
Unterprogramme - divide and conquer
Es ist endlich mal Zeit, über das am häufigsten geschriebene Programm zu sprechen – „Hello World!“. Das Programm
geht auf Brian Kerninghan,
einer der beiden Autoren des wahrscheinlich bekanntesten C Programmierbuches zurück, der mit diesem Code das
einfachste denkbare Programm mit einem Feedback an den Nutzer publizierte. Es zeigt bei Start lediglich den Text
„Hello World!“ auf dem Bildschirm an. Wer dieses Programm geschrieben und kompiliert hat weiß, dass seine Umgebung
korrekt aufgesetzt wurde und hat einen guten Startpunkt für alle weiteren Schritte in dieser Programmiersprache.
Die allermeisten Programmierbücher haben diese Tradition aufgenommen und ich will an dieser Stelle auch kein
Spielverderber sein. Da ich mich in diesem Buch aber nicht auf eine Programmiersprache festlegen will (oder kann),
gebe ich das Programm für die bis hierhin am öftesten rezitierten Programmiersprachen Java, C#, C++ und C an.
In Kapitel XX habe ich das Aufsetzen der VSCode Umgebung für
alle in diesem Buch relevanten Programmiersprachen im Zusammenhang mit dem Hello World Programm beschrieben.
Doch vorher müssen wir einen wichtigen Punkt klären, der für alle Programmiersprachen gilt: jedes Programm muss gestartet
werden können. So primitiv das nun klingt, so wichtig sind die Implikationen. Gehen wir mal davon aus, wir haben ein
Programm mit tausenden von Codezeilen geschrieben. Unser Computer – egal ob als virtuelle oder als reale Maschine –
muss nun wissen, wo er anfangen soll das Programm abzuarbeiten. Wir können ihm das im Code aber nicht mitteilen,
weil die Mitteilung wieder ein Teil des Programms wäre und sich die Katze somit in den Schwanz beißen würde. Also
gibt es in jeder (kompilierten) Programmiersprache ein Standardkonstrukt, welches in allen Programmen gleich ist.
Sozusagen die „Eingangstüre“ in unser Programm. Wenn ein Programm diese definierte Eingangstüre nicht hat, dann
kann es auch nicht ausgeführt werden – der Computer weiß schlichtweg nicht, wo er anfangen soll. Diese „Eingangstüren“
nennen wir üblicherweise „Main Methoden“ oder „Main Programme“.

Main
Wenn wir nun wissen, wie in unserer Programmiersprache das „Main Programm“ aussieht, müssen wir nur noch wissen wie eine
Konsolenausgabe erzeugt wird und schon können wir unser „Hello World!“ Programm schreiben. Sehen wir uns das mal in C an:
Listing 1: Hello World in C
Kurze Erklärung der Codezeilen: Der Code beginnt mit der Einbindung der Bibliothek
„stdio.h“. Unter einer Bibliothek verstehen wir fertige Funktionalitäten, welche wir in unserem Code nutzen möchten,
ohne sie selbst schreiben zu müssen. Die grundlegendsten C Funktionalitäten, wie bspw.
„printf()“ befinden sich in der
stdio.h Bibliothek. Die Main Funktion ist – wie der Name schon sagt
main(). Vor
main() finden wir aber noch einen
int Datentyp. Dieser stellt den „Rückgabewert“ der Funktion dar. Es ist in C üblich, dass wenn das Programm erfolgreich
gelaufen ist, das Programm den Code „0“ an das Betriebssystem „zurückgibt“, wodurch der Aufrufer weiß, dass alles
korrekt verlaufen ist. Andere Zahlen würde man als „Fehlercode“ interpretieren und in der Programmdokumentation
nachsehen, was dieser Code bedeuten würde. Es ist zwar möglich, andere Datentypen anstatt int einzutragen – es ist
aber nicht üblich. In den geschweiften Klammern steht der Rumpf der Main Funktion. Der Computer arbeitet nun Befehl
für Befehl im Rumpf ab. Bei uns ist dies „nur“ die Ausgabe „Hello World!“ auf der Konsole. Das letzte, was in der Main
Funktion steht ist der Rückgabewert nach dem Schlüsselwort
„return“. Da wir keine Fehlersituation erwarten, geben wir hier einfach die „0“ zurück.
Wenn wir dieses Programm kompilieren und starten, sehen wir auf der Konsole folgende Ausgabe:
Innerhalb integrierten Entwicklungsumgebungen gibt uns die Konsole meist noch Zusatzinformationen aus. In VS Code
finden wir beispielsweise das Compilerkommando oder den Exit Code:
Schwenken wir nun um auf C++. Da C++ eine C Erweiterung ist, würde der Code aus
Listing 1 eins zu eins auch vom
C++ Compiler verarbeitet werden. Sehen wir uns aber mal die objektorientierte Lösung des Programms in C++ an:
Listing 2: Hello World in C++
Kurze Erklärung der Codezeilen: Die Bibliotheken (meist als Klassendefinitionen) von C++ liegen in einer anderen
Form vor, weshalb sich der
#include Befehl für eine Klassenbibliothekseinbindung auch etwas ändert. Wir benötigen die Klassenbibliothek
iostream, da wir die Ausgabe nun nicht mehr über die C Funktion
printf(), sondern über
std::cout realisieren.
Die Ausgabe ist wie zu erwarten „Hello World!“. Als nächstes auf unserer Liste haben wir C#. Wir finden hier ein paar
„Neuerungen“, welche vermutlich ursprünglich von Java inspiriert wurden und dem Programmierer das Leben mitunter
leichter machen.
Listing 3: Hello World in C#
Kurze Erklärung der Codezeilen: Die Einbindung der Bibliotheken erfolgt hier über
using. Die Konsolenklasse
Console befindet sich unter
System. Da sich in objektorientierten Programmen wie C# oder auch Java alles in Klassen befindet, müssen wir nun
unsere Klasse mit
class definieren und nennen sie gleich „HelloWorld“. Nun folgt innerhalb der Klasse die
Main Methode. Das Schlüsselwort
void bedeutet, dass diese Methode nichts zurückgibt
(void steht immer für „kein Datentyp“). Es ist prinzipiell möglich, hier auch einen echten Datentyp einzutragen,
was aber eigentlich nicht üblich ist, da die Returncodes von den Aufrufern im Regelfall nicht ausgewertet werden.
Nun kommt etwas Neues für uns – und zwar steht nun eine Arraydeklaration in Klammern. Der Sinn dieses sogenannten
„Parameter Arrays“ ist, dass wenn jemand beim Aufruf unseres Programms einen Aufrufparameter mitgeben möchte, dieser
in dem Array landet. Wenn wir bspw. in der Konsole
„HelloWorld.exe param1 param2“ eingeben, so finden wir im
args Array auf Position 0 den
String „param1“ und auf Position 1 „param2“. Danach folgt die inzwischen altbekannte Ausgabe von Strings in C#.
„return“ benötigen wir nicht, da wir ja
„void“ als Rückgabetyp haben.
Last but not least sehen wir uns das Gleiche in Java an:
Listing 4: Hello World in Java
Kurze Erklärung der Codezeilen: Zuerst sehen wir, dass wir in Java für die grundlegenden Funktionalitäten keine
Bibliothek einbinden müssen. Wir werden später noch sehen, dass weiterführende Funktionalitäten mit
„import“ eingebunden werden. Die
main Methode sieht nun sehr ähnlich zu C# aus. Wichtig hier ist allerdings, dass die Java
main Methode nur
void als Rückgabetyp akzeptiert – sie gibt also nie etwas zurück. Tauschen wir
„void“ mit
„int“ würde das Programm nicht starten, da die virtuelle Maschine die
main Methode nicht als solches erkennen bzw. akzeptieren würde. Die Übergabemechanik in Java ist wiederum identisch
mit der von C# (bzw. eigentlich umgekehrt).
Die Frage ist mit Hinblick auf die
args Parameterlisten in C# und Java nun, kann man in C/C++ keine Programme mit Übergabeparametern schreiben?
Die Antwort ist – doch. C ist vom Handling aber mal wieder etwas „umständlicher“, was wieder mal daran liegt,
dass das Array nicht als Objekt mit Eigenschaften vorliegen kann. Sehen wir uns folgenden Code an:
Listing 5: Verarbeitung Übergabeparmeter in C
Kurze Erklärung der Codezeilen: In C (und C++) sind also die Übergabeparameter „optional“ – im Gegensatz zu C# und
Java, wo das
„args“ Array immer eingetragen werden muss. Wenn wir in C die Parameter verarbeiten wollen, müssen wir nun zwei
Dinge wissen – die Parameter als solches, welche im
char* Array (also einem Array, welches auf Zeichenketten zeigt) und, da das Array ja kein Objekt ist und somit
keine Längeneigenschaft besitzt, die Länge des Arrays, was in unserem Code in der Variablen
„arglength“ zu finden ist. Wir geben nun mal testweise die Länge des Arrays und die ersten beiden Einträge aus.
Wenn wir den Code kompilieren und über die Konsole mit zwei Parameter aufrufen:
erhalten wir erstmal etwas überraschendes:
Unser Array hat 3 Einträge, obwohl wir „nur“ zwei Parameter übergeben haben. Dies liegt daran, dass immer ein
Parameter existiert, nämlich der Name des Programms. Das macht C automatisch. Ob wir diese nun abgreifen – sprich
ob wir in den runden Klammern der Main Funktion die beiden Parameter für die Arraygröße und den Arrayinhalt vorsehen
oder nicht, bleibt uns überlassen. In C# und Java dürfen wir den Parameter zwar nicht weglassen – sprich es muss
immer das
args Array vorhanden sein, wir können den Inhalt aber ignorieren, wenn wir keinen Wert auf Aufrufparameter legen.
Funktionen, Prozeduren, Methoden
Es gibt aber nicht nur das Main Programm – oder Hauptprogramm – sondern auch Unterprogramme. Dieses Konzept ist nun für einen
übersichtlichen Programmierstil entscheidend. Insofern müssen wir über die wichtigsten Merkmale von solchen Unterprogrammen
reden. Beginnen wir aber erstmal mit den Begrifflichkeiten, welche gerne mal durcheinandergewürfelt werden. Unter „Programm“
verstehen wir primär das Gesamtprogramm, welches gegenüber dem User als ein „Ding“ auftritt, welches er ausführen kann und
welches eine klar umrissene Aufgabe des Rechners erledigt. Unter Software versteht man im Allgemeinen eine größere Sammlung
an Programmen, welche für einen gewissen Aufgabenkomplex des Users ausgelegt ist. Hierzu gehört mitunter auch die Dokumentation
der Software. Zwischen Software und Programm wird aber oftmals nicht sauber unterschieden, was aber auch kein großes Problem
darstellt.
Spannender ist da die Unterscheidung von Prozedur, Funktion und Methode. Hier handelt es sich um Teilmengen von Programmen –
man spricht auch von „Unterprogrammen“. Dort lagert man kleinere Funktionalitäten aus, um den Code effektiver und lesbarer
zu gestalten. Unter einer Prozedur versteht man eine Funktionalität, welche keinen Rückgabewert besitzt, wogegen eine Funktion
einen Rückgabewert aufweist. Methoden sind Funktionen oder Prozeduren, welche im Rahmen der objektorientierten Programmierung
in Klassen hinterlegt wurden und somit Objekten zu eigen sind.
| Bezeichnung: | Bedeutung: | Beispiel: |
|---|---|---|
| Software | Sammlung an Programmen und Dokumentation zur Lösung eines Aufgabenkomplexes für den User. | Microsoft Office |
| Programm | Programm, welches eine einzelne Aufgabe des Computers löst. | Ping.exe |
| Prozedur | Unterprogramm, welches keinen Rückgabewert besitzt. | printf() |
| Funktion | Unterprogramm, welches einen Rückgabewert besitzt. | getDatum() |
| Methode | Prozedur oder Funktion eines Objekts. | myName.toUpperCase() |
Tabelle 1: Begrifflichkeiten von Software(sub)strukturen
Da wir uns in diesem Kapitel um „Unterprogramme“ kümmern wollen, gehen wir hier auf Prozeduren und Funktionen
ein – und somit bei den objektorientierten Programmiersprachen implizit auch auf die Methoden.
Prinzipiell haben Unterprogramme drei Eigenschaften. Den Namen, die Parameterliste und den Rückgabetyp. Sehen wir
uns hierfür mal folgendes Programm an:
Listing 6: Einfache Funktion in C
Kurze Erklärung der Codezeilen: Das Unterprogramm
add() hat zwei Parameter vom Typ
int und einen Rückgabewert vom Typ
int, wodurch es zur Funktion wird. Intern werden die beiden Werte addiert und das Ergebnis an den Aufrufer
zurückgegeben. Der Aufruf wiederum ist relativ logisch konstruiert – wir übergeben die beiden Werte und weisen den
Rückgabewert mit
„=“ der Variablen
i zu, die wir anschließend ausgeben. Wichtig in C ist, dass die einzelnen Unterprogramme vor der Nutzung bekannt
gemacht werden müssen. Würden wir
main() und
add() vertauschen, kompiliert das Programm nicht, bzw. nur mit Warnings.
An dieser Stelle noch ein kleiner konzeptioneller Hinweis, um die Vokabeln „prefix“ und „infix“ anzusprechen: die Operation „+“ des Ausdruckes a + b ist streng genommen auch schon ein kleines Unterprogramm mit dem Unterschied, dass die eigentliche Funktionalität zwischen den beiden Operatoren liegt. Man spricht hier von einer „infix Notation“. Durch die Kapselung in eine Funktion add(a,b) machen wir hieraus eine prefix Notation, da die Identifikation der Funktion (also das „add“) vor den Operatoren a und b liegt.
An dieser Stelle noch ein kleiner konzeptioneller Hinweis, um die Vokabeln „prefix“ und „infix“ anzusprechen: die Operation „+“ des Ausdruckes a + b ist streng genommen auch schon ein kleines Unterprogramm mit dem Unterschied, dass die eigentliche Funktionalität zwischen den beiden Operatoren liegt. Man spricht hier von einer „infix Notation“. Durch die Kapselung in eine Funktion add(a,b) machen wir hieraus eine prefix Notation, da die Identifikation der Funktion (also das „add“) vor den Operatoren a und b liegt.
Die erste Frage die uns hier in den Sinn kommen sollte ist, wie schafft man es, die einzelnen Funktionalitäten in
der richtigen Reihenfolge zu entwickeln? Wenn die
main() Methode immer als letztes stehen muss, wäre dies eine ziemliche Einschränkung unserer Arbeit! C hat hierfür
die „Headerfiles“, welche mit
„.h“ enden. Dort schreibt man nur die Namen der Unterprogramme samt Rückgabewert und Parameterliste hinein, so dass der
Compiler weiß, dass die einzelnen Funktionen und Prozeduren korrekt aufgerufen werden. Wo dann die eigentliche
Implementierung stattfindet, ist dann nicht mehr wichtig. Das eigentliche Zusammenfügen erledigt in C dann der
„Linker“, der in den meisten Compilern automatisch aufgerufen wird. Dies erklärt auch, dass in den
„includes“ die
„.h“ Files stehen, wie bspw.
„stdio.h“. Für uns reicht es aber an dieser Stelle erstmal, einfach auf die Reihenfolge zu achten, ohne die Definitionen der
Programme vorab bekannt zu machen.
Es ist nun wichtig zu verstehen, wie die Abarbeitung von diesem Programm erfolgt. Zuerst startet die „Main Funktion“.
In der ersten Zeile wird die Variable
i als
int deklariert. Danach erfolgt der Aufruf von
„add()“ mit der Belegung 3 und 20 für die beiden Parameter. Dadurch springt der Computer in das Unterprogramm
„add(int a, int b)“, deklariert die beiden int Variablen
a und
b und belegt anschließend
a mit 3 und b mit 20. Danach werden
a und
b addiert und das Ergebnis mit
„return“ an den Aufrufer zurückgegeben. Dadurch springt der Computer wieder zurück in das
main Programm und schreibt das Ergebnis der Addition in die Variable
i. Anschließend wird das Ergebnis ausgegeben und das Programm mit
„return 0“ beendet. Somit ist die Ausgabe „Ergebnis = 23“. Durch den Aufruf
„add(3, 20)“ passieren also zwei Dinge. Erstens wird die Funktion
„add()“ mit zwei Parametern gesucht (und natürlich ausgeführt) und zweitens werden die beiden Parameter
„a“ und
„b“ mit den Werten 3 und 20 belegt. Sehen wir uns das gleiche mal in C# an:
Listing 7: Einfache Methode in C#
Kurze Erklärung der Codezeilen: Prinzipiell gibt es hier nichts Neues im Vergleich zu den bisherigen Listings,
außer dass der Wert von
i mit Hilfe eines
+ Zeichens an den String
"Ergebnis = " angehängt wird – es handelt sich also nicht um eine Addition, sondern um eine Verkettung (was wir in
Kapitel 7 bereits gesehen haben). Wichtig jedoch ist, dass in den objektorientierten Programmiersprachen die
Reihenfolge der Methodendefinition keine Rolle spielt. Der Compiler analysiert zuerst den gesamten Code und versucht
danach die richtigen Methoden zu finden. Die finale Entscheidung, welcher Code am Ende ausgeführt wird erfolgt
ohnehin erst bei Ausführung des Programms.
Überladen
Nun ergänzen wir unser Programm um eine weitere Methode, welche drei Werte addiert und nennen diese Methode auch
wieder
„add“. Diese schreiben wir direkt unter unsere existierende
„add()“ Methode:
Listing 8: Methodenüberladung in C#
Wenn wir unser Programm ausführen, sehen wir:
Der Computer findet also jeweils die richtige Methode, je nachdem, welche Parameterliste existiert. Dieses Konstrukt
nennen wir „überladene Methoden“. Wenn der Name gleich ist, die Parameter sich aber unterscheiden, dann hat der
Computer eben die Möglichkeit, die richtige Methode über die Parameterliste zu finden. Dieses Verhalten der
Identifikation von Unterprogrammen geht jedoch in C nicht. C unterstützt keine Überladung! Das hätte man bei der
main Funktion bereits erahnen können, da der Rechner die
main Funktion ohne und mit Parameter gleichbehandelt hat. Grundsätzlich ist das Konzept der Überladung aber sehr
praktisch, da man mit dem Namen die Funktionalität beschreiben möchte – was in unserem Fall für das Addieren von
zwei und auch von drei Zahlen eben der Begriff
„add“ ist. Man spricht in der Programmierung auch von „Signaturen“ der Methoden – womit man die Identifizierbarkeit
meint. In den meisten (objektorientierten) Fällen beinhaltet die Signatur somit den Namen und die Parameterliste.
Hier ist aber noch ein Detail wichtig. Die Parameterliste wird aus Sicht des Computers einzig und allein durch die
Anzahl, Reihenfolge und Datentypen der Parameter bestimmt, nicht durch den Namen. Das ist insofern schlüssig,
als dass der Aufrufer den internen Namen der Parameter gar nicht wissen muss und teilweise nicht wissen kann.
Folgender Code soll das Prinzip der Identifikation über die Reihenfolge nochmals klarstellen:
Listing 9: Methodenüberladung in C#
Kurze Erklärung der Codezeilen: Wir haben nun zwei Methoden (ohne Rückgabewert) realisiert, welche zwar die gleichen
Parameter besitzen, aber in einer unterschiedlichen Reihenfolge. Wenn wir nun
gebeUserAus("Hans", 20) aufrufen, so wird die erste Methode ausgeführt, da hier zuerst ein
String, dann ein
int erwartet wird. Wenn wir die beiden Aufrufparameter umdrehen, so wird die zweite ausgeführt.
Die Ausgabe ist somit erwartbar:
Das Verhalten von Java ist wieder wie das von C# - der Code kann wieder bis auf die Ausgabe 1:1 übernommen werden.
Zum Schluss noch ein kleiner Hinweis. Obwohl das Konzept der Überladung sehr praktisch ist, finden wir es bei den von uns betrachteten Programmiersprachen nur bei Java, C# und C++. Vor allem bei den „moderneren“
Sprachen wir Python, JavaScript oder auch PHP ist dieses Konzept nicht vorgesehen. Dies liegt bei diesen Sprachen primär daran, dass sie auch Paradigmen der funktionalen Programmierung unterstützen –
so z.B. das Ablegen einer Funktion in einer Variablen. Dies werden wir uns im entsprechenden Kapitel zur funktionalen Programmierung aber nochmal etwas näher ansehen.
Übergabeverhalten
Was uns für das Verständnis von Unterprogrammen fehlt ist, wie die Werte eigentlich übergeben werden. Hier beginne
ich erstmal mit den Ansätzen von C# bzw. Java. Wir haben bei den Datentypen ja gesehen, dass wir in C# und Java die
Variablen in zwei Gruppen trennen können – die primitiven Datentypen und die Klassen bzw. Objekte. Bei den primitiven
Datentypen zeigt die Variable auf genau den Speicherplatz, auf dem auch der Wert liegt. Bei Objekten zeigt die Variable
genau auf den Speicherplatz, auf dem die Adresse des zu referenzierenden Objektes zu finden ist
(siehe Kapitel 7 für den Fall eines Arrays).
Sehen wir uns nun folgenden Code mit diesem Hintergrundwissen an:
Listing 10: Übergabeverhalten in Java
Kurze Erklärung der Codezeilen: Wir erzeugen uns zwei verschiedene Variablen. Einmal eine
int Variable (also primitiver Datentyp) und initialisieren sie mit 0. Danach erzeugen wir eine Variable vom Typ
int[] Array (also Objekt) und schreiben gleich auf Indexposition 0 auch die 0. Zugegebenermaßen ist ein
int[] Array mit nur einem Wert sinnlos – aber wir wollen hier nur das Übergabeprinzip verstehen. Nun rufen wir die
beiden
incValue() Methoden auf – eine für den Übergabeparameter
int und eine für
int[]. In den Methoden erhöhen wir die Werte jeweils um eins (das ist der
„++“ Operator) und geben gleich im Anschluss die Werte aus. Wenn die Unterprogramme jeweils abgearbeitet wurden,
springt der Computer wieder in die
main Methode und führt schließlich die Ausgaben der beiden Variablen aus. Wir geben also die Variablen innerhalb
der Unterprogramme (Ref 1 und Ref 2) und außerhalb der Unterprogramme (Ref 3 und Ref 4) aus.
Wenn wir das Programm ausführen, sehen wir folgende Ausgaben:
Was ist hier nun passiert? Die Ausgaben von Ref 1 und Ref 2 sollten klar sein. Wir erhalten jeweils die Werte 0 über
iVar und
iArVar, erhöhen sie auf 1 und geben den Wert aus. In der
main Methode ist nun die Frage, wurde der Variableninhalt hier auch verändert oder nicht? Und wie wir sehen, ist der
Inhalt der Variablen
„iVar“ im Hauptprogramm nicht verändert, der Wert von
„iArVar“ sehr wohl. Wie passt das nun zusammen? Nun, die beiden Variablen beinhalten ja unterschiedliche Informationen.
„iVar“ als primitiver Datentyp enthält den Wert 0 und
„iArVar“ als Objekt die Adresse des Arrays:

Abb.: 1: Speicherbelegung primitiver Datentyp vs. Array in Java und C#
In den Unterprogrammen haben wir über die Parameterliste zwei weitere Variablen deklariert – die
iVarPar und
iArVarPar heißen (wir hätten sie aber auch genauso gut
iVar und
iArVar nennen können). Wenn wir nun
incValue() mit dem
int Parameter
iVar aufrufen, wird der Wert (in unserem Fall 0) als Kopie in die Variable
iVarPar übergeben. Beide Variablen existieren somit im Speicher und weisen den gleichen Wert aus. Wenn wir nun
iVarPar um eins erhöhen, dann weist
iVar die 0 und
iVarPar die 1 auf.
Nun gehen wir das Ganze für iArVar durch. Hier wird die Methode für den int[] Array Parameter aufgeruen und der Inhalt von iArVar wird auch in die Parametervariable iArVarPar kopiert. Dies ist aber nicht der Wert 0, sondern die Adresse des Arrays! Wir haben also wieder zwei Variablen – auch mit gleichem Inhalt, nur der ist nun eben jetzt zweimal die Adresse, welche auf das eine Array zeigen. Nun erhöhen wir im zweiten „incValue“ Unterprogramm den Inhalt des Arrays um 1. Wenn wir in der main Methode wieder den Inhalt der beiden Variablen iVar und iArVar ausgeben, so finden wir auf dem Bildschirm die 0 für iVar, da diese ja nie erhöht wurde. Und wir finden die 1 aus dem Array, da wir das Array ja im Unterprogramm von 0 auf 1 erhöht haben.
Nun gehen wir das Ganze für iArVar durch. Hier wird die Methode für den int[] Array Parameter aufgeruen und der Inhalt von iArVar wird auch in die Parametervariable iArVarPar kopiert. Dies ist aber nicht der Wert 0, sondern die Adresse des Arrays! Wir haben also wieder zwei Variablen – auch mit gleichem Inhalt, nur der ist nun eben jetzt zweimal die Adresse, welche auf das eine Array zeigen. Nun erhöhen wir im zweiten „incValue“ Unterprogramm den Inhalt des Arrays um 1. Wenn wir in der main Methode wieder den Inhalt der beiden Variablen iVar und iArVar ausgeben, so finden wir auf dem Bildschirm die 0 für iVar, da diese ja nie erhöht wurde. Und wir finden die 1 aus dem Array, da wir das Array ja im Unterprogramm von 0 auf 1 erhöht haben.
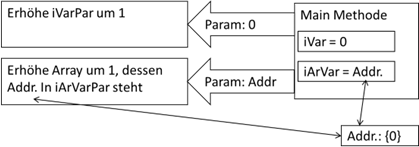
Abb.: 2: Verweise auf Inhalte in Unterprogrammen
Also, obwohl beide Unterprogramme eine Kopie vom Inhalt der übergebenen Variablen anfertigen, ist das Ergebnis
unterschiedlich. Wie sieht das Ganze nun in C aus? Leider nicht übersichtlicher, im Gegenteil. Dem „Puristen“
dürfte der C Ansatz aber deutlich besser gefallen – aber das muss mal wieder jeder für sich selbst entscheiden.
Sehen wir uns folgenden Code an:
Listing 11: Call by Reference und Call by Value in C
Kurze Erklärung der Codezeilen: Wir haben wieder zwei
inc Unterprogramme – diesmal mit unterschiedlichen Namen, da C ja keine Überladungen unterstützt. Der einzige
Unterschied zwischen diesen beiden Prozeduren ist, dass
incByValue das
„i“ in der Parameterliste als Wert erwartet und in
incByRef als Zeiger. In der
main Funtkion wiederum rufen wir
incByValue mit dem Parameter
„a“ auf, was einer Kopie des Wertes gleichkommt und
incByRef übergeben wir die Adresse der Variablen
„b“, was eine Kopie der Adresse darstellt. Das heißt, wir haben wieder die Gleiche Situation geschaffen, wie in
Listing 10, nur eben mit den Mitteln von Zeigern.
Die Ausgabe ist entsprechend wie in unserem Java Programm:
In C spricht man hier von „Call by Value”, wenn wir eine Variable als Wert übergeben. Dadurch wird also der
Variablenwert kopiert und übergeben. Bei „Call by Reference“ wird nicht mehr der Wert übergeben, sondern die
Adresse – es wird die eigentliche Adresse nur referenziert. Die Frage ist, bezeichnen wir jetzt das Verhalten von
Java (und C#) bei der Arrayübergabe als „Call by Reference“ oder „Call by Value“? Die Antwort mag jetzt manchen
überraschen, aber es ist tatsächlich „Call by Value“, auch wenn das Verhalten eher wie „Call by Reference“ aussieht.
Der Grund liegt darin, dass der Inhalt der Variablen entscheidend für diese Kategorisierung ist und der Inhalt ist nun
mal die Adresse. Es wird also eine Kopie des Wertes der Adresse übergeben – sprich „Call by Value“. Das mag dem
C-Puristen nun zu kurz gesprungen erscheinen, aber es gibt in Java keine Wahl der Übergabe und schon gar keine
Adressarithmetik mehr (genauso wenig wie in C#). Dies führt jedoch zu sehr viel saubereren Code. Es gibt zwar durchaus
die Möglichkeit, in C# oder Java doch wieder mit Adressarithmetik zu arbeiten – diese eher „versteckten“ Klassen bzw.
Schlüsselwörter tragen aber so vielsagende Namen wie „Unsafe“, womit die Warnung der Java und C# Macher verbunden ist,
das Ganze mit extremer Vorsicht zu genießen.
Es müsste jetzt sinnvollerweise über eine spezielle Art der Funktionsnutzung gesprochen werden, welche für manche
Problemstellungen eine sehr elegante Lösungsstrategie darstellt – der rekursive Aufruf. Doch bevor wir uns um diese Form von
Programmierung kümmern, müssen wir uns um die Speicherorganisation von unseren Programmen kümmern.

CC Lizenz (BY NC SA)