort wird die Wartezeit definiert und vor und nach dem
doWait() Aufruf ebenfalls eine Ausgabe gelogged. Zum Schluss wird der Prozess über
startWaitCheck() einfach gestartet.
Starten wir das Programm, sehen wir die synchrone Verarbeitungsstruktur:
Nun ändern wir den Aufruf dergestalt, dass wir die Wartefunktion in einem Thread auslagern:
Listing 53: Threaded Verarbeitung einer Wartefunktion
Kurze Erklärung der Codezeilen: Zuerst müssen wir die
Thread Klasse zugänglich machen. Wenn wir es instanziieren, benötigt der
Thread eine Angabe, welche Funktion bei Start aufzurufen ist. Weiterhin können (optionale) Argumente übergeben werden. In den Klammern nach
args= wird eine Liste erwartet – wenn wir nur ein Argument haben, dann muss trotzdem ein Komma eingefügt werden, da es sonst nicht als Liste erkannt wird. Danach wird der
Thread gestartet. Ganz am Ende muss ähnlich wie in C++ ein
join erfolgen, damit der Interpreter den Main-Thread nicht vor dem Arbeitsthread beendet.
Starten wir den Code, ergibt sich eine neue Ausgabe:
Die Zeilenumbrüche kommen etwas durcheinander, was jedoch erstmal nur Kosmetik ist. Wichtig ist, dass wir zuerst
start sehen, dann
before wait und dann gleich
end. Das
sleep() blockiert also nicht den Main-Thread. Nach der Wartezeit wird nun
after wait ausgegeben. Nun wollen wir mal prüfen, ob mehrere Threads nun tatsächlich nur abwechselnd und nicht parallel laufen. Hierzu bauen wir uns wieder ein Programm mit einer Schleife –
diesmal lassen wir aber anstatt eines
sleep() Befehls einfach etwas „kompliziertes“ Rechnen – und zwar die Wurzel aus einem Zähler:
Listing 54: Test auf Parallelität von Threads in Python
Kurze Erklärung der Codezeilen: Die Funktion
calcRoots() berechnet für alle Zahlen zwischen 0 und kleiner
noOfItr die Quadratwurzel. Die Funktion
startLoadTestMT() wiederum startet den Prozess über Threads. Hierfür wird eine List von Threads erzeugt, in dem jeweils ein Aufruf von
calcRoots() hinterlegt wird. Mit der Variable
noOfThreads steuern wir, wie viele Threads die Berechnung gleichzeitig durchführen soll. Die Laufzeit des Gesamtprogramms wird wieder über
time() ermittelt.
Lassen wir den Code laufen, kommen wir bei einem Thread auf ca. 1 Sekunde Laufzeit. Stellen wir die Threadanzahl auf 8, so erhalten wir ca. 8 Sekunden Laufzeit – es gab somit keine Parallelisierung.
Jeder Thread teilt sich also die Rechenzeit mit allen anderen Threads, da die Rechenzeit für die Wurzelberechung pro Thread sich ja nicht geändert hat. Ändern wir unseren Code nun auf parallele
Verarbeitung. Wie weiter oben schon erwähnt wurde, wird dies in Python mit „Multiprocessing“ erledigt. Die Syntaxstruktur von Multiprocessing ist in Python ähnlich wie in Multithreading, weshalb wir unseren Code lediglich
minimal umbauen müssen:
Listing 55: Test auf Parallelität von Prozessen in Python
Kurze Erklärung der Codezeilen: Für das Multiprozessing muss die entsprechende Klasse importiert werden. Die Struktur von
startLoadTestMP() ist exakt die gleiche wie
startLoadTestMT(), wir verwenden lediglich den
Process() Konstruktor. Für den Aufruf müssen wir jedoch noch einen Sicherungsmechanismus einbauen. Da jeder Prozess in einer eigenen Python Umgebung läuft und somit das gesamte Python
File verarbeitet wird, darf der initiale Aufruf von
startLoadTestMP() nur vom Main Prozess durchgeführt werden, weshalb wir die entsprechende Abfrage vor dem
startLoadTestMP() Aufruf einbauen müssen. Lassen wir die Prüfung weg, so würde jeder
Thread wieder
startLoadTestMP() aufrufen, hier wieder Threads erzeugen und so weiter.
Lassen wir das Programm nun laufen, sehen wir eine mittlere Verarbeitungszeit pro Thread von ca. 3 Sekunden. Das ist zwar nicht so schnell wie in nur einem Prozess, da der Overhead gerade bei Multiprocessing
sehr stark zu Buche schlägt. Aber wir sehen bei der Reduktion im Vergleich zu 8 Threads eindeutig, dass wir hier parallel arbeiten. Zum Schluss wollen wir uns noch eine Syntaxvariante in Python ansehen, in der
wir den threaded Code in eine eigene Klasse auslagern, wodurch wir noch einfacher den Wechsel zwischen Multithreading und Multiprocessing realisieren können. Hierbei erweitern wir einfach die Klasse
Thread um unsere Funktionalität und bauen zusätzlich gleich noch eine Zeitmessung pro Thread ein:
Listing 56: Erweiterung der Thread Klasse
Kurze Erklärung der Codezeilen: Unsere
CalcRoots Klasse erweitert nun die
Threads Klasse. Hierbei müssen wir den Konstruktor der Superklasse aufrufen. Danach übernehmen wir die id und die Anzahl der Iterationen in die Instanzvariablen. Die
run() Methode ist nun ähnlich wie in Java die Methode, welche durch
.start() aufgerufen wird. Hier haben wir nun keine weiteren Parameter, da wir sie über die Instanzvariablen abgreifen können. Die
duration wird ebenfalls als Instanzvariable abgelegt, damit wir eventuell später nochmal darauf zugreifen können. Dies wird noch wichtig für den Vergleich mit
Processes sein.
Nun können wir unsere Startfunktion relativ simpel auf unsere neuen
CalcRoots Klasse anpassen, da sie durch die Erweiterung von
Threads einfach eingesetzt werden kann:
Listing 56: Start einer threadfähigen Klasse
Kurze Erklärung der Codezeilen: Im Wesentlichen wurde lediglich
Thread (bzw.
Process) durch
CalcRoots ersetzt. Lediglich am Ende, nachdem die Prozesse über
join() wieder zusammengeführt werden, geben wir noch zur Kontrolle die Laufzeit basierend auf der Instanzvariable
duration aus.
Die Ergebnisse sind wieder wie im Threading Beispiel oben bei ca. 8 Sekunden. Die Werte der Instanzvariable
duration geben exakt die gleichen Werte wieder, wie die Ausgabe innerhalb des Threads. Nun ändern wir in unserer
CalcRoots Klasse die Elternklasse und den Superkonstruktoraufruf von
Threads auf
Processes und starten das Programm nochmal. Die Ausgaben innerhalb der Klasse
CalcRoots sind wieder wie im prozeduralen Ansatz. Was jedoch auffällt ist, dass der Inhalt der Instanzvariable
duration immer 0 ist. Dies liegt daran, dass die Prozesse im Gegensatz zu den Threads einen eigenen Speicherbereich haben. Somit kann der Main-Thread nicht auf die Werte der Objekte
innerhalb des Prozesses zugreifen. Genau hier sieht man die eigentliche Problematik von der Verteilung auf mehrere Kerne. Python bietet hier mehrere Lösungen an, ich werde hier jedoch
nur auf die einfachste, das Messaging über eine
Queue eingehen.
Die
Queue ist eine threadsichere Möglichkeit, Nachrichten über Processes hinaus auszutauschen. Bauen wir unseren Code also entsprechend um:
Listing 58: Kommunikation zwischen Prozessen mittels Queue
Kurze Erklärung der Codezeilen: Die Klasse
Queue ist ebenfalls im Modul
multiprocessing zu finden. Das
Queue Objekt wird nun im Main Thread erzeugt und als Parameter an das
Process Objekt (bzw.
CalcRoots) übergeben. Dort wird in die
Queue ein Array mit der Prozess id und dem
duration Wert eingetragen. Im Main Thread kann nun über
get() die
Queue wieder ausgelesen werden. Dies sollte im Idealfall vor dem joinen der Prozesse erfolgen, weshalb wir hier auf eine etwas umständlichere Art solange versuchen die
Queue zu leeren, bis alle Prozesse beendet wurden (also alle
is_alive() auf False liegen).
Lassen wir den Code wieder laufen, sehen wir, dass die
duration Werte auch im Main Thread zur Verfügung stehen. Ich verzichte an dieser Stelle, die Fraktalberechnung in Python zu erklären, da man in der Praxis in Python nicht den direkten Weg via Python-Code gehen würde,
sondern externe Bibliotheken Zu Hilfe nehmen würde, wie bspw.
numpy. Trotzdem sollten dich wichtigsten Elemente von Python hier klar geworden sein. Wer der Vollständigkeit halber trotzdem eine Python-Lösung (ohne Bibliotheken) sehen möchte, findet eine Lösung in
https://github.com/maikaicher/book1 unter
Kap18/Python/Fractal. Führt man dieses Beispiel aus wird wiederum klar, warum man in Python auf angepasste Bibliotheken zurückgreifen sollte, da die Performance der „reinen“ Python Implementierung sehr zu Wünschen übrig lässt.
Abschließend zu dem Kapitel können wir also feststellen, dass die Skriptsprachen beim Thema Multithreading sehr viel umständlicher zu handhaben sind als die kompilierten Sprachen. Parallelisierung ist ein reines
Performance Thema – der Fokus der Skriptsprachen ist aber die Einfachheit bei der Nutzung. Die verstärkte Unterstützung von paralleler Verarbeitung kommt vermutlich von der stetig steigenden Akzeptanz dieser Sprachen für
größere Projekte. Trotzdem kann man jedoch sagen, dass man sich bei Skripten sehr genau überlegen muss, ob man den (steinigen) Weg von paralleler Verarbeitung geht oder nicht.
CC Lizenz (BY NC SA)