
Strukturen in Files
Die Grundlagen für den allgemeinen Umgang mit Files haben wir nun verstanden. Nun gibt es aber auch spezielle Filetypen, welche uns Programmierern immer wieder über den Weg laufen und mit denen wir auch
umgehen können müssen. Im Großen und Ganzen handelt es sich hierbei um Dateien, welche strukturierte Daten beinhalten. Die wohl wichtigsten Formen von strukturierter Datenablage sind:
- CSV
- JSON
- XML

Strukturieren von Daten
Aber gehen wir erstmal auf das grundsätzliche Problem der Datenstrukturierung ein. Wenn wir Informationen auf der Festplatte ablegen wollen, so müssen wir es in einer Art und Weise machen,
dass wir die Daten wieder sinnvoll aus dem File herausextrahieren können. Diesen Vorgang nennen wir Parsen, genauso wie die Erzeugung einer Zahl aus einem String (Siehe
Kapitel 7). Nun können wir eigentlich beliebige Formate – also Strukturen, wie wir Daten in einem File organisieren – selbst erfinden. Wir könnten beispielsweise eine Adressdatei für ein
Adressbuch wie folgt strukturieren:
Wir könnten nun ein Programm schreiben, welches die relevanten Daten aus diesem File extrahiert und zwei Personenobjekten zuordnet. Als Orientierung könnten wir den Text zwischen
Vorname: und
Nachname: als Vorname identifizieren, zwischen
Nachname: und
Straße: den Nachnamen entnehmen usw. Dies ist deshalb theoretisch möglich, weil vermutlich alle Daten (also Vornamen, Nachnamen, Straßen etc.) keine Überschneidung mit unseren Orientierungsstrings wie
“Vorname:„ haben werden – sprich es wird wohl keine Person geben, die „Vorname:“ heißt. Das Ganze ist zwar nicht sonderlich elegant – würde aber funktionieren.
Das Problem ist, dass dieses Programm zur Extraktion der Daten von uns komplett selbst entwickelt werden muss und wir diesen Code jedem zur Verfügung stellen müssen, der mit diesen Files ebenfalls was
anfangen will. Vor allem beim Versenden von Daten könnte sich dies als problematisch erweisen. Sehr viel besser wäre es, wenn wir uns auf ein Fileformat verständigen würden, das allgemein akzeptiert ist.
Und hier kommen unsere drei Kandidaten ins Spiel.
CSV-Format
Ein CSV (Comma Separated Values) File ist hier mit Sicherheit die simpelste Variante, weshalb ich hier auch keine fertige Bibliothek verwenden muss, sondern alles relativ einfach
selbst schreiben kann. Bevor wir den Code realisieren, sehen wir uns eine mögliche Filestruktur für unsere Adressdaten an:
Die Struktur ist denkbar einfach. Jede Zeile beinhaltet mehrere Werte, welche durch ein Semikolon getrennt wird. Komma wird vor allem im englischsprachigen Bereich eher genutzt, da der Dezimaltrenner
hier im Regelfall der Punkt ist und somit keine „Konflikte“ zwischen den Orientierungszeichen und den eigentlichen Daten zu erwarten sind. Bei uns ist es das Komma, was somit eine saubere Zuordnung
erschwert und wir auf das Semikolon ausweichen. Prinzipiell kann jedes beliebige Zeichen für die Spaltentrennung verwendet werden. Ein „gutes“ Zeichen für die Separierung der Daten ist immer eines,
welches in den Daten nicht vorkommt. Insofern sieht man oft auch den Tabulator oder das Pipe Symbol „|“. Nun sehen wir uns mal einen einfachen CSV Leser in C# an. Dieser soll die erste Zeile als
Überschriftenzeile interpretieren und die Daten je Spalte mit Spaltennamen formatiert ausgeben. Vor jedem Wert soll der Werttyp stehen, also bspw.:
Der Code bedient sich altbekannten Mechanismen. Lediglich die Zerlegung des Zeilenstrings ist für manche neu:
Listing 1: Einfacher CSV Reader in C#
Kurze Erklärung der Codezeilen: Die Funktion
ReadAllLines() liest jede Zeile in eine eigenen Arrayposition ein, wodurch jede Zeile als ein eigener String vorliegt. Da wir auch leere Files haben können prüfen wir ob dies der Fall ist,
und stoppen die Funktion wenn es nichts zu verarbeiten gibt. Den String jeder Zeile können wir nun mit der
Split() Funktion wieder in ein Array zerlegen.
Split() erwartet mindestens ein Separierungszeichen (in unserem Fall das Semikolon) und teilt danach alle Elemente zwischen dem Separierungszeichen in ein Array auf(1).
Die erste Zeile des Files wird als Headerzeile interpretiert. Nun können wir in einer Schleife alle Werte auslesen. Da wir davon ausgehen müssen, dass eventuell die Anzahl der Spalten nicht in jeder
Zeile gleich ist, zählen wir den Spaltenzähler immer nur zum kleineren der beiden Längen (Überschrift vs. Daten). Danach geben wir sie aus.
(1) In anderen Programmiersprachen wie bspw. Java erwartet Split einen Regulären Ausdruck. Das ist zwar „komplizierter“, Reguläre Ausdrücke bieten aber mehr Funktionalität. Für das Semikolon genügt jedoch ";"
Grundsätzlich kann man sagen, dass das CSV-Format immer dann eine gute Wahl ist, wenn wir ein geeignetes Separierungszeichen finden, welches nie Teil der Daten sein kann (hier gibt es zwar auch wieder Möglichkeiten,
über Anführungsstriche dies zu umgehen, dann werden die selbstgeschriebenen Parser jedoch ungleich komplizierter). Weiterhin müssen wir 100% sicherstellen können, dass die Anzahl der Spalten in jeder Zeile gleich ist.
In allen anderen Fällen müssten wir „raten“, welche Spalten hinzugekommen oder weggefallen sind, was natürlich nicht tragbar ist. In solchen Fällen bieten sich die beiden anderen Kandidaten für strukturierte Datenhaltung an.
JSON-Format
Beginnen wir mit dem einfacheren von beiden, dem JSON-Format. JSON steht für
„Java Script Object Notation“, was so viel bedeutet, dass man sich an den JavaScript Syntax für Objektdaten orientiert hat. Die Idee ist, dass die Eigenschaften (also nicht die Methoden) eines
JavaScript Objektes geeignet sind, Daten strukturiert abzulegen. Sehen wir uns hierzu nochmal die „klassische“ Definition eines JavaScript Objektes an:
Listing 2: Objektnotation in JavaScript
Bis auf die Funktion
printValue() handelt es sich hierbei um eine reine Datenrepräsentation in Form eines Objektes. Wenn wir also hieraus ein JSON Repräsentation der Daten für ein File machen wollen, dann kümmern wir uns
nur um die Eigenschaften. JavaScript verfügt nun über eine Funktionalität, welche mit einer einzigen Codezeile aus dem Objekt einen String macht. Diese befindet sich in der JSON Klasse
JSON Objekt und nennt sich
stringify(). Der Name ist recht anschaulich – oftmals “hört“ man auch den Begriff „serialize“, da der Vorgang, eine interne Speicherstruktur in einen String zu verwandeln „serialisieren“ heißt. Dies ist
aber nicht 100% korrekt – da wir nur einen Teil des Objektes serialisieren – die Methoden werden ja ignoriert. Wir ergänzen nun unseren Code um folgende Zeile:
Listing 3: Serialisierung eines Objektes in ein JSON Format
Nach der Ausführung sehen wir auf der Konsole:
Dies ist also die JSON Notation für die Daten in unserem Objekt. Formatieren wir es etwas um, damit wir klarer sehen und auch die Parallelen zur Notation aus
Listing 2 erkennen:
Das ganze Objekt wird in geschweiften Klammern notiert. Jeder Feldname wird in Anführungsstrichen aufgeführt, gefolgt von einem Doppelpunkt und dem Wert. Diese Werte können entweder Strings sein –
welche ebenfalls in Anführungsstrichen stehen, Zahlen oder boolean Werte. Wenn es sich um Zahlen handelt, fallen die Anführungsstriche weg. Weiterhin können dort wieder Objekte stehen, welche dann auch
in geschweiften Klammern stehen. Es können aber auch Arrays mit Werten eingetragen werden, für die wiederum das gleiche gilt wie für die Werte der Felder. Prinzipiell können wir somit alle JavaScript
Datenelemente in einen String umwandeln – lediglich eine Ausnahme gibt es. Assoziative Arrays funktionieren nicht, sie würden als leeres Array im String auftauchen. Nun können wir die Verarbeitungsrichtung
auch umdrehen. Wir entwerfen mal ein Array von 2 Objekten in einer JSON Stringnotation, um es dann in ein echtes JavaScript Objekt umzuwandeln:
Wenn wir diese Werte nun in einen JavaScript String platzieren wollen, müssen wir die Anführungsstriche escapen, oder alternativ den String mit einfachen Anführungsstrichen erstellen. Zur Übersicht habe
ich die Stringvariante mit Escapezeichen
(myString1) und mit einfachen Anführungszeichen
(myString2) an-geführt – beide beinhalten das Gleiche.
Listing 4: Parsen von JSON Strings in ein JavaScript Objekt
Kurze Erklärung der Codezeilen: Die Methode hierfür heißt
sinnigerweise
parse(), was genau das ist, was hier passiert – wir parsen einen String. Da wir hier jedoch aus einem String ein Objekt erzeugen, spricht man auch von
„Deserialisieren“ – wobei wir ja nicht wirklich serialisiert haben, da eventuelle Methoden ja rausgeflogen sind. In
myArray findet sich dann ein Array von zwei Objekten, welche jeweils die Eigenschaften
Vorname und
Alter aufweisen. Auf diese können wir zugreifen, als wären die Objekte von uns manuell erstellt worden.
Hier zeigt sich die Flexibilität von Skriptsprachen. In kompilierten Sprachen wäre es unmöglich aus einem dynamisch geparsten String mit einem Punktoperator zuzugreifen,
da der Computer die Struktur ja während des Kompiliervorgangs kennen muss und nicht erst zur Laufzeit! Sehen wir uns mal an, wie wir das gleiche Programm in C# realisieren könnten.
Hier müssen wir erstmal die Objektstruktur festlegen – sprich wir brauchen eine Klasse:
Listing 5: Klassenstruktur für JSON Daten
Nun ist die Struktur festgelegt und wir können das File lesen und parsen:
Listing 6: JSON Parsing in C#
Kurze Erklärung der Codezeilen: Der
JsonSerializer (und die darin enthaltene
Deserialize Funktion) befindet sich unter
System.Text.Json. Das Lesen des Files wiederum ist für uns nichts Neues. Die Deserialisierung erwartet als Typ genau das, was über die
<> Klammern vorgegeben wurde, eine dynamische Liste von
PersonClass daten. Diese werden dann 1:1 über das JSON File übernommen.
Das ist soweit auch nicht umständlicher als in JavaScript. Eine Herausforderung ist es jedoch manchmal, bei komplizierten JSON Strukturen die zu speichernde C# Klasse so aufzubauen, dass sie wirklich für
alle erwartbaren JSON Situationen passt. In solchen Fällen ist es mitunter ratsam, das JSON File in ein DOM (Document Object Model) zu parsen. Die Idee hier ist, dass ein JSON String nur folgende Dinge kennt:
- Eigenschaften als eindeutige Namen und deren Werte
- Objekte, welche wiederum in Eigenschaften zu finden sind
- Arrays von Objekten oder Werten
Die Idee hinter dem DOM ist, dass wir mit Hilfe von einzelnen Schritten die Baumstruktur unseres JSON Strings durchforsten. Sehen wir uns ein Beispiel an, welches das gesamte JSON Objekt von oben ausgibt:
Listing 7: DOM Parsing mit JsonElement Objekten
Kurze Erklärung der Codezeilen: Mit
JsonDocumen.Parse() erzeugen wir das DOM. Da JSON immer eine äußere Klammer benötigt (bei Objekten eine geschweifte und bei Arrays eine eckige), können wir immer das Rootelement – also die äußere Klammer – erwarten.
Von dort aus hangeln wir uns das JSON Konstrukt Element für Element durch. Die einzelnen Werte erhalten wir mit
getProperty(). Sollte ein
JsonElemement ein Array darstellen, können wir es wie ein normales Array behandeln und den Index in eckige Klammern schreiben – lediglich die Arraylänge erhalten wir nicht mit
Length sondern mit
GetArrayLength() - was wiederum darauf hinweist, dass C# nicht wirklich ein Array erzeugt hat, es uns lediglich bezüglich des Zugriffs "vorgaukelt".
Starten wir unser Programm, sehen wir:
Grundsätzlich kann man sagen, dass fast alle Skriptsprachen einem die JSON Verarbeitung einfacher machen als kompilierte Sprachen. JavaScript ist aufgrund der „Blaupause“ für JSON natürlich am besten geeignet.
PHP erledigt mit der Funktion
json_decode() und Python mit
json.loads() die Aufgabe, JSON Strings zu parsen jedoch auch sehr einfach, indem die Daten in ein assoziatives Array Konstrukt geladen werden. Als Beispiel sehen wir uns die PHP Lösung an:
Listing 8: JSON in assoziatives Array einlesen in PHP
Kurze Erklärung der Codezeilen: Wir lesen das File zuerst in eine Variable
$content ein, welche wir mit
json_decode() in ein assoziatives Array umwandeln.
print_r() erzeugt eine Ausgabe, welche die innere Struktur lesbar aufzeigt.
Die Ausgabe lässt die Struktur des assoziativen Arrays erkennen:
Die Rückumwandlung von Objekten in JSON Strings geht in PHP mit
json_encode():
Listing 9: JSON Erzeugung in PHP
Kurze Erklärung der Codezeilen: Für die JSON Codierung benötigen wir die notwendigen Objekte, weshalb die Klassen entsprechend definiert werden müssen. Die
Person und
MyData Klassen beinhalten die zu serialisierenden Informationen. Eventuelle Funktionen würden von
json_encode() ignoriert werden. In
printJson() werden nun die Objekte erzeugt und der JSON String ausgegeben.
Starten wir das Programm, sehen wir auf der Konsole die erwartbare Ausgabe:
Sehen wir uns die Serialisierung von Objekten auch nochmal in C# an. Über die
JsonSerializer Klasse ist die Umwandlung relativ unkompliziert. Ich habe der Einfachheit die Klasse
PersonClass aus
Listing 5 um einen Konstruktor erweitert. Dadurch können wir unsere Liste von Objekten recht einfach erzeugen und anschließend serialisieren:
Listing 10: Serialisieren einer C# Liste von Objekten in einen JSON String
Die Ausgabe beim Aufruf des Codes sollte uns nun nicht mehr überraschen.
Wie wir in C# gesehen haben, müssen kompilierte Sprachen vor allem beim Deserialisieren zwangsweise andere Wege gehen als Skriptsprachen. Das gilt für C# genauso wie für Java oder C++. Mitunter müssen
hier auch externe Bibliotheken geladen werden, in denen Funktionen für JSON hinterlegt sind. Da man hier die Auswahl aus mehreren Möglichkeiten hat, muss man sich zwangsläufig vorab über diese
Bibliotheken informieren und danach entscheiden, welche man verwenden möchte. Hierbei gilt es, die Angepasstheit auf die Problemstellung, welche im zu entwickelnden Programm gelöst werden muss zu beachten,
aber auch Fragen zu den Lizenzbedingungen und ggf. auch Kosten sind zu klären. Im Regelfall gehen die Bibliotheken einen der oben gezeigten Wege – also entweder das Einlesen der Werte in vorbereitete
Klassen oder die Abarbeitung eines DOM.
XML-Format
Die dritte hier besprochene Option für strukturierte Datenablage ist XML (eXtendable Markup Language – also „erweiterbare Auszeichnungssprache“). XML ist mit Sicherheit
komplizierter als JSON, jedoch bietet XML auch einige Features, welche die Stabilität der Software erheblich erhöhen. Aber der Reihe nach. Die Idee von XML ist, dass Daten wieder mit Namen versehen werden
können – ähnlich die Variablennamen im JSON. Diese Namen finden sich in sogenannten „Tags“ (also „Etikett“) wieder. Wenn wir einen Vornamen „Maria“ in ein Tag einbetten, dann sieht dies wie folgt aus:
Die Information besteht also aus drei Teilen. Den Starttag
<Vorname>, den Daten Maria und dem Enddag
</Vorname>. Dieser sieht genauso aus wie der Starttag – er wird lediglich mit einem
Slash („/“) ergänzt. Wir haben ein solches System bereits in
Kapitel 3 kennengelernt. Dort wurde eine HTML Seite besprochen und wie der Name
„HyperText Markup Language“ bereits vermuten lässt, gibt es hier tatsächlich Parallelen. Interessanter Weise ist XML erst nach HTML entstanden, obwohl XML eigentlich eine allgemeinere Form von Markup
Language darstellt. XML verfasst die Regeln zur Erstellung der Tags jedoch strikter, weshalb HTML keine echte Untergruppe von XML ist(2). Aber gehen wir die elementarsten
Regeln für die Erstellung eines XML-Dokuments mal Schritt für Schritt durch.
XHTML wurde als „echte“ Untergruppe von XML definiert, hat sich jedoch nicht durchgesetzt
Regel 1: Jedem öffnenden Tag muss im Laufe des Dokuments ein schließender Tag folgen. Die einzige Ausnahme sind leere Tags:
Regel 2: Die Tags müssen ebenentreu verschachtelt sein.
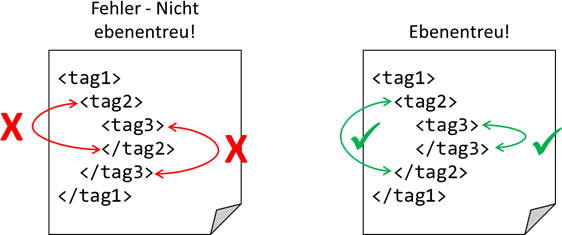
Abb.: 1: Nicht ebenentreu vs. Ebenentreu
Regel 3: Jedes XML-Dokument hat genau ein Rootelement (also ein Tag-Paar, welches das gesamte Dokument einschließt):
Regel 4: Tags können null bis viele Attribute aufweisen. Diese müssen innerhalb des Tags einen eindeutigen Namen aufweisen und werden in den Starttag eingefügt:
Regel 5: Daten werden entweder zwischen dem Start- und Endtag oder als Attributswert eingefügt.
Regel 6: XML ist bezüglich der Tag- und Attributsnamen „Case Sensitive“.
Regel 7: Sonderzeichen, welche für die XML-Definition benötigt werden, müssen escaped werden.
| Zeichen: | Escapesequenz: |
|---|---|
| < | < |
| > | > |
| & | & |
| ' | ' |
| " | " |
Tabelle 1: Escapesequenzen für XML
Alternativ kann auch das
&#, gefolgt vom ASCII Code in Dezimal geschrieben werden. Also anstatt
< geht auch
<
XML-Dokumente, welche diesen Regeln entsprechen, nennt man „wohlgeformt“.
Wir können jegliche Struktur in XML darstellen. Unser Adressbeispiel ist oben dargestellt. Somit haben wir schon mal festgestellt, dass XML flexibel ist. Die eigentliche Erweiterbarkeit,
die im „X“ von XML steckt, ist sehr eng mit der Validierung verknüpft. Es gibt die Möglichkeit, die erwartete Struktur in einem eigenen Dokument zu hinterlegen. Wenn wir also in unserem
Beispiel die Personen-Tags immer innerhalb der Adress-Tags erwarten, können wir dies definieren. Hierzu dienen DTD (Document Type Description) oder
XSD (Xml Schema Definition oder kurz XML-Schema) Files. Letzteres erlaubt auch exaktere Aussagen über das File zu machen, wie bspw. Formatierung der Daten oder die
Reihenfolgen der Tags. Diese Strukturinformationen ergeben also ein Regelwerk, wie XML-Dateien auszusehen haben und genau das ist die Erweiterung des allgemeinen XML Standards. Durch
die Ermöglichung der Validierung können wir nun unseren Code robuster gegenüber fehlerhaften XML-Dokumenten machen, indem wir sie vor der Verarbeitung auf die Einhaltung dieser Regeln
validieren. In der Computerwelt finden wir nun an sehr vielen Stellen XML-Dateien – auch wenn sie auf den ersten Blick nicht
*.xml heißen. SVG Dateien (also Scalabe Vector Graphic) sind nichts anderes als Grafikinformationen in
XML-Form(3). Öffnet man bspw. das
*.svg File des folgenden Smileys:
DTD Definition von SVG Version 1.1: https://www.w3.org/TR/SVG11/svgdtd.html

Abb.: 2: SVG eines Smileys
mit einem Text Editor, ist das linke Auge unter folgendem XML Tag zu finden:
Ein anderes populäres Beispiel ist das offene XML-Format eines Excel Files. Wenn man die Extension eines Excel Files von
*.xslx auf
*.zip ändert, so kann man „in das Excel Dokument“ hineingehen und die einzelnen XML Files, aus denen Excel besteht, öffnen und ansehen. Es ist natürlich sowohl für das SVG und noch
viel mehr für Excel erstmal keine gute Idee, die XML Files mit eigenem Code zu manipulieren, aber es wäre theoretisch möglich.
XML-DOM Parser
Im Rahmen dieses Buches werde ich lediglich zwei gängige Verfahren zum Parsen von XML Files vorstellen. Das erste ist ein alter Bekannter – die Umwandlung des XML in ein DOM, womit wir mit Objekten wieder durch den
XML-Baum durchiterieren können. Das zweite wird er SAX Parser sein, der vor allem in Java eine sehr gute Umsetzung erfahren hat.
Aber beginnen wir mit dem DOM Parser. Um die Parallelen zu JSON zu zeigen, werde ich auch dieses Parsingbeispiel in C# durchführen. C# bietet nun eine ganze Reihe von Optionen(4)
an, XML zu verarbeiten, da Microsoft historisch gesehen sehr auf das XML-Verfahren gesetzt hat. Ich werde für dieses Buch den DOM Parser aus
System.Xml.XmlDocument nutzen. Solche Parser sind für fast alle Programmiersprachen zu finden. Das elementarste Objekt bei dieser API ist vom Typ
XmlNode. Hier sind alle notwendigen Methoden zu finden, um die Informationen aus den einzelnen Tags herauszufiltern, wobei im DOM ein „Tag“ als Node – zu Deutsch „Knoten“ bezeichnet wird. Attribute wiederum
stehen für die Attribute, welche in einem Knoten platziert wurden und das ganze Dokument wird in einem Objekt der Klasse
XmlDocument gespeichert.
(4) Siehe https://docs.microsoft.com/de-de/dotnet/standard/data/xml/xml-processing-options
| Methode: | Funktion: |
|---|---|
| theDocument.FirstChild | Dies ist der Root Tag (bzw. „root Node“) des Dokuments. |
| myNode.Attributes | Gibt eine Liste der Attribute einer Node zurück oder null, wenn keine Attribute vorhanden sind. |
| attr.Name | Der Name eines Attributs (bspw. geschl) |
| attr.Value | Der Wert, welcher in dem Attribut hinterlegt wurde. |
| myNode.ParentNode | Der Elternknoten. Dies ist insofern wichtig, als dass der Text, welcher zwischen öffnenden und schließenden Tag steht, ebenfalls als Node gespeichert wird. Um den Tagnamen zu erhalten, muss man also eine Ebene höher gehen – zum Elternknoten. |
| myNode.HasChildNodes | true, wenn der Knoten Kindelemente hat (was auch für den Textihalt zwischen dem öffnenden und schließenden Tag gilt). |
| myNode | Steht auch für die Sammlung aller Kindknoten, auf die man mit einer foreach Schleife zugreifen kann. |
| myNode.InnerText | Text, welcher zwischen öffnenden und schließenden Tag steht. Dies würde auch die Textdarstellung aller eventuell vorhandenen Kindknoten beinhalten. Insofern wird diese Methode meist nur für Knoten angewendet, welche keine weiteren Kinder, sondern nur Textinformationen beinhalten (wie bspw. der Node „Maria“ in <Vorname>Maria</Vorname>) |
Tabelle 2: Die wichtigsten Methoden zur Abarbeitung eines DOM Objektes in C#
Sehen wir uns den Code an, um die Methoden im Kontext zu verstehen. Ich werde hierbei auf die Prüfung mittels eines XML-Schemas verzichten, da es den Scope dieses Buches sprengen würde.
Wer hier genaueres wissen möchte, sollte sich die sehr umfangreiche Dokumentation von Microsoft zu Gemüte führen.
Listing 11: XML DOM Parser in C#
Kurze Erklärung der Codezeilen: Zuerst wird ein Objekt für die Verarbeitung erstellt und ein XML File eingelesen. Da ein valides XML-Dokument einen Root-Tag enthalten muss, ist auch eine
Root-Node zu erwarten. Diesen geben wir an die eigentliche Verarbeitungsroutine
readChildNodes(). Ich habe diese Routine als rekursive Methode implementiert, da das Durcharbeiten einer Baumstruktur rekursiv am elegantesten zu lösen ist. Jeder Knoten wird gleich behandelt.
Zuerst wird geprüft, ob Attribute vorhanden sind und wenn ja werden diese ausgegeben. Danach prüfen wir auf Kindknoten. Nur die Elemente, welche keine Kindknoten aufweisen (also in unserem oberen
XML-Beispiel wäre das bspw. der Inhaltsknoten innerhalb
<Vorname>), haben einen inneren Text, der wiederum ausgegeben wird. Der zugehörige Tagname ist wie in
Tabelle 2 bereits erwähnt, aus dem Elternknoten zu ermitteln. Sollte der aktuell untersuchte Knoten Kindelemente aufweisen, wird pro Kindknoten diese Methode wieder rekursiv aufgerufen.
Alle XML-DOM Parser gehen im Wesentlichen einen ähnlichen Weg. Dies liegt unter anderem daran, dass das W3C (World Wide Web Consortium) eine Empfehlung für die wichtigsten Funktionen eines XML-DOM Parsers formuliert hat(5).
(5) siehe https://www.w3.org/TR/DOM-Parsing/
XML-SAX Parser
Die hier vorgestellte Parsing Methodik über das DOM birgt nun für einen speziellen Fall ein kleines Problem mit sich. Wenn wir beispielsweise ein recht großes Dokument nach nur einer speziellen Information absuchen wollen,
müssen wir das gesamte Dokument als DOM Struktur in den Speicher laden und durchforsten. Wenn wir also nicht den Speicher mit dem gesamten DOM belegen wollen, müssen wir einen anderen Weg gehen. Hier bietet bspw. Java einen
weiteren Weg, wie man XML parsen kann: den sogenannten SAX Parser. SAX steht für Simple API for XML und verarbeitet das XML-Dokument bereits beim Einlesen. Die Idee ist, dass ein Programm das gesamte File durcharbeitet und
bei jeder Fundstelle eines Tags eine Verarbeitungsmethode aufruft. Er hält zwar meist einen Großteil des Dokuments als String im Speicher, aber nicht als DOM, was unter dem Strich weniger Platz erfordert. Die wichtigsten Methoden hier sind:
| Methode: | Funktion wird aufgerufen, wenn: |
|---|---|
| startDocument() | …der Parsingprozess startet. |
| endDocument() | …der Parsingprozess endet. |
| startElement() | …ein öffnender Tag gefunden wurde. |
| endElement() | …ein schließender Tag gefunden wurde. |
| characters() | …der Parser zwischen den Tags liest. Hier können die Informationen ausgegeben werden, welche zwischen den Tags stehen aber nicht selbst Tags darstellen – also der innere Text. |
Tabelle 3: Wichtige Methoden des Java SAX Parsers
Darüber hinaus gibt es noch Methoden, welche bei Fehlern aufgerufen werden. Da diese Methoden nicht von uns, sondern vom Parser aufgerufen werden, nennt man sie auch Callback Methoden. Die Signaturen
müssen den Vorgaben entsprechen, da sie sonst nicht vom Parser aufrufbar sind. Dies wird in Java dadurch erreicht, dass unsere Parserklasse von einer vorgegebenen Klasse erbt und wir die oben benannten
Methoden überschreiben. Sehen wir uns dies im Code an:
Listing 12: Java SAX Parser
Kurze Erklärung der Codezeilen: Die Klasse erbt von
DefaultHandler. Diese Klasse übernimmt die Verarbeitung und beinhaltet Methoden, welche vom Parser aufgerufen werden können. Wenn wir nun eigenen Code hinterlegen wollen, müssen wir die
entsprechende Methode überschreiben. In der Main Methode bereiten wir den Lesevorgang vor, indem wir eine
SAXParserFactory erzeugen. Diese ist dafür zuständig, den eigentlichen SAX Parser zu erzeugen und ggf. vorher noch einige Einstellungen zu erlauben. Wir benötigen für unser einfaches
Programm jedoch keine weiteren Settings. Nun lassen wir die Factory den eigentlichen Parser erzeugen, der den gesamten Verarbeitungsprozess übernimmt. Der Reader aus dem
SAXParser soll nun das File einlesen, weshalb er wissen muss, wen er bei den einzelnen gefunden Tags aufrufen soll. Dies ist ein Objekt unserer Klasse
XmlSaxParser mit den überschriebenen Methoden aus
Tabelle 3. Nun geben wir die einzelnen Informationen der Callbackmethoden aus. Bei
startDocument() und
endDocument() informieren wir lediglich über den Stand der Verarbeitung. Wenn wir bspw. die Informationen aus dem XML Dokument in ein eigenes Objekt überführen wollen, könnten wir es bei
startDocument() erzeugen. Nun folgt
startElement(). Wir erhalten hier die wichtigsten Informationen über den gefundenen Start-Tag, wie den Namen oder die Attribute. Letztere lesen wir per Schleife aus. Da beim End-Tag keine
Attribute vorliegen, können wir in der Methode
endElement() lediglich den Namen erwarten.
characters() liefert uns die Info über den Text, der innerhalb des Tag-Paares steht. Wenn kein Text vorhanden ist (bspw. wenn nur Kindelemente vorhanden sind wie bei
<Person>, wird hier ein Leersting geliefert. Die eher „kompliziert“ anmutende Parameterliste rührt daher, dass in
ch als
char[] tatsächlich ein Großteil des Textes (bei kleineren Dokumenten der gesamte Text) des XML Dokumentes liegt und mit
start und
length lediglich die Position des Textinhaltes „herausgeschnitten“ wird. Die letzten drei Methoden sind lediglich für das Errorhandling, so dass der SAX Parser die Fehler kontrolliert übergeben kann.
Lassen wir unseren Code mit dem persons.xml Dokument laufen, sehen wir:
Erzeugung von XML-Daten
Gehen wir nun die andere Richtung – die Erzeugung eines XML-Strings aus Klassen heraus. Grundsätzlich ist die manuelle Erzeugung von Strings eine gute Option,
da die XML-Struktur relativ einfach programmatisch zu erzeugen ist. Es existieren aber auch Bibliotheken, welche dies für uns erledigen, wobei diese bei der
Handhabung mitunter Einschränkungen mit sich bringen. Sehen wir uns deshalb die „simplere“ Option an, welche bei allen Programmiersprachen funktioniert – die
Erzeugung der Strings in den eigenen Klassen über eine selbst zu erstellende Methode. Das ist zugegebenermaßen mit mehr Code verbunden als mit fertigen Bibliotheken
– es zeigt aber die Idee hinter XML-Serialisierern und gibt uns die Freiheit das XML-Dokument komplett selbst zu kontrollieren. Zuerst ist es sinnvoll, für die
Erzeugung von XML-Strings ein Interface zu erstellen. Das macht die Handhabung transparenter. Hier wird lediglich eine Methode definiert, welche den XML-String später zurückliefern soll:
Listing 13: Interfacedefinition für XML-Erzeugung
Nun können wir unsere Personen-Klasse so ergänzen, dass sie die
getXmlString() Methode implementiert und genau den String zurückgibt, welchen wir pro Person haben möchten:
Listing 14: Erweiterung der Personenklasse um XML Erzeugung
Der Code ist so weit selbsterklärend. Nun fehlt die Klasse für das gesamte Adressbuch:
Listing 15: Adressbuchklasse mit XML-Erzeugung
Kurze Erklärung der Codezeilen: Die Klasse birgt nichts Besonderes. Lediglich in der
getXmlString() Methode verlassen wir uns darauf, dass die Objekte der Klasse
PersonClass das Interface
XmlExtractable implementiert haben, was aber durch das Interface garantiert wird.
Nun können wir ein Objekt erzeugen und unsere beiden Adresseinträge hinterlegen:
Listing 16: Erzeugung eines Objektes und Umwandlung in einen XML String
Die Ausgabe ergibt wieder unseren XML String, den wir weiter oben bereits definiert haben. Da wir keine Zeilenumbrüche vorgesehen haben, ist der String komplett in einer Zeile:
Wenn man prüfen möchte, ob das erzeugte XML „wohlgeformt“ ist, kann man ihn auch in ein
*.xml File verbannen und mit einem beliebigen Browser öffnen – hier am Beispiel von FireFox:
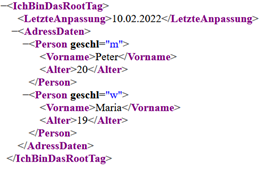
Abb.: 3: XML-Darstellung von FireFox
C# würde nun auch unter
System.Xml.Serialization den
XmlSerializer anbieten, wobei dieser gerade bei tieferen Hierarchien – wie bspw. bei unserer Liste – im Handling komplizierter werden. Wie immer, muss man bei „fertigen“ Klassen sich in das
Manual einarbeiten. Das ist am Anfang zwar oft mühsam, zahlt sich aber mitunter bei größeren Projekten aus.

CC Lizenz (BY NC SA)